
【函數語言程式設計】範疇論完全裝逼手冊 / Grokking Monad
範疇論是抽象地處理數學結構以及結構之間聯絡的一門數學理論,以抽象的方法來處理數學概念,將這些概念形式化成一組組的“物件”及“態射”。
1 第一部分:範疇論Catergory Theory
很多人都不明白什麼是Monad,並不是因為不會用,不知覺可能就在用某種 monad。 定義和使用起來其實不難,困惑的大多應該是後面的這堆理論– 範疇論。當然,我也沒學過範疇論,只是略微看得懂寫Haskell罷了。
我在書中寫過一章來解釋,某人也嘗試過很寫部落格解釋,比如為了降低門檻用JS來,那Haskell/Scala的人出來噴你們前端這些不懂函式式的渣渣亂搞出來的東西根本就不是 monad。
我也畫過一些圖來解釋,又會被嫌棄畫風不好。但是,作為靈魂畫師,我只 是覺得自己萌萌的啊 在乎畫的靈魂是否能夠給你一點啟發。好吧,講這麼學術的東西,還是用dot來畫吧,看起來好正規呢。
好了,安全帶繫好,我真的要開車了。為了 防止鄙視鏈頂端的語言使用者們噴再嫌棄 解釋的不到位,就用 Haskell 好了(雖然haskell也沒到鄙視鏈頂),其實也不難解釋清楚 才怪 。
這裡面很多很裝逼的單詞,它們都是 斜體 ,就算沒看懂,把這些詞記住也足夠裝一陣子逼了買一陣子萌了。
1.1 Category
一個 範疇Category 包含兩個玩意
- 東西
O(Object) - 兩個東西的關係,箭頭
~>( 態射Morphism )
一些屬性
- 一定有一個叫 id 的箭頭,也叫做 1
- 箭頭可以 組合compose
恩,就是這麼簡單
Figure 1: 有東西 a, b, c 和箭頭 f, g 的 Category,其中 f . g 表示 compose f 和 g
這些玩意對應到 haskell 的 typeclass 大致就是這樣
class Category (c :: * -> * -> *) where
id :: c a a
(.) :: c y z -> c x y -> c x z
注意到為什麼我會箭頭從右往左,你會發現這個方向跟 compose 的方向剛好一致
如果這是你第一次見到 Haskell 程式碼,沒有關係,語法真的很簡單 才怪
class定義了一個 TypeClass,Category是這個 TypeClass 的名字- Type class 類似於定義型別的規範,規範為
where後面那一坨 - 型別規範的物件是引數
