
java中的序列化
序列化
物件序列化的目標是將物件儲存到磁碟中,或者允許在網路中直接傳輸物件。物件序列化機制允許把記憶體中的JAVA物件轉換成跟平臺無關的二進位制流,從而允許將這種二進位制流持久地儲存在磁碟上,通過網路將這種二進位制流傳輸到另一個網路節點,其他程式一旦獲得了這種二進位制流,都可以講二進位制流恢復成原來的JAVA物件。
序列化為何存在
我們知道當虛擬機器停止執行之後,記憶體中的物件就會消失;另外一種情況就是JAVA物件要在網路中傳輸,如RMI過程中的引數和返回值。這兩種情況都必須要將物件轉換成位元組流,而從用於儲存到磁碟空間中或者能在網路中傳輸。
由於RMI是JAVA EE技術的基礎---所有分散式應用都需要跨平臺、跨網路。因此序列化是JAVA EE的基礎,通常建議,程式建立的每個JavaBean類都可以序列化。
如何序列化
如果要讓每個物件支援序列化機制,必須讓它的類是可序列化的,則該類必須實現如下兩個介面之一:
1、Serializable
2、Extmalizable
這裡有幾個原則,我們一起來看下:
1、Serializable是一個標示性介面,介面中沒有定義任何的方法或欄位,僅用於標示可序列化的語義。
2、靜態變數和成員方法不可序列化。
3、一個類要能被序列化,該類中的所有引用物件也必須是可以被序列化的。否則整個序列化操作將會失敗,並且會丟擲一個NotSerializableException,除非我們將不可序列化的引用標記為transient。
4、宣告成transient的變數不被序列化工具儲存,同樣,static變數也不被儲存。
一、先來看下將一個物件序列化之後儲存到檔案中:

public class Person implements Serializable
{
int age;
String address;
double height;
public Person(int age, String address, double height)
{
this.age = age;
this.address = address;
this.height = height;
}
}
public class SerializableTest
{
public static void main(String[] args) throws IOException, IOException
{
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(
"d:/data.txt"));
Person p = new Person(25,"China",180);
oos.writeObject(p);
oos.close();
}
}
執行結果:

1、物件序列化之後,寫入的是一個二進位制檔案,所有開啟亂碼是正常現象,不過透過亂碼我們還是可以看到檔案中儲存的就是我們建立的那個物件那個。
2、Person物件實現了Serializable介面,這個介面沒有任何方法需要被實現,只是一個標記介面,表示這個類的物件可以被序列化。

