
檔案系統 磁碟 梳理
只做簡單理解,因為資料庫原理課上老師講了資料庫實現了資料的獨立,就是不管資料真正存在哪裡,我要查這個,你給我就完事了;而作業系統實現了具體裝置的獨立性。不管你哪個廠家的滑鼠,鍵盤,顯示器,插上來我就能用,顯示的協議都一樣。
感覺挺有道理的,越來越感覺到介面和抽象的威力,簡直是人類協作的一大利器,這讓我想到大話設計模式中說的,四大發明其他三個都是真的發明,但是活字印刷術只不過是改進了原來的印刷技術,怎麼能和其他並列呢?那是因為活字印刷術就是最早的面向物件方法啊!可擴充套件,可維護,可複用,靈活性好~仔細想想都很符合,這就是設計理念的力量,不多扯了哈哈。
資料庫的資料存在哪呢?我們都以檔案形式寫檔案裡了,但是檔案是作業系統虛擬出來的檔案系統啊,資料其實是存在磁盤裡
檔案系統
檔案
在系統執行時,計算機以程序為基本單位進行資源的排程和分配;而在使用者進行的輸入、輸出中,則以檔案為基本單位。檔案的概念不需要死記硬背,其實就是一種邏輯上的組織形式,現在在PC裡已經是無處不在了。
但是需要抽象的理解一下,就是有一堆資料項,比如說描述物件某個屬性的值,人的名字,一些資料項 名字啊,性別啊組合起來就成為一個記錄,然後檔案就是這些記錄的一個集合。
這個檔案要麼是有結構的,比如說某班學生檔案裡記錄了班級裡學生的資訊,他們都很相似,這就是有結構的;無結構的檔案就堪稱字元流就行了,看不懂的編譯後的檔案那些就算無結構的。
目錄
檔案有一定的屬性,包括名稱啊,唯一識別符號啊,型別,位置,大小等等,都儲存在目錄結構中。這個目錄結構也存在外村上。檔案資訊需要時再被調入記憶體。一般,目錄條目包括檔名,和唯一識別符號。這個唯一識別符號就能定位檔案其他的屬性資訊。
所以在建立檔案時不僅要在檔案系統中為檔案找到空間這個動作,還要在目錄中
寫檔案也是類似,告訴系統我要寫的檔名和內容。對於給定的檔名,系統先搜尋目錄,根據條目去定位檔案位置。然後再把一個寫的指標返回回來給你寫內容。
其他操作也是類似。這就是檔案目錄的好處。但是因為很多操作都涉及給定檔名然後搜尋相關目錄條目,而目錄條目也是在外存上的,這樣就不方便所以許多系統要求在首次使用檔案的時候,呼叫一個open。維護一個包含所有開啟檔案資訊的表,就叫開啟檔案表。
目的就是需要一個檔案操作時,這個表裡要是有,直接按照裡面的索引找就行了,不用在去目錄裡搜。其實是個執行時快取的思想吧。檔案不用了程序可以關閉,作業系統再從開啟檔案表裡刪除這個條目。
可以簡單的理解為,open之後,把檔案的目錄條目直接放到開啟檔案表裡。然後程序開啟檔案要操作的時候,給你個指標,簡化步驟,IO操作都用這個指標就行了,不需要知道檔名了。
目錄結構
再細對現在的我還用處不大,值得講的是,目錄結構裡,有個檔案控制塊,跟程序控制塊差不多,叫FCB,名字也差不多,就是實現給你個檔名字,在目錄結構裡能找到他。
這個FCB裡有一堆檔案的基本資訊和存取控制資訊,如檔案的存取許可權,使用資訊,如什麼時候建的、什麼時候修改過這些,這個東西就是要記錄的東西。前面說的記錄一個條目或者說目錄項,就是這個條目。建立新檔案的時候,就有一個FCB放進檔案目錄中。
