
用Tensorflow搭建第一個神經網路
阿新 • • 發佈:2018-12-13
簡述
搭建這個神經網路
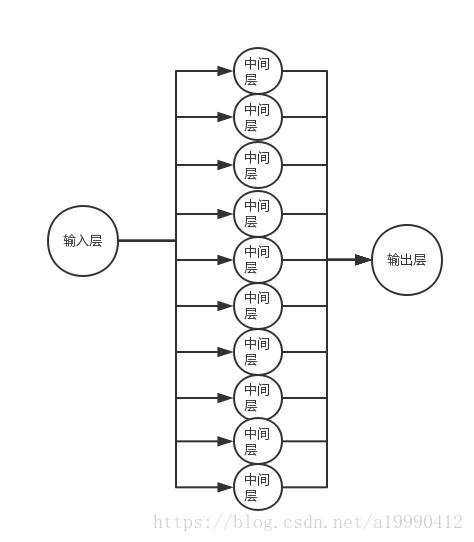
其實是從一個層到10層再到10層的這樣的一個神經網路。(畫圖醜。。。求諒解。。就別私戳了)
解析
- 初始的輸入的矩陣為:[[1],300個,[-1]] 大致這樣的
- 在增加一層的那個函式中,最為經典的地方是,偏置(biases)的第一個維度必須選為1。看下面推理。
- 第一部分:
- 輸入為:(300*1)的矩陣,之後,經過了第一個層,就是
(300 * 1)* (1*10) + (1, 10)。這顯然是合理的,沒一層的資料,到神經網路中的中間層的每一個節點上,然後每個節點上都加一個偏置biases。
就是在每個上都同時加,通過下面的例子就可以看出來。
>>> import numpy as - 第二部分:
- 輸出的內容為上面的輸出:
(300*10)的矩陣。 - 進行的計算為:
(300 * 10) * (10 * 1) + (1, 1)後面的那個為偏置,每個都加上了這樣的一個偏置。
經過上面的推理,我們就可以理解了為什麼中間新增新的一層的時候,需要將biases的第一次引數為1
- 發現寫tensorflow就想當於寫數學公式一樣,怪不得TensorFlow在研究數學的老師那邊那麼容易上手 hhh
程式碼
import tensorflow as tf
import numpy as np
# TensorFlow嫌棄了我這臺電腦的CPU(我這就避免了警報)
# ==================
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
# ==================
# 建立一些等距離的資料(資料量為300),同時用np.newaxis進行擴充套件一個維度
x_data = np.linspace(-1, 1, 300, dtype=np.float32)[:, np.newaxis]
# 建立同等規模的噪音(這裡採用的是均值為0,標準差為0.05的,保持shape和型別一致)
noise = np.random.normal(0, 0.05, x_data.shape).astype(np.float32)
# 原資料label(y = x^2 - 0.5) 之後新增一點點噪聲(讓人感覺更像現實中獲取的資料一樣)
y_data = np.square(x_data) - 0.5 + noise
# 建立一個新增層數的函式,使得實現變得簡單
# inputs是輸出的東西,in_size表示的是該層的輸入層維度,out_size表示的是該層的輸出層維度,activation_function就是一個
def add_layer(inputs, in_size, out_size, activation_function=None):
# 建立係數矩陣,矩陣規模為 [in_size * out_size]
Weights = tf.Variable(tf.random_normal([in_size, out_size]))
# 建立一個biases矩陣,這裡考慮到biases用0不是那麼好,所以,一開始設定的時候加個0.1
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1)
# 構建方程
Wx_plus_b = tf.matmul(inputs, Weights) + biases
if activation_function == None:
output = Wx_plus_b
else:
output = activation_function(Wx_plus_b)
return output
xs = tf.placeholder(tf.float32, [None, 1])
ys = tf.placeholder(tf.float32, [None, 1])
# 得到中間那一層
l1 = add_layer(xs, 1, 10, activation_function=tf.nn.relu)
# 得到輸出層
prediction = add_layer(l1, 10, 1)
# 在300個求一個平方和的均值,設定了切片的index為1,原因是最後的矩陣規模為300*1,大致類似:[[1],300個,[2]]
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction),
reduction_indices=[1]))
# 梯度下降訓練
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
# 變數初始化
init = tf.global_variables_initializer()
# 啟動會話
with tf.Session() as sess:
sess.run(init)
for i in range(1000):
# training
sess.run(train_step, feed_dict={xs: x_data, ys: y_data})
if i % 50 == 0:
# to see the step improvement
print(sess.run(loss, feed_dict={xs: x_data, ys: y_data}))
附上有圖形演示的程式碼
由於不同起始資料,畫出幾個不同的結果。下面列舉其中的兩個