3、在該程式中,我們是呼叫ObjectOutputStream物件的writeObject()方法輸出可序列化物件的。該物件還提供了輸出基本型別的方法。
二、接下來我們來看下從檔案中反序列化物件的過程:
按 Ctrl+C 複製程式碼
按 Ctrl+C 複製程式碼
執行結果:
age=25;address=China;height=180.0
1、從第12行開始就是反序列化的過程。其中輸入流用到的是ObjectInputStream,與前面的ObjectOutputStream相對應。
2、在呼叫readObject()方法的時候,有一個強轉的動作。所以在反序列化時,要提供java物件所屬類的class檔案。
3、如果使用序列化機制向檔案中寫入了多個物件,在反序列化時,需要按實際寫入的順序讀取。
物件引用的序列化
1、上面介紹物件的成員變數都是基本資料型別,如果物件的成員變數是引用型別,會有什麼不同嗎?
這個引用型別的成員變數必須也是可序列化的,否則擁有該型別成員變數的類的物件不可序列化。
2、在引用物件這個地方,會出現一種特殊的情況。例如,有兩個Teacher物件,它們的Student例項變數都引用了同一個Person物件,而且該Person物件還有一個引用變數引用它。如下圖所示:
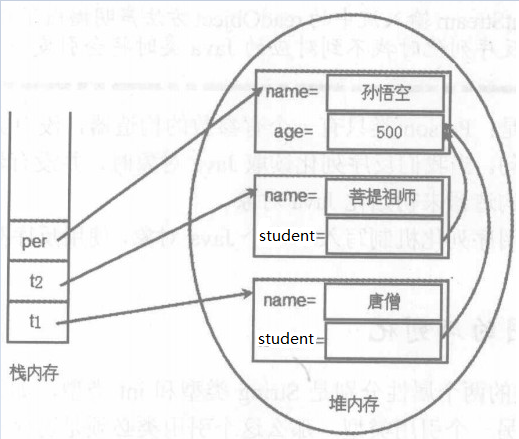
這裡有三個物件per、t1、t2,如果都被序列化,會存在這樣一個問題,在序列化t1的時候,會隱式的序列化person物件。在序列化t2的時候,也會隱式的序列化person物件。在序列化per的時候,會顯式的序列化person物件。所以在反序列化的時候,會得到三個person物件,這樣就會造成t1、t2所引用的person物件不是同一個。顯然,這並不符合圖中所展示的關係,也違背了java序列化的初衷。
為了避免這種情況,JAVA的序列化機制採用了一種特殊的演算法:
1、所有儲存到磁碟中的物件都有一個序列化編號。
2、當程式試圖序列化一個物件時,會先檢查該物件是否已經被序列化過,只有該物件從未(在本次虛擬機器中)被序列化,系統才會將該物件轉換成位元組序列並輸出。
3、如果物件已經被序列化,程式將直接輸出一個序列化編號,而不是重新序列化。
自定義序列化
1、前面介紹可以用transient關鍵字來修飾例項變數,該變數就會被完全隔離在序列化機制之外。還是用前面相同的程式,只是將address變數用transient來修飾:
1 public class Person implements Serializable
2 {
3 int age;
4 transient String address;
5 double height;
6 public Person(int age, String address, double height)
7 {
8 this.age = age;
9 this.address = address;
10 this.height = height;
11 }
12 }
1 public class SerializableTest
2 {
3 public static void main(String[] args) throws IOException, IOException,
4 ClassNotFoundException
5 {
6 ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(
7 "d:/data.txt"));
8 Person p = new Person(25, "China", 180);
9 oos.writeObject(p);
10 oos.close();
11
12 ObjectInputStream ois = new ObjectInputStream(new FileInputStream(
13 "d:/data.txt"));
14 Person p1 = (Person) ois.readObject();
15 System.out.println("age=" + p1.age + ";address=" + p1.address
16 + ";height=" + p1.height);
ois.close();
17 }
18 }
序列化的結果:
反序列化結果:
age=25;address=null;height=180.0
2、在二進位制檔案中,沒有看到"China"的字樣,反序列化之後address的value值為null。
3、這說明使用tranisent修飾的變數,在經過序列化和反序列化之後,JAVA物件會丟失該例項變數值。
鑑於上述的這種情況,JAVA提供了一種自定義序列化機制。這樣程式就可以自己來控制如何序列化各例項變數,甚至不序列化例項變數。
在序列化和反序列化過程中需要特殊處理的類應該提供如下的方法,這些方法用於實現自定義的序列化。
writeObject()
readObject()
這兩個方法並不屬於任何的類和介面,只要在要序列化的類中提供這兩個方法,就會在序列化機制中自動被呼叫。
其中writeObject方法用於寫入特定類的例項狀態,以便相應的readObject方法可以恢復它。通過重寫該方法,程式設計師可以獲取對序列化的控制,可以自主決定可以哪些例項變數需要序列化,怎樣序列化。該方法呼叫out.defaultWriteObject來儲存JAVA物件的例項變數,從而可以實現序列化java物件狀態的目的。
1 public class Person implements Serializable
2 {
3 /**
4 *
5 */
6 private static final long serialVersionUID = 1L;
7 int age;
8 String address;
9 double height;
10 public Person(int age, String address, double height)
11 {
12 this.age = age;
13 this.address = address;
14 this.height = height;
15 }
16
17 //JAVA BEAN自定義的writeObject方法
18 private void writeObject(ObjectOutputStream out) throws IOException
19 {
20 System.out.println("writeObejct ------");
21 out.writeInt(age);
22 out.writeObject(new StringBuffer(address).reverse());
23 out.writeDouble(height);
24 }
25
26 private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException
27 {
28 System.out.println("readObject ------");
29 this.age = in.readInt();
30 this.address = ((StringBuffer)in.readObject()).reverse().toString();
31 this.height = in.readDouble();
32 }
33 }
1 public class SerializableTest
2 {
3 public static void main(String[] args) throws IOException, IOException,
4 ClassNotFoundException
5 {
6 ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(
7 "d:/data.txt"));
8 Person p = new Person(25, "China", 180);
9 oos.writeObject(p);
10 oos.close();
11
12 ObjectInputStream ois = new ObjectInputStream(new FileInputStream(
13 "d:/data.txt"));
14 Person p1 = (Person) ois.readObject();
15 System.out.println("age=" + p1.age + ";address=" + p1.address
16 + ";height=" + p1.height);
17 ois.close();
18 }
19 }
序列化結果:

反序列化結果:
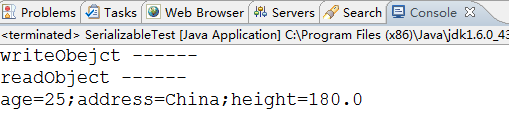
1、這個地方跟前面的區別就是在Person類中提供了writeObject方法和readObject方法,並且提供了具體的實現。
2、在ObjectOutputStream呼叫writeObject方法執行過程,肯定呼叫了Person類的writeObject方法,因為在控制檯上將程式碼中第20行的日誌輸出了。
3、自定義實現的好處是:程式設計師可以更加精細或者說可以去定製自己想要實現的序列化,如例子中將address變數值反轉。利用這種特點,我們可以在序列化過程中對一些敏感信 息做特殊的處理。
4、在這裡因為我們在要序列化的類中提供了這兩個方法,所以被呼叫了,如果不提供,我認為會預設呼叫ObjectOutputStream/ObjectInputStream提供的這兩個方法。
序列化問題
1、靜態變數不會被序列化。
2、子類序列化時:
如果父類沒有實現Serializable介面,沒有提供預設建構函式,那麼子類的序列化會出錯;
如果父類沒有實現Serializable介面,提供了預設的建構函式,那麼子類可以序列化,父類的成員變數不會被序列化。
如果父類實現了Serializable介面,則父類和子類都可以序列化。