(c:: * -> * -> *),::後面是c的型別 - c 是 higher kind ,跟higher order function的定義差不多,它是接收型別,構造新型別的型別。這裡的 c 接收一個型別,再接收一個型別,就可以返回個型別。
id:: c a a表示 c 範疇上的 a 到 a 的箭頭.的意思 c 範疇上,如果喂一個 y 到 z 的箭頭,再喂一個 x 到 y 的箭頭,那麼就返回 x 到 z 的箭頭。
簡單吧hen nan ba?還沒有高數抽象呢。
1.1.1 Hask
Haskell 型別系統範疇叫做 Hask
在 Hask 範疇上:
- 東西是型別
- 箭頭是型別的變換,即
-> - id 就是 id 函式的型別
a -> a - compose 當然就是函式組合的型別
type Hask = (->)
instance Category (Hask:: * -> * -> *) where
(f . g) x = f (g x)
我們看見新的關鍵字 instance ,這表示 Hask 是 Type class Category 的例項型別,也就是說我們可以Hask的個構造器去真的構造一個型別
比如:
(->) a a
就構造了一個從a型別到a型別的的型別
構造出來的這個型別可以作為 id 函式的型別
id :: (->) a a
1.1.2 Duel
每個 Category還有一個映象,什麼都一樣,除了箭頭是反的
1.2 函子Functor
兩個範疇中間可以用叫 Functor 的東西來連線起來,簡稱 T。
Figure 2: Functor C D T, 從 C 到 D 範疇的Functor T
所以大部分把Functor/Monad比喻成盒子其實在定義上是錯的,雖然這樣比喻比較容易理解,在使用上問題也不大。但是,Functor只是從一個範疇到另一個範疇的對映關係而已。
- 範疇間 東西的 Functor 標記為
T(O) - 範疇間 箭頭的 Functor 標記為
T(~>) - 任何範疇C上存在一個 T 把所有的 O 和 ~> 都對映到自己,標記為id functor 1C
- 1C(O) = O
- 1C(~>) = ~>
class (Category c, Category d) => Functor c d t where
fmap :: c a b -> d (t a) (t b)
Functor c d t 這表示從範疇 c 到範疇 d 的一個 Functor t
如果把範疇 c 和 d 都限制到 Hask 範疇
class Functor (->) (->) t where
fmap :: (->) a b -> (->) (t a) (t b)