然後進一步的,每次檢索目錄檔案也就是前面那個目錄的時候,都是拿著給的檔名一直查查查,只有匹配了才會看目錄項裡其他的,比如實體地址啊什麼的。其他描述資訊沒啥用,所以像UNIX這樣的系統,有在中間加了一層,檔案的描述資訊單獨形成一個成為索引節點的東西,inode。每個目錄項只放檔名,和指向它的inode的指標。
意思就是拿著檔名先匹配,匹配到了再說,給你個inode指標,你在去裡面找檔案的實體地址吧,這樣節省了好多系統開銷。
因為一個FCB是64B,而UNIX系統一個目錄只佔16B,我們知道真正查檔案時是在磁碟上找的,每次查磁碟最小是查一個塊(這個後面講磁碟會再梳理一下),一個塊裡你放的東西多,那你需要找的塊就少,你跟磁碟互動的次數就少了3/4,大大節省了開銷。
下面這個概念也要了解下,直接複製的。
多級目錄結構
也成為樹形目錄結構。將兩級目錄結構的層析加以推廣,就形成了多級目錄結構,及樹形目錄結構。
使用者要訪問某個檔案時用檔案的路徑名標識檔案,檔案路徑名是一個字串,由從根目錄出發到所找檔案的通路商的所有目錄名與資料檔名用分隔符/連線起來而成。從根目錄出發的路徑稱為絕對路徑。當層次較多時,每次從根目錄查詢浪費時間,於是加入了當前目錄,程序對各檔案的訪問都是相對於當前目錄進行的。當用戶要訪問某個檔案時,使用相對路徑標識檔案,相對路徑由從當前目錄出發到所找檔案通路商所有目錄名與資料檔名用分隔符**/**連結而成。
通常,每個使用者都有自己的當前目錄,登陸後自動進入該使用者的當前目錄。作業系統提供一條專門的系統呼叫,供使用者隨時改變當前目錄。
樹形目錄結構可以很方便的對檔案進行分類,層次結構清晰,也能夠更有效地進行檔案的管理和保護。但是,**在屬性目錄中查詢一個檔案,需要按路徑名主機訪問中間節點,**這就增加了磁碟訪問次數,無疑將影響查詢速度。
沒有細追究,這個當前目錄跟命令列裡 可以直接操作目前命令列裡的檔案 也可以以絕對路徑操作任意地方的檔案 有關不,感覺是這樣安排的。
檔案的開啟過程
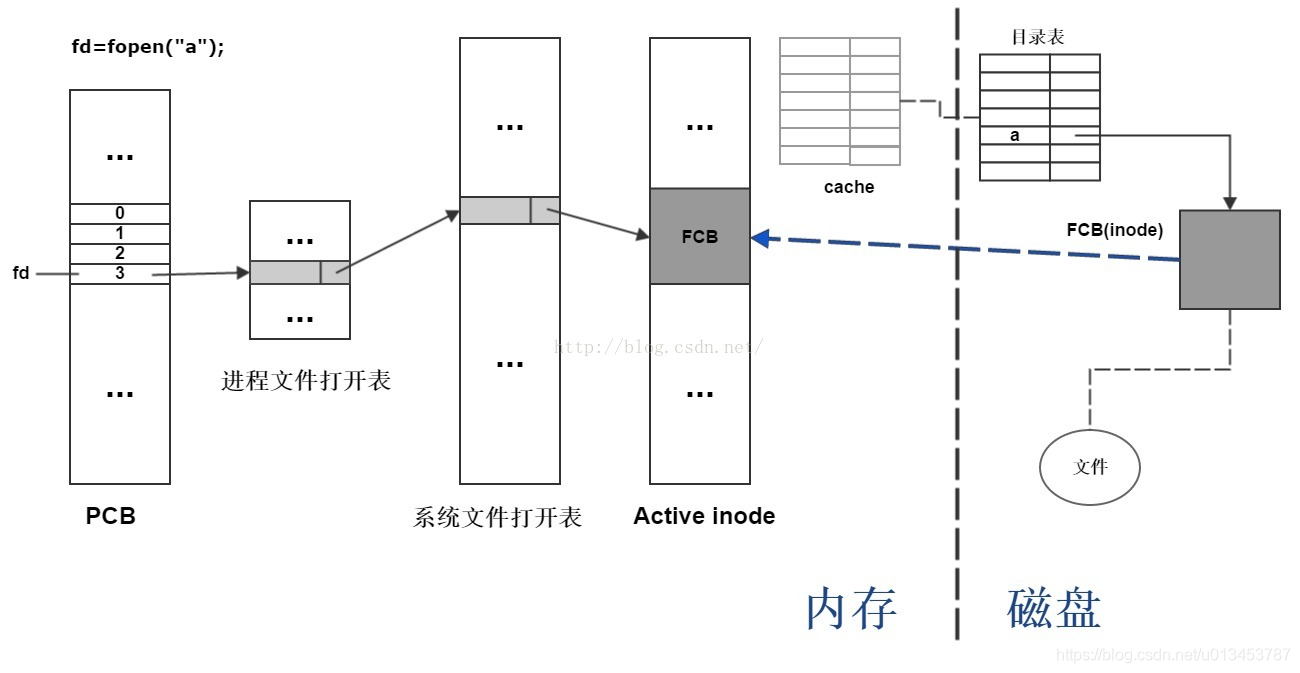
以上是檔案的開啟過程,應該從右往左看。
首先,作業系統根據檔名a,在系統檔案開啟表中查詢
第一種情況:
如果檔案a已經開啟,則在程序檔案開啟表中為檔案a分配一個表項,然後將該表項的指標指向系統檔案開啟表中和檔案a對應的一項;
然後再PCB中為檔案分配一個檔案描述符fd,作為程序檔案開啟表項的指標,檔案開啟完成。
第二種情況:
如果檔案a沒有開啟,檢視含有檔案a資訊的目錄項是否在記憶體中,如果不在,將目錄表裝入到記憶體中,作為cache;
根據目錄表中檔案a對應項找到FCB在磁碟中的位置;
將檔案a的FCB裝入到記憶體中的Active inode中;
然後在系統檔案開啟表中為檔案a增加新的一個表項,將表項的指標指向Active Inode中檔案a的FCB;
然後在程序的檔案開啟表中分配新的一項,將該表項的指標指向系統檔案開啟表中檔案a對應的表項;
然後在PCB中,為檔案a分配一個檔案描述符fd,作為程序檔案開啟表項的指標,檔案開啟完成。
總之就是要完成這一個一個指標一樣的連結,這樣在操作檔案的時候才會可以得到上述那麼多的好處。檔案的大概理解到這裡,有機會在研究真正內部的東西,下面談談磁碟的事。
