
人臉識別:NormFace
提出問題
之前的人臉識別工作,在特徵比較階段,通常使用的都是特徵的餘弦距離

而餘弦距離等價於L2歸一化後的內積,也等價L2歸一化後的歐式距離(歐式距離表示超球面上的弦長,兩個向量之間的夾角越大,弦長也越大)
然而,在實際上訓練的時候用的都是沒有L2歸一化的內積
關於這一點可以這樣解釋,Softmax函式是:
可以理解為Wk和特徵向量x的內積越大,x屬於第k類概率也就越大,訓練過程就是最大化x與其標籤對應項的權值的過程。
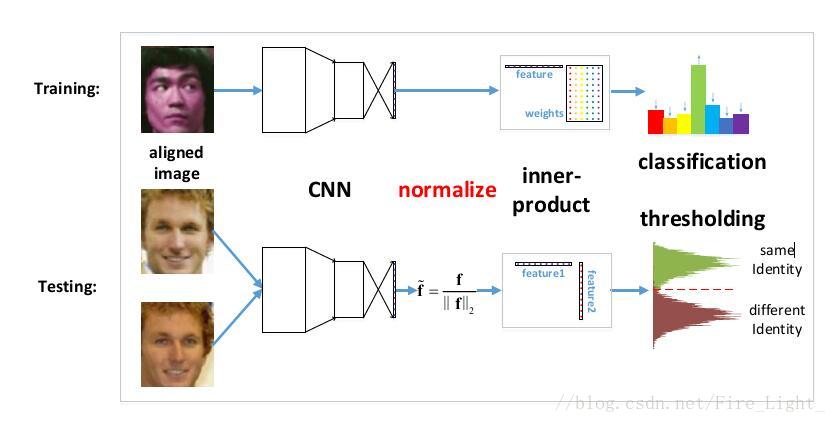
這也就是說在訓練時使用的距離度量與在測試時使用的度量是不一樣的。
測試時是否需要歸一化?
為了說明這個問題,作者特意做了試驗,說明進行人臉驗證時使用歸一化後的內積或者歐式距離效果明顯
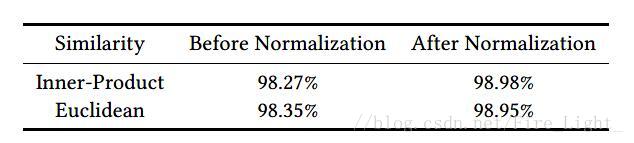
*注意這個Normalization不同於batch normalization,一個是對L2範數進行歸一化,一個是均值歸零,方差歸一。
那麼是否可以直接在訓練時也對特徵向量歸一化?
針對上面的問題,作者設計實驗,通過歸一化Softmax所有的特徵和權重來建立一個cosine layer,實驗結果是網路不收斂了。
本論文要解決的四大問題:
1.為什麼在測試時必須要歸一化?
2.為什麼直接優化餘弦相似度會導致網路不收斂?
3.怎麼樣使用softmaxloss優化餘弦相似度
4.既然softmax loss在優化餘弦相似度時不能收斂,那麼其他的損失函式可以收斂嗎?
L2歸一化
首先解釋問題1和2,即為什麼必須要歸一化和為什麼直接優化歸一化後的特徵網路不會收斂
為什麼要歸一化?