-> 在 Haskell 中是中綴型別構造器,所以是可以寫在中間的
這樣就會變成我們熟悉的 Funtor 的 Typeclass(把Functor 的第一第二個引數去掉的話)
class Functor t where
fmap :: (a -> b) -> (t a -> t b)
而 自函子endofunctor 就是這種連線相同範疇的 Functor,因為它從範疇 Hask 到達同樣的範疇 Hask
這裡的 fmap 就是 T(~>),在 Hask 範疇上,所以是 T(->), 這個箭頭是函式,所以也能表示成 T(f) 如果 f:: a -> b
1.3 Cat+貓+
當我們把一個Category看成一個object,functor看成箭頭,那麼我們又得到了一個Category,這種object是category的category我們叫它 – Cat
已經沒法講了,看 TODO 圖吧
1.4 自然變換Natural Transformations
Functor 是範疇間的對映,而 Functor 在 Cat 範疇又是個箭頭,所以,Functor間的對映,也就是 Cat 範疇上的 Functor,叫做 自然變換
Figure 3: Functor F和G,以及 F 到 G 的自然變化 η
所以範疇 c 上的函子 f 到 g 的自然變化就可以表示成
type Nat c f g = c (f a) (g a)
Hask 範疇上的自然變化就變成了
type NatHask f g = f a -> g a
有趣的是,自然轉換也滿足箭頭的概念,可以當成 functor 範疇上的箭頭,所以又可以定義出來一個 Functor Catergory
- 東西是函子
- 箭頭是自然變換
要成為範疇,還有兩點
- id 為 f a 到 f a 的自然變換
- 自然變換的組合
我們來梳理一下,已經不知道升了幾個維度了,我們假設型別是第一維度
- 一維: Hask, 東西是型別,箭頭是 ->
- 二維: Cat, 東西是 Hask, 箭頭是 Functor
- 三維: Functor範疇, 東西是Functor, 箭頭是自然變換
感覺到達三維已經是極限了,尼瑪還有完沒完了,每升一個維度還要起這麼多裝逼的名字,再升維度就要一臉懵逼了呢。雖然維度不算太高,但是已經不能用簡單的圖來描述了,所以需要引入 String Diagram。
1.5 String Diagram
String Diagram 的概念很簡單,就是點變線線變點。
當有了自然變換之後,沒法表示了呀,那原來的點和線都升一維度,變成線和麵,這樣,就騰出一個點來表示自然變換了。
