
pyecharts資料分析及展示
阿新 • • 發佈:2018-12-13
僅僅從網上爬下資料當然是不夠用的,主要還得對資料進行分析與展示,大部分人都看重薪資,但是薪資資料有的是*k/月,有的是*萬/月,還有*萬/年等等,就要對資料進行清理
將所有單位統一化,全部換算成統一單位,然後分類薪資範圍,在計算各個範圍的數量,最後繪圖展示
import pymysql import numpy as np from pyecharts import Bar from pyecharts import Pie class Mysqlhelper(object): config = { "host": "localhost", "user": "root", "password": "123456", "db": "test", "charset": "utf8" } def __init__(self): self.connection = None self.cursor = None # 從資料庫中查詢多行資料 def getlist(self, sql, *args): try: self.connection = pymysql.connect(**Mysqlhelper.config) # **接函式所有引數 self.cursor = self.connection.cursor() self.cursor.execute(sql, args) return self.cursor.fetchall() except Exception as ex: print(ex, ex) finally: self.close() def close(self): if self.cursor: self.cursor.close() if self.connection: self.connection.close() if __name__ == "__main__": count=0 list = [] list1 = [] list2 = [5000,10000,15000,20000,25000,30000,35000,40000] salary0 = [] salary1 = [] salary2 = [] salary3 = [] salary4 = [] salary5 = [] salary6 = [] salary7 = [] city=[] helper = Mysqlhelper() rows = helper.getlist("select * from t_job") #print(rows) for n in rows: if n[4][-1]=='月': list.append(n[4]) elif n[4][-1]=='年': pass elif n[4][-1]=='天': pass else: pass for sale in list: #print(sale) money = sale.split('/') #print(money[0]) money1 = money[0].split('-') #print(money1) if money[0][-1] == '萬': a = float(money1[0]) * 10000 b = float(money1[1][:-1]) * 10000 aveage = (a + b) / 2 count+=1 list1.append(aveage) elif money[0][-1]=='千': a = float(money1[0]) * 1000 b = float(money1[1][:-1]) * 1000 #print(a) #print(b) aveage = (a + b) / 2 #print(aveage) count += 1 list1.append(aveage) #print(count) #print(list1) for i in list1: print(i) if 0 < i <= 5000: salary0.append(i) elif 5000 < i <= 10000: salary1.append(i) elif 10000 < i <= 15000: salary2.append(i) elif 15000 < i <= 20000: salary3.append(i) elif 20000 < i <= 25000: salary4.append(i) elif 25000 < i <= 30000: salary5.append(i) elif 30000 < i <= 35000: salary6.append(i) elif 35000 < i <= 40000: salary7.append(i) print(min(list1)) print(max(list1)) a = len(salary0) b = len(salary1) c = len(salary2) d = len(salary3) e = len(salary4) f = len(salary5) g = len(salary6) h = len(salary7) list3=[a,b,c,d,e,f,g,h] print(list2) #x軸 print(a,b,c,d,e,f,g,h) print(list3) #數量 bar = Bar('Python平均工資') bar.add("月薪", list2,list3) # bar.show_config() bar.render('Python工資柱狀圖.html') pie = Pie() pie.add("", list2, list3, is_label_show=True) #pie.show_config() pie.render('Python工資餅狀圖.html') ''' #print(rows) citycount=[] cityname=['北京','異地招聘','海淀區','朝陽區','豐臺區','昌平區','東城區','延慶區', '房山區','通州區','順義區','大興區','懷柔區','西城區','平谷區','門頭溝區'] beijing=[] yidi=[] haidian=[] chaoyang=[] fengtai=[] changping=[] dongcheng=[] yanqing=[] fangshan=[] tongzhou=[] shunyi=[] daxing=[] huairou=[] xicheng=[] pinggu=[] mentougou=[] for n in rows: #print(n[3]) area=n[3].split('-') print(area) if len(area)==1: print(area[0]) city.append(area[0]) else: print(area[1]) city.append(area[1]) print(city) print(len(city)) for i in city: if i=='北京': beijing.append(i) elif i=='異地招聘': yidi.append(i) elif i=='海淀區': haidian.append(i) elif i == '朝陽區': chaoyang.append(i) elif i=='豐臺區': fengtai.append(i) elif i=='昌平區': changping.append(i) elif i=='東城區': dongcheng.append(i) elif i=='延慶區': yanqing.append(i) elif i=='房山區': fangshan.append(i) elif i=='通州區': tongzhou.append(i) elif i=='順義區': shunyi.append(i) elif i=='大興區': daxing.append(i) elif i=='懷柔區': huairou.append(i) elif i=='西城區': xicheng.append(i) elif i=='平谷區': pinggu.append(i) elif i=='門頭溝區': mentougou.append(i) #print(beijing) #print(len(beijing)) a = len(beijing) b = len(yidi) c = len(haidian) d = len(chaoyang) e = len(fengtai) f = len(changping) g = len(dongcheng) h = len(yanqing) j = len(fangshan) k = len(tongzhou) l = len(shunyi) m = len(daxing) n = len(huairou) o = len(xicheng) p = len(pinggu) q = len(mentougou) citycount=[a,b,c,d,e,f,g,h,j,k,l,m,n,o,p,q] print(cityname) print(citycount) pie = Pie() pie.add("", cityname, citycount, is_label_show=True) # pie.show_config() pie.render('北京各區Python職位佔比餅狀圖.html') bar = Bar('北京各區職位數量') bar.add("數量", cityname, citycount) # bar.show_config() bar.render('北京各區Python職位佔比柱狀圖.html') '''