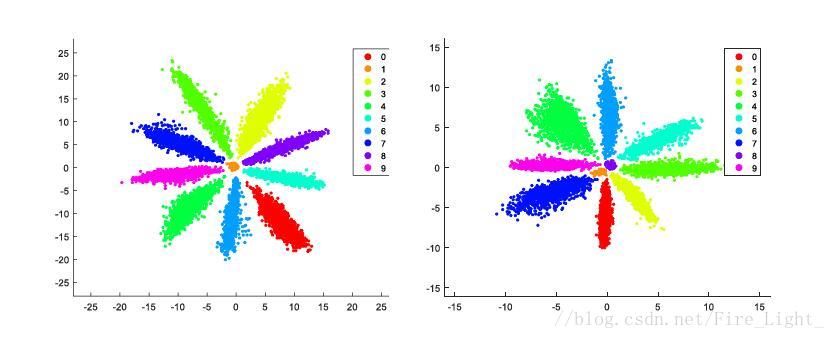
全連線層特徵降至二維的MNIST特徵圖,(具體細節可以參考我的部落格人臉識別系列(十二):Center Loss)
左圖中,f2f3是同一類的兩個特徵,但是可以看到f1和f2的距離明顯小於f2f3的距離,因此假如不對特徵進行歸一化再比較距離的話,可能就會誤判f1f2為同一類。
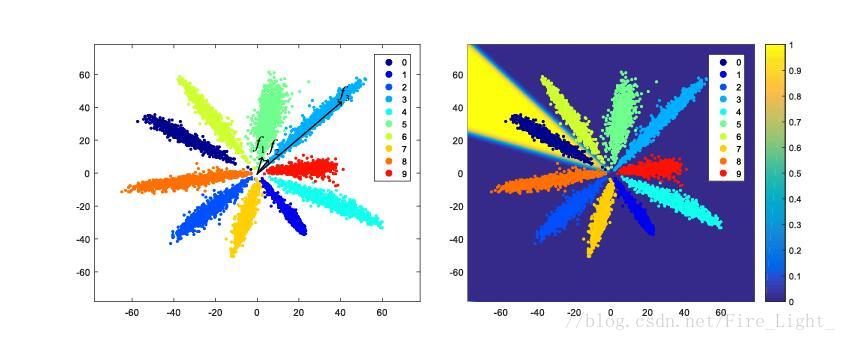
為什麼會是特徵會呈輻射狀分佈
Softmax實際上是一種(Soft)軟的max(最大化)操作,考慮Softmax的概率
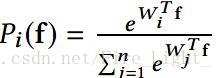
假設是一個十個分類問題,那麼每個類都會對應一個權值向量W0,W1...W9W0,W1...W9,某個特徵f會被分為哪一類,取決f和哪一個權值向量的內積最大
對於一個訓練好的網路,權值向量是固定的,因此f和W的內積只取決與f與W的夾角。
也就是說,靠近W0W0的向量會被歸為第一類,靠近W1W1的向量會歸為第二類,以此類推。網路在訓練過程中,為了使得各個分類更明顯,會讓各個權值向量W逐漸分散開,相互之間有一定的角度,而靠近某一權值向量的特徵就會被歸為相應的類別,因此特徵最終會呈輻射狀分佈。
如果添加了偏置結果會是怎麼樣的?
如果添加了偏置,不同類的b不同,則會造成有的類w角度近似相等,而依據b來區分的情況,如下圖。
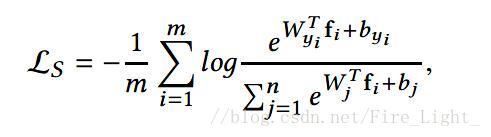
在這種情況下如果再對w進行歸一化,那麼中間這些類會散步在單位圓上各個方向,造成錯誤分類。
所以新增偏置對我們通過餘弦距離來分類沒有幫助,弱化了網路的學習能力,所以我們不新增偏置。
網路為何不收斂
記得前面我們提到,作者做了實驗,通過歸一化Softmax所有的特徵和權重來建立一個cosine layer,實驗結果是網路不收斂了,接下來就解釋是為什麼。
歸一化後的內積
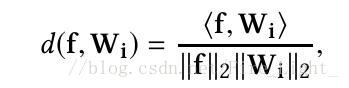
是一個[-1,1]區間的數,經過softmax函式之後,即使各個類別都被完全分開了(即f和其標籤對應類的權值向量WfWf的內積為1,而與其他類的權值向量內積都是-1),其輸出的概率也會是一個很小的數:
上式在n=10時,結果為0.45;在n=1000時,結果為 0.007,非常之小。
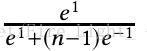
因此即使對於完全分開的類,由於梯度中有一項是(1-y),其梯度還是很大,因此無法收斂。
為了解決這一問題,作者提出了一個關於Softmax的命題來告訴大家答案。
命題:如果把所有的W和特徵的L2norm都歸一化後乘以一個縮放參數L,且假設每個類的樣本數量一樣,則Softmax損失
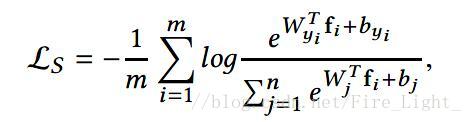
的下界(在所有類都完全分開的情況下)是
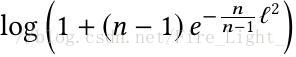
(文末貼出了證明過程)
其下界和歸一化後縮放的引數l的函式圖大約如下:
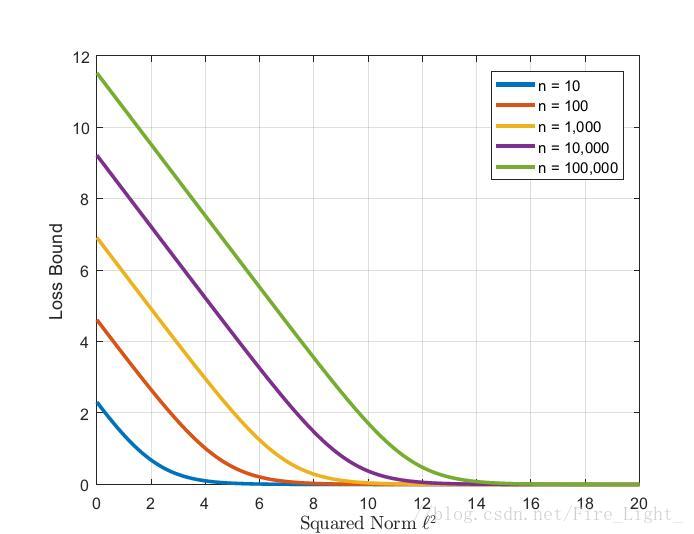
因此,在歸一化層後新增一層放大層l可以解決無法收斂的問題。
歸一化層的定義
首先定義二範數,加一個很小的ε是為了防止歸一化時會除以0.