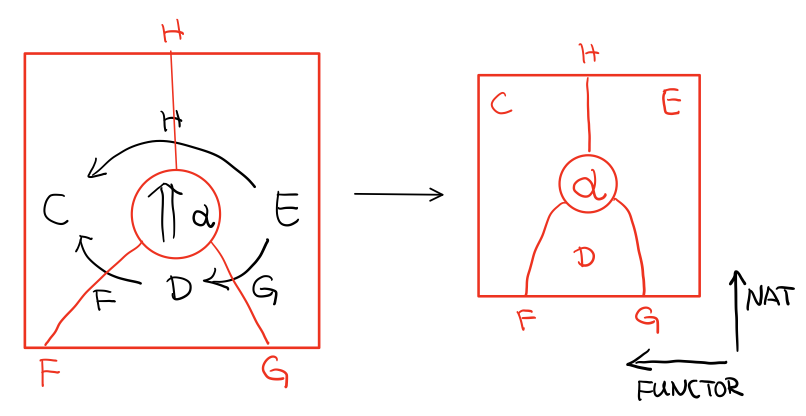
Figure 5: String Diagram:自然變換是點,Functor是線,範疇是面
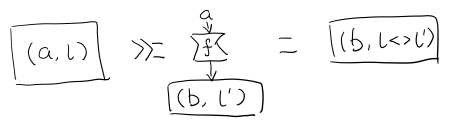
compose的方向是從右往左,從下到上。
1.6 Adjunction Functor 伴隨函子
範疇C和D直接有來有回的函子,為什麼要介紹這個,因為它直接可以推出 Monad
讓我們來看看什麼叫有來回。
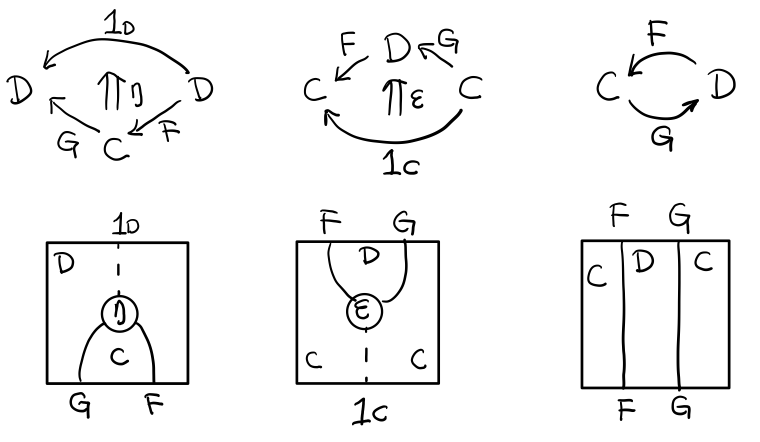
其中:
- 一個範疇 C 可以通過函子 G 到 D,再通過函子 F 回到 C,那麼 F 和 G 就是伴隨函子。
- η 是 GF 到 1D 的自然變換
- ε 是 1C 到 FG 的自然變換
同時根據同構的定義,G 與 F 是 同構 的。
同構指的是若是有
f :: a -> b
f':: b -> a
那麼 f 與 f' 同構,因為 f . f' = id = f' . f
伴隨函子的 FG 組合是 C 範疇的 id 函子 F . G = 1c
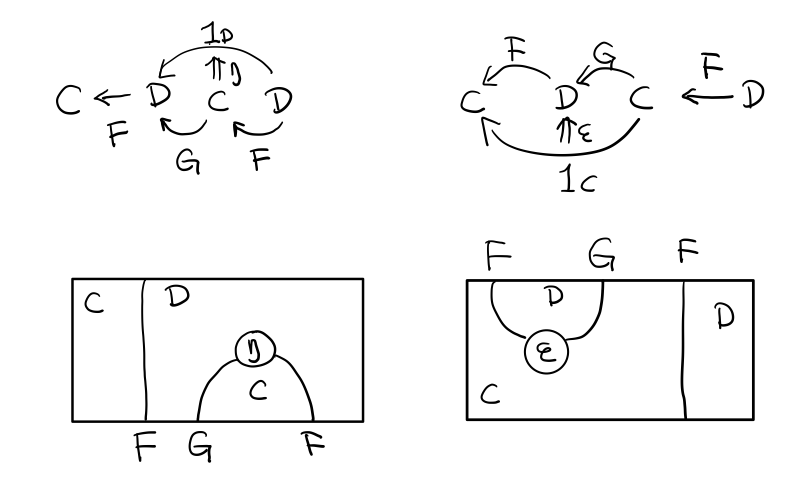
Figure 7: 伴隨函子的兩個Functor組合, 左側為 F η, 右側為 ε F
Functor 不僅橫著可以組合,豎著(自然變換維度)也是可以組合的,因為自然變換是 Functor 範疇的箭頭。
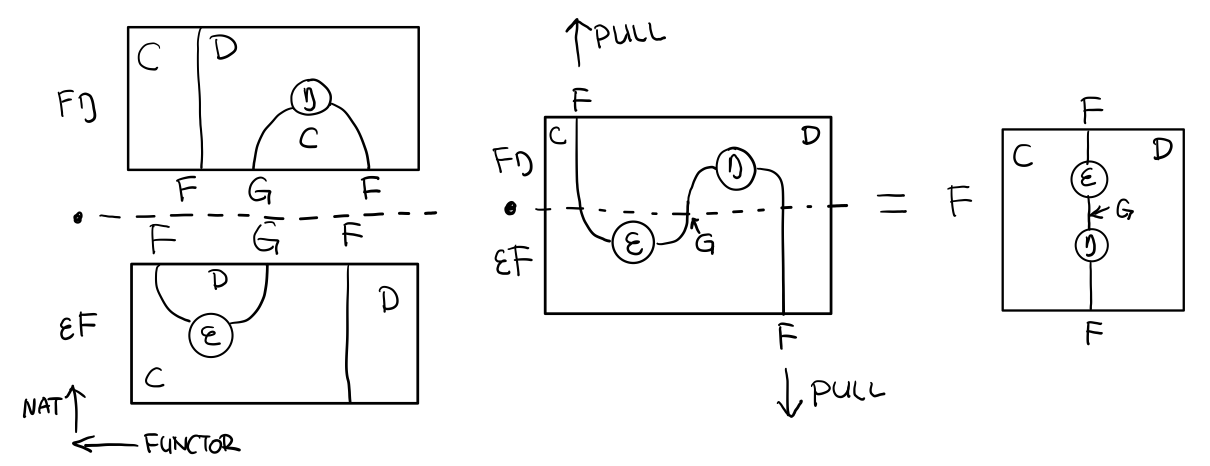
Figure 8: F η . ε F = F
當到組合 F η . ε F 得到一個彎彎曲曲的 F 時,我們可以拽著F的兩段一拉,就得到了直的 F。
String Diagram 神奇的地方是所有線都可以拉上下兩端,這個技巧非常有用,在之後的單子推導還需要用到。
1.7 從伴隨函子到 單子Monad
有了伴隨函子,很容易推出單子,讓我們先來看看什麼是單子
- 首先,它是一個 endofunctor T
- 有一個從 ic 到 T 的自然變化 η (eta)
- 有一個從 T2 到 T 的自然變化 μ (mu)
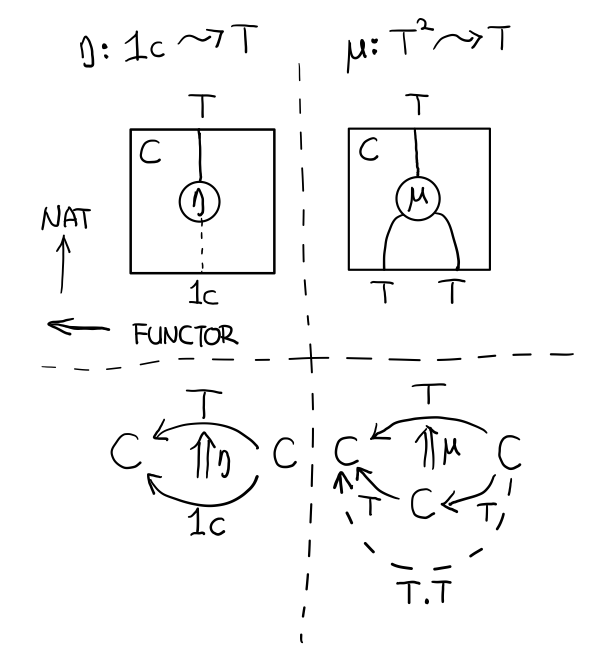
class Endofunctor c t => Monad c t where
eta :: c a (t a)
mu :: c (t (t a)) (t a)
同樣,把 c = Hask 替換進去,就得到更類似我們 Haskell 中 Monad 的定義
class Endofunctor m => Monad m where
eta :: a -> (m a)
mu :: m m a -> m a
要推出單子的 η 變換,只需要讓 FG = T
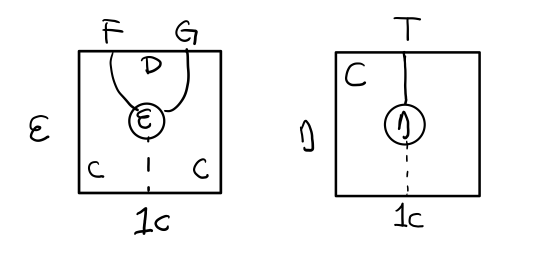
Figure 10: 伴隨函子的 ε 就是單子的 η
同樣的,當 FG = T, F η G 就可以變成 μ
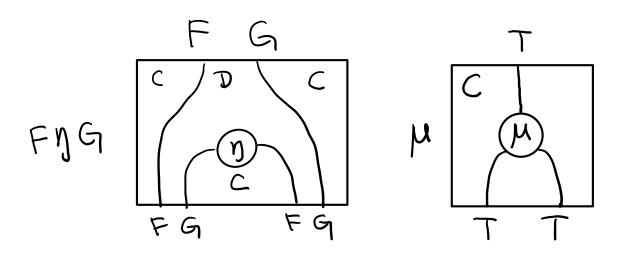
Figure 11: 伴隨函子的 F η G 是函子的 μ
1.7.1 三角等式
三角等式是指 μ . T η = T = μ . η T
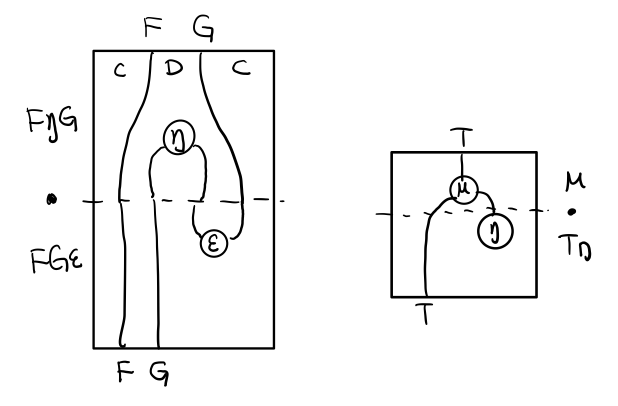
要推出三角等式只需要組合 F η G 和 ε F G
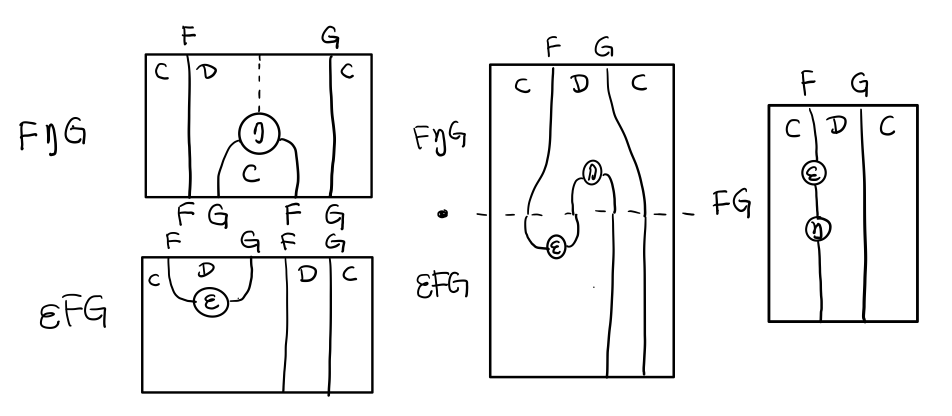
Figure 12: F η G . ε F G = F G
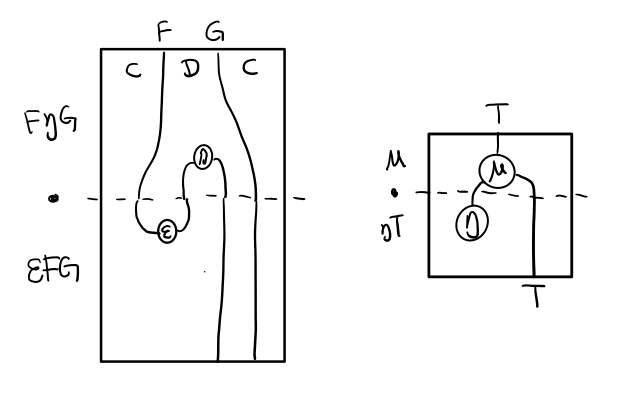
Figure 13: F η G . ε F G= F G 對應到Monad就是 μ . η T = T
換到程式碼上來說
class Endofunctor m => Monad m where
(mu . eta) m = m
同樣的,左右翻轉也成立
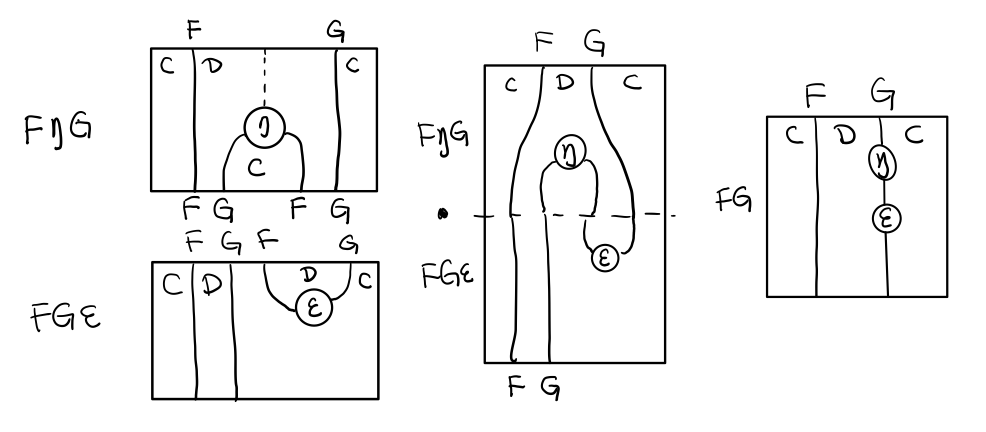
Figure 14: F η G . F G ε = F G
 T η 就是 fmap eta
T η 就是 fmap eta
(mu . fmap eta) m = m
如果把 mu . fmap 寫成 >>= , 就有了
m >>= eta = m
1.7.2 結合律
單子另一大定律是結合律,讓我們從伴隨函子推起
假設我們現在有函子 F η G 和 函子 F η G F G, compose 起來會變成 F η G . F η G F G 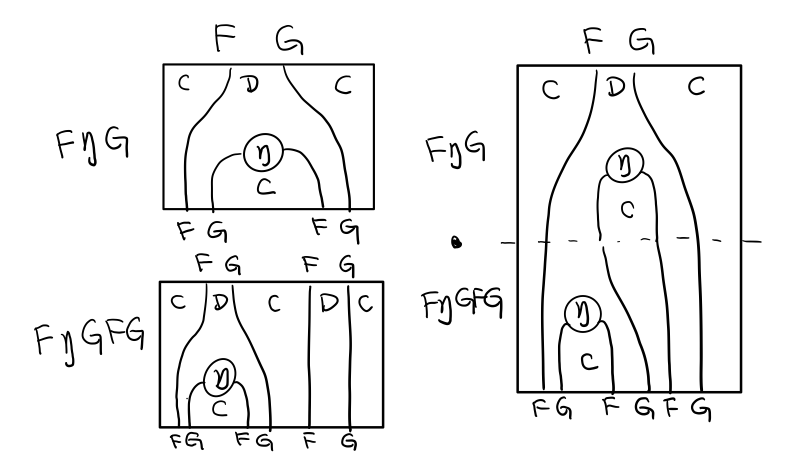
用 F G = T , F η G = μ 代換那麼就得到了單子的 μ . μ T 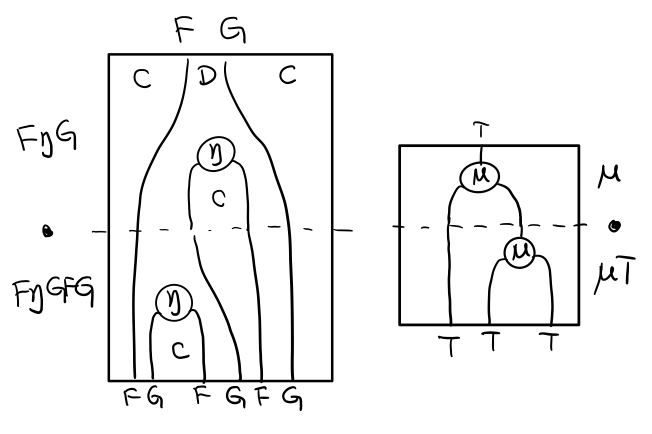
當組合 F η G 和 F G F μ G 後,會得到一個映象的圖 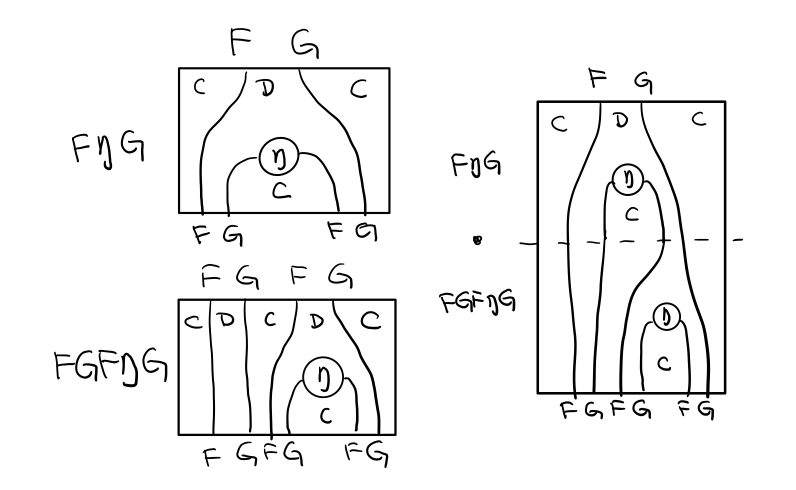
對應到單子的 μ . T μ
結合律是說 μ . μ T = μ . T μ , 即圖左右翻轉結果是相等的,為什麼呢?看單子的String Diagram 不太好看出來,我們來看伴隨函子