前面寫的是資料庫的操作函式,其實可以封裝成一個py檔案,以後使用直接呼叫即可。
結果。: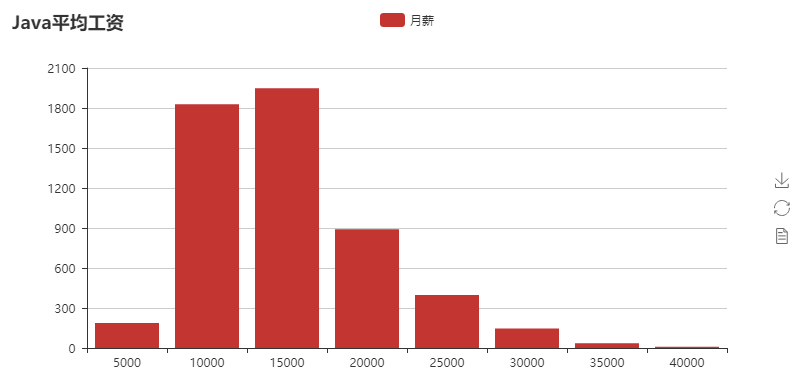
我也分析了boss直聘網站的一些資料,類似於經驗要求和學歷要求等等,也可以自己分析想要的資料。
import pymysql import numpy as np from pyecharts import Bar from pyecharts import Pie import jieba from collections import Counter from os import path class Mysqlhelper(object): config={ "host":"localhost", "user":"root", "password":"123456", "db":"test", "charset":"utf8" } def __init__(self): self.connection=None self.cursor=None # 從資料庫中查詢多行資料 def getlist(self, sql, *args): try: self.connection = pymysql.connect(**Mysqlhelper.config) # **接函式所有引數 self.cursor = self.connection.cursor() self.cursor.execute(sql, args) return self.cursor.fetchall() except Exception as ex: print(ex,ex) finally: self.close() def close(self): if self.cursor: self.cursor.close() if self.connection: self.connection.close() if __name__=="__main__": sale=[] exp=[] edu=[] one = [] three = [] five = [] onein = [] noexp = [] qita=[] benke=[] dazhuan=[] noedu=[] boshi=[] other=[] helper = Mysqlhelper() rows = helper.getlist("select * from boss_job") #print(rows) for data in rows: #print(data[2]) #print(data[5]) #print(data[6]) sale.append(data[2]) exp.append(data[5]) edu.append(data[6]) if data[5]=='1-3年': one.append(data[5]) elif data[5]=='3-5年': three.append(data[5]) elif data[5]=='5-10年': five.append(data[5]) elif data[5]=='經驗不限': noexp.append(data[5]) elif data[5]=='1年以內': onein.append(data[5]) else: qita.append(data[5]) pass if data[6]=='本科': benke.append(data[6]) elif data[6]=='大專': dazhuan.append(data[6]) elif data[6]=='博士': boshi.append(data[6]) elif data[6]=='學歷不限': noedu.append(data[6]) else: other.append(data[6]) # with open('./data/jingyan.txt', 'a', encoding='utf-8') as fp: # fp.write(data[5]) # fp.write(',') # fp.flush() # fp.close() print(exp) print(edu) print(len(exp)) print(len(edu)) ''' d = path.dirname(__file__) jingyan_text = open(path.join(d, "data//jingyan.txt"), encoding='utf-8').read() print(len(jingyan_text)) jieba.load_userdict("data//jingyan_dict.txt") seg_list = jieba.cut_for_search(jingyan_text) print(u"[全模式]: ", "/ ".join(seg_list)) ''' # sanguo_words = [x for x in jieba.cut(jingyan_text)if x!=','and len(x) >=2] # c = Counter(sanguo_words).most_common(20) # print(c) # print(''.join(jieba.cut(jingyan_text))) print(one) print(three) print(five) print(noexp) print(onein) print(qita) a=len(one) b=len(three) c=len(five) d=len(noexp) e=len(onein) f=len(qita) expcount=[f,e,a,b,c,d] expfenlei=['應屆生','1年以內','1-3年','3-5年','5-10年','經驗不限'] print(expcount) print(a+b+c+d+e+f) print(other) g=len(benke) h=len(dazhuan) j=len(boshi) k=len(noedu) m=len(other) educount=[h,g,k,j,m] edufenlei=['大專','本科','碩士','博士','學歷不限'] print(educount) ''' bar = Bar('工作年限') bar.add("要求", expfenlei, expcount) # bar.show_config() bar.render('工作年限柱狀圖.html') pie = Pie() pie.add("工作", expfenlei, expcount, is_label_show=True) # pie.show_config() pie.render('工作年限餅狀圖.html') ''' bar = Bar('學歷要求') bar.add("學歷", edufenlei, educount) # bar.show_config() bar.render('學歷要求柱狀圖.html') pie = Pie() pie.add("學歷", edufenlei, educount, is_label_show=True) # pie.show_config() pie.render('學歷要求餅狀圖.html')
我使用的是最基本的陣列方法,不知道有什麼簡單方法麼,例如jieba分詞模組,等等

可以看出本科生需求還是很大的。。。