磁碟
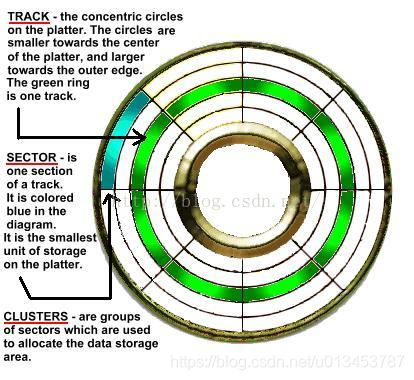
磁碟磁軌柱面的概念網上到處都是,給出一個圖。
物理上來說,硬碟主要由若干碟片、機械手臂、讀寫磁頭與主軸馬達組成。碟片表面塗以磁性介質,用以儲存資料。每個碟片有兩面,都可記錄資訊。而讀寫主要是透過在機械手臂上的讀寫磁頭來達成。實際運作時,主軸馬達讓碟片轉動,然後機械手臂可伸展使磁頭到達指定的位置,在碟片上進行讀寫動作。每個碟片有兩個面,每個面都有一個磁頭。
邏輯上來說,又有磁軌(track)、扇區(Sector)和柱面(Cylinder)的概念:
當磁碟旋轉時,磁頭若保持在一個位置上,則每個磁頭都會在磁碟表面劃出一個圓形軌跡,這些圓形軌跡就叫做磁軌(track)。這些磁軌用肉眼是看不到的,磁碟上的資訊便是沿著這樣的軌道存放的。
碟片上的每個磁軌被等分為若干個弧段,這些弧段便是磁碟的扇區,每個扇區存放512個位元組的資訊,磁碟驅動器在向磁碟讀取和寫入資料時,都是以扇區為單位。
柱面:磁碟通常由一組碟片構成,不同碟片相同半徑的磁軌所組成的圓柱稱為柱面。每個盤面都被劃分為數目相等的磁軌,並從外緣的“0”開始編號。磁軌與柱面都是表示不同半徑的圓,在許多場合,磁軌和柱面可以互換使用
可以得到的資訊有:
1.硬碟容量=磁頭數Head×磁軌(柱面Cylinder)數×每道扇區Sector數×每扇區位元組數(一般初始為512)。這個就是常說的磁碟的CHS,知道了CHS就能確定硬碟的容量。
2.每個磁軌上的扇區數目一樣,所以越往外扇區面積越大,但是早期每個扇區存的資料量一樣,都是512位元組。所以裡面扇區密度大,外面小。
當像硬碟寫入資料時,險些如最外層的磁軌,寫滿所有扇區再往內層磁軌寫。這就是為什麼感覺硬碟用久了,讀寫都會變慢。磁碟整理基本的意思就是能利用再儘量整理整理用外面的。
對磁碟的具體使用需要分割槽,然後在具體作業系統的檔案系統上,這個上面說過了。
關於分割槽需要知道主引導記錄(Master Boot Record,MBR),又叫做主引導扇區,是計算機開機後訪問硬碟時所必須要讀取的首個扇區,它儲存在0號盤面的0號磁軌的1號扇區上。系統在啟動時主動去讀取這個區塊的內容,這樣系統才會知道你的程式放在哪裡且該如何進行啟動。
簇的概念
有的作業系統叫簇,有的叫塊,其實差不多。簇是作業系統分配記憶體的最小單位。如,就算一個檔案小到只有一個位元組,它在磁碟上也不是隻佔一個位元組的空間,而是佔有一簇。這樣設定是為了讓硬碟對資料的管理變得相對容易,因為如果不容易管理資料,存再多都沒有意義,簇通常為多個扇區。
這樣,對磁碟進行存取的時候,最後都是對簇進行的存取而不是一個一個的扇區,減少了磁頭的掃描,可以達到更快的效果。
總結
回到最開始的問題,由以上可知,要想設計一個數據庫事其存取資料的操作很快,一個比較泛化的標準是:必須找到一套儲存和檢索資料的方法,在這樣的方法下,任意的資料庫操作,如大規模的變換條件的查詢,修改,刪除等操作發生時,資料庫跟磁碟的IO,即磁頭掃描簇的操作很少。這樣就可以保證資料庫操作的快速。這裡最大的進步就是,想優化檔案的IO是幼稚的想法,說了很多遍資料其實都是寫在磁碟上的。
基礎很重要,慢慢補。不積跬步無以至千里。