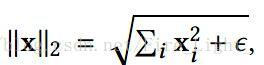
定義歸一化層
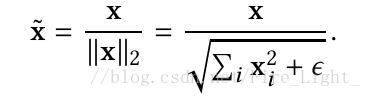
損失函式對歸一化層的求導如下(建議大家自行推導以加深印象):
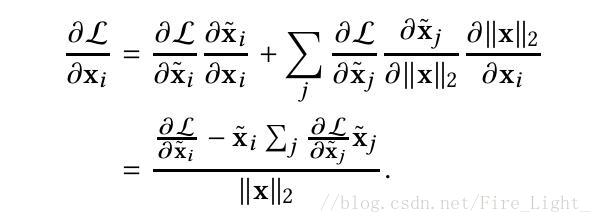
根據上式可以推導,L對特徵x的梯度總是和x的特徵正交(文末貼出了證明過程),
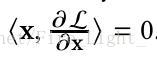
因此經過梯度下降之後,x的範數總會增大,為了防止範數無限增大,需要使用權重衰減項。
改進度量學習
藉助於以上對Softmax的透徹研究,作者順手改進了一下度量學習通常要使用兩個損失函式contrastive loss與triplet loss。兩者原公式表達如下:
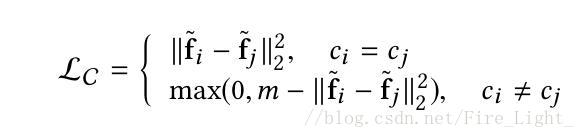
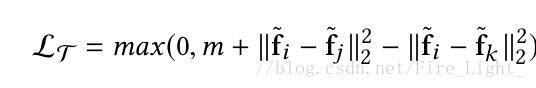
這兩者不同於Softmax的單項直接訓練,存在挖掘pairs/triplets耗費時間的問題。
藉助於Softmax直接以W與X相乘表示餘弦相似度的思路,改進以上兩種Loss為
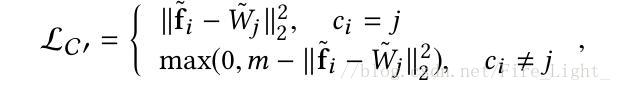
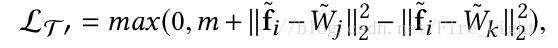
Wj作為對應項的權值向量,可以由網路自己訓練獲得。
改進之後的損失函式稱為C-contrastive/triplet loss。
試驗
訓練
作者使用個一個淺層的網路和一個深層的網路進行試驗,在全連線層後面進行歸一化,然後計算W和X的內積(Softmax)或是歐式距離(C-contrastive/triplet loss),然後按照上面的損失函式計算損失和梯度
學習率1e-4、1e-3 衝量0.9
驗證演算法
一張圖片和它的水平翻轉圖把特徵對應的位置相加(一般是相接),然後PCA,計算餘弦相似度
結果
LFW
1.使用淺層網路
結果看上去Normalization比損失函式還重要