如果把左圖的左邊的 μ 往上挪一點,右邊的 μ 往下挪一點,是不是跟右圖就一樣了 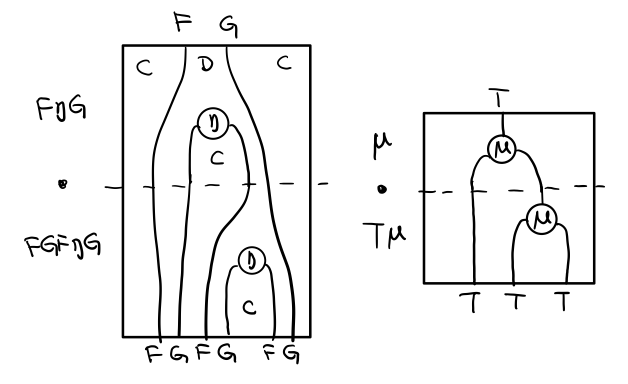
結合律反映到程式碼中就是
mu . fmap mu = mu . mu
程式碼很難看出結合在哪裡,因為正常的結合律應該是這樣的 (1+2)+3 = 1+(2+3),但是不想加法的維度不一樣,這裡說的是自然變換維度的結合,可以通過String Diagram 很清楚的看見結合的過程,即 μ 左邊的兩個T和先 μ 右邊兩個 T 是相等的。
1.8 Yoneda lemma / 米田共 米田引理
米田引理是說所有Functor f a 一定存在 embed 和 unembed,使得 f a和 (a -> b) -> F b isomorphic 同構
haskell還要先開啟 RankNTypes 的 feature
{-# LANGUAGE RankNTypes #-}
embed :: Functor f => f a -> (forall b . (a -> b) -> f b)
embed x f = fmap f x
unembed :: Functor f => (forall b . (a -> b) -> f b) -> f a
unembed f = f id
embed 可以把 functor f a 變成 (a -> b) -> f b
unembed 是反過來, (a -> b) -> f b 變成 f a
上個圖就明白了
Figure 15: 也就是說,圖中無論知道a->b 再加上任意一個 F x,都能推出另外一個 F
1.8.1 Rank N Type
- Monomorphic Rank 0 / 0級單態: t
- Polymorphic Rank 1 / 1級 變態 多型: forall a. a -> t
- Polymorphic Rank 2 / 2級多型: (forall a. a -> t) -> t
- Polymorphic Rank 3 / 3級多型: ((forall a. a -> t) -> t) -> t
看rank幾隻要數左邊 forall 的括號巢狀層數就好了
一級多型鎖定全部型別變化中的型別a
二級多型可以分別確定 a -> t 這個函式的型別多型
比如
rank2 :: (forall a. a -> a) -> (Bool, Char)
rank2 f = (f True, f 'a')
- f 在
f True時型別Boolean -> Boolean是符合forall a. a->a的 - 在
f 'a'時型別是Char -> Char也符合forall a. a->a
但是到 rank1 型別系統就懵逼了
rank1 :: forall a. (a -> a) -> (Bool, Char)
rank1 f = (f True, f 'a')
f 在 f True 是確定 a 是 Boolean,在rank1多型是時就確定了 a->a 的型別一定是 Boolean -> Boolean
所以到 f 'a' 型別就掛了。
1.9 Kleisli Catergory
Figure 16: 注意觀察大火箭 <=< 的軌跡(不知道dot為什麼會把這根線搞這麼又彎又騷的) 和 >>= 。所以 Kleisli 其實就是斜著走的一個範疇,但是 >>= 把它硬生生掰 彎直了。
Functor 的 Catergory 叫做 Functor Catergory,因為有箭頭 – 自然變換。Monad 也可以定義出來一個 Catergory(當然由於Monad是 Endofunctor,所以他也可以是 自函子範疇),叫做 Kleisli Catergory,那麼 Kleisli 的箭頭是什麼?
我們看定義,Kleisli Catergory
- 箭頭是 Kleisli 箭頭
a -> T b - 東西就是c範疇中的東西. 因為 a 和 b 都是 c 範疇上的, 由於T是自函子,所以 T b 也是 c 範疇的
看到圖上的 T ffmap f 和 μ 了沒?
f :: b -> T c
fmap f :: T b -> T^2 c
mu :: T^2 c -> T c
紫色的箭頭連起來(compose)就是 T f',所以,
tb >>= f = mu . fmap f tb
大火箭則是藍色箭頭的組合
(f <=< g) = mu . T f . g = mu . fmap f . g
而且大火箭就是 Kleisli 範疇的 compose
(<=<) :: Monad T => (b -> T c) -> (a -> T b) -> (a -> T c)
1.10 Summary
第一部分理論部分都講完了, 如果你讀到這裡還沒有被這些吊炸天亂七八糟的概念搞daze,接下來可以看看它到底跟我們程式設計有鳥關係呢?第二部分將介紹這些概念產生的一些實用的monad
2 第二部分:食用貓呢Practical Monads
第一部分理論部分都講完了, 如果你讀到這裡還沒有被這些吊炸天的概念搞daze,接下來可以看看它到底跟我們程式設計有鳥關係呢?
第二部分將介紹由這些概念產生的一些實用的monad instances,這些 monad 都通過同樣的抽象方式,解決了分離計算與副作用的工作。
最後一部分,我們還可以像 IO monad 一樣,通過 free 或者 Eff 自定義自己的計算,和可能帶副作用的直譯器。
2.1 Identity
這可能是最簡單的 monad 了。不包含任何計算
newtype Identity a = Identity { runIdentity :: a }
這裡使用 newtype 而不是 data 是因為 Identity 與 runIdentity 是 isomorphic (同構,忘了的話回去翻第一部分)
Identity :: a -> Identity a
runIdentity :: Identity a -> a
所以 runIdentity . Identity = id ,所以他們是同構的。
左邊的 Identity 是型別構造器, 接收型別 a 返回 Identity a 型別
如果 a 是 Int,那麼就得到一個 Identity Int 型別。
右邊的 Identity 是資料構造器,也就是構造值,比如 Identity 1 會構造出一個值,其型別為 Identity Int
大括號比較詭異,可以想象成給 a 一個 key,同過這個 key 可以把 a 取出來,比如
runIdentity (Identity 1)
會返回 1
Identity 可以實現 Functor 和 Monad,就得到 Identity functor 和 Identity monad
instance Functor Identity where
fmap f (Identity a) = Identity (f a)
instance Monad Identity where
return a = Identity a
Identity a >>= f = f a
可以看到 Identity 即是構造器,也是解構器,在模式匹配是可以 destructure 值。例如上面Functor 實現中的 fmap f (Identity a) , 假如fmap的是 Identity 1, 那麼這個模式匹配到 (Identity a) 時會把 1 放到 a的位置。
Identity 看起來什麼也沒有幹,就跟 identity 函式一樣,但是在後面講到 State monad時你會發現他的價值。
2.2 Maybe
這是一個超級簡單的 Monad,首先,需要定義這個一個 代數資料型別Algebra Data Type(ADT)
data Maybe a = Just a | Nothing
Haskell中定義一個ADT十分簡單,不像Scala那麼囉嗦。左邊是型別構造器,右邊有資料構造器,你會發現有一根豎線 | , 它分隔著兩個構造器
- Just
- Nothing
其中 a (一定要小寫)可以是任意型別
所以 Just 1 會得到一個 Num a => Mabye a 型別(意思就是 Maybe a 但是 a 的型別約束為 Num ), Nothing 也會得到一個 Maybe a 只不過 a 沒有型別約束。
總之我們有了構造器可以構造出 Maybe 型別,而這個型別能做的事情,就要取決它實現了哪些 class 的 instance 了。比如它可以是一個 Functor
instance Functor Maybe where
fmap f (Just a) = Just (f a)
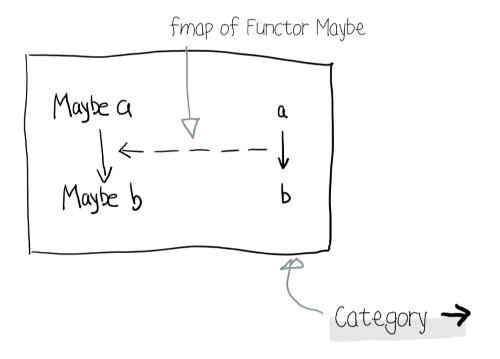
Figure 17: fmap :: (a -> b) -> f a -> f b
然後,還實現 Monad
instance Monad Maybe where
return a = Just a
(Just a) >>= f = f a
Nothing >>= f = Nothing
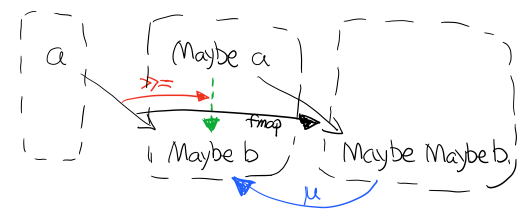
Figure 18: 還記得第一部分提到的 Kleisli 範疇嗎?
Maybe 有用在於能合適的處理 偏函式Partial Function 的返回值。偏函式相對於全函式Total Function,是指只能對部分輸入返回輸出的函式。
比如一個取陣列某一位上的值的函式,就是偏函式,因為假設你想取第4位的值,但不是所有陣列長度都大於4,就會有獲取不了的尷尬情況。
[1,2,3] !! 4
如果使用 Maybe 把偏函式處理不了的輸入都返回成 Nothing,這樣結果依然保持 Maybe 型別,不影響後面的計算。
2.3 Either
Either 的定義也很簡單
data Either a b = Left a | Right b
2.3.1 Product & Coproduct
看過第一部分應該還能記得有一個東西叫 Duel,所以見到如果範疇上有 Coproduct 那麼肯定在duel範疇上會有同樣的東西叫 Product。
那麼我們先來看看什麼是 Coproduct