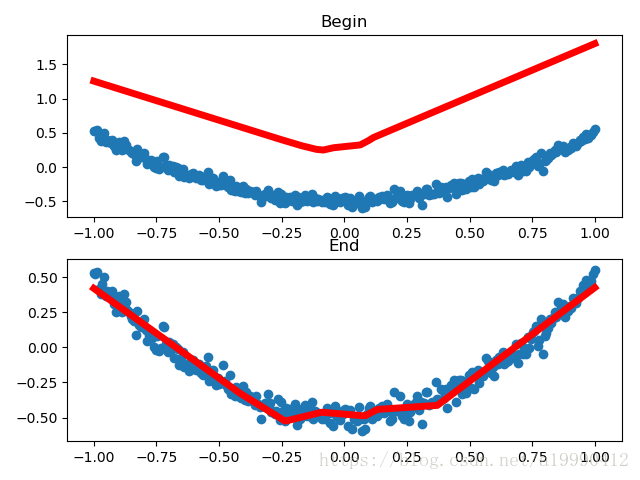
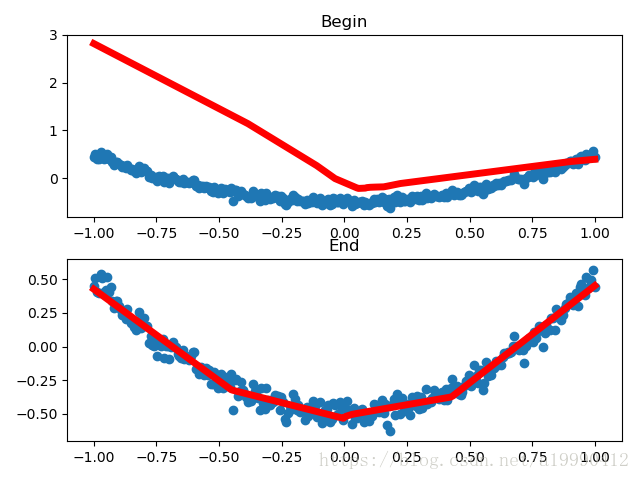
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# TensorFlow嫌棄了我這臺電腦的CPU(我這就避免了警報)
# ==================
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
# ==================
# 建立一些等距離的資料(資料量為300),同時用np.newaxis進行擴充套件一個維度
x_data = np.linspace(-1, 1, 300, dtype=np.float32)[:, np.newaxis]
# 建立同等規模的噪音(這裡採用的是均值為0,標準差為0.05的,保持shape和型別一致)
noise = np.random.normal(0, 0.05, x_data.shape).astype(np.float32)
# 原資料label(y = x^2 - 0.5) 之後新增一點點噪聲(讓人感覺更像現實中獲取的資料一樣)
y_data = np.square(x_data) - 0.5 + noise
# 建立一個新增層數的函式,使得實現變得簡單
# inputs是輸出的東西,in_size表示的是該層的輸入層維度,out_size表示的是該層的輸出層維度,activation_function就是一個
def add_layer(inputs, in_size, out_size, activation_function=None):
# 建立係數矩陣,矩陣規模為 [in_size * out_size]
Weights = tf.Variable(tf.random_normal([in_size, out_size]))
# 建立一個biases矩陣,這裡考慮到biases用0不是那麼好,所以,一開始設定的時候加個0.1
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1)
# 構建方程
Wx_plus_b = tf.matmul(inputs, Weights) + biases
if activation_function == None:
output = Wx_plus_b
else:
output = activation_function(Wx_plus_b)
return output
xs = tf.placeholder(tf.float32, [None, 1])
ys = tf.placeholder(tf.float32, [None, 1])
# 得到中間那一層
l1 = add_layer(xs, 1, 10, activation_function=tf.nn.relu)
# 得到輸出層
prediction = add_layer(l1, 10, 1)
# 在300個求一個平方和的均值,設定了切片的index為1,原因是最後的矩陣規模為300*1,大致類似:[[1],300個,[2]]
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction),
reduction_indices=[1]))
# 梯度下降訓練
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
# 變數初始化
init = tf.global_variables_initializer()
# 啟動會話
with tf.Session() as sess:
sess.run(init)
fig = plt.figure()
# 建立兩個子圖
ax_begin = fig.add_subplot(2, 1, 1)
ax_end = fig.add_subplot(2, 1, 2)
ax_begin.scatter(x_data, y_data)
ax_end.scatter(x_data, y_data)
# 起始版
prediction_value = sess.run(prediction, feed_dict={xs: x_data})
# plot the prediction
ax_begin.plot(x_data, prediction_value, 'r-', lw=5)
ax_begin.set_title("Begin")
plt.tight_layout()
for i in range(1000):
# training
sess.run(train_step, feed_dict={xs: x_data, ys: y_data})
if i % 50 == 0:
# to see the step improvement
print(sess.run(loss, feed_dict={xs: x_data, ys: y_data}))
# 經過迭代後的版本
prediction_value = sess.run(prediction, feed_dict={xs: x_data})
# plot the prediction
ax_end.plot(x_data, prediction_value, 'r-', lw=5)
ax_end.set_title("End")
plt.show()