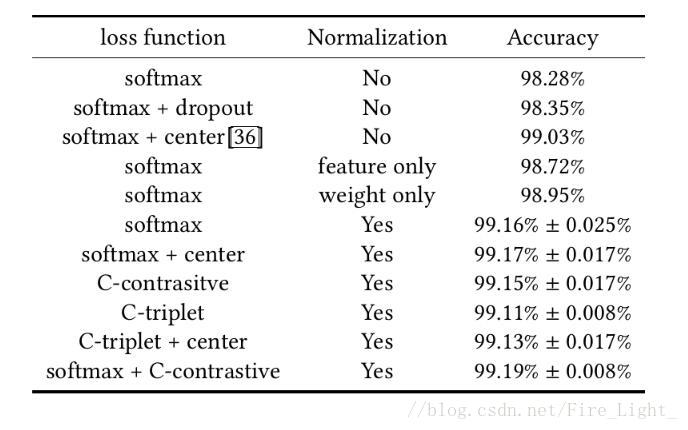
2.使用resnet
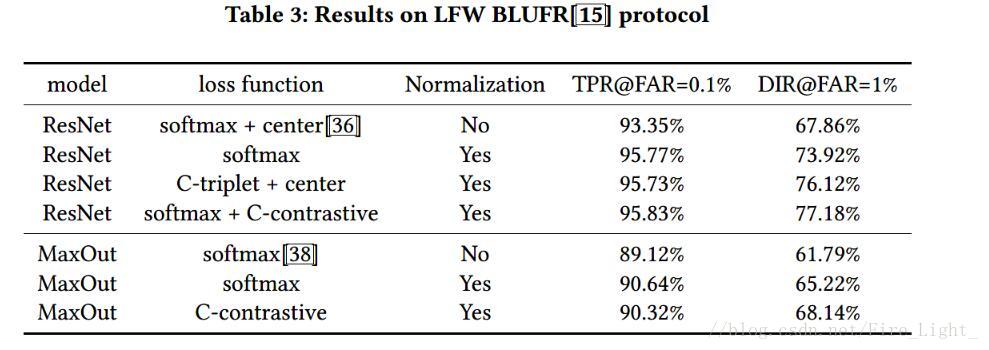
這個似乎是說明了resnet還是很有效的
附錄:命題的證明
證明一:
命題:如果把所有的W和特徵的L2norm都歸一化為L,且假設每個類的樣本數量一樣,則Softmax損失
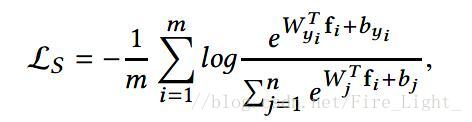
的下界(在所有類都完全分開的情況下)是
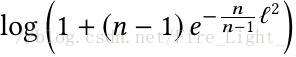
證:
因為每個類樣本數量一樣,假設有n個類,則L等價於
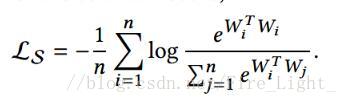
(其中||Wi||=l,因為完全分開了,所以Wi可以代表該類特徵。)
同除得到

由於exp(x)的凸性,有
當且僅當Xi互相相等時等號成立
即
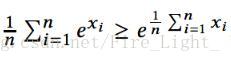
那麼
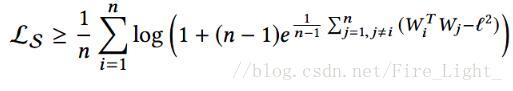
又
同是凸函式
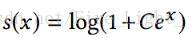
有
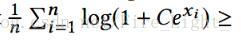
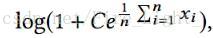
所以
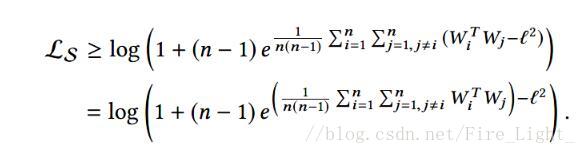
注意到
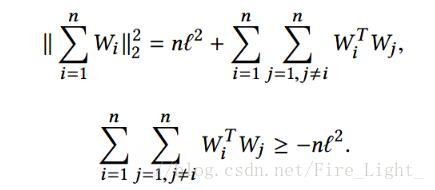
所以

命題得證,考慮等號成立的條件需要任何WaWb內積相同,而對於h維向量W,只能找到h+1個點,使得兩兩連線的向量內積相同,如二維空間的三角形和三位空間的三面體,但是最終需要分類的數目可能遠大於特徵維度,所以經常無法取到下界。
證明二:

過程相對簡單
https://blog.csdn.net/fire_light_/article/details/79601378?utm_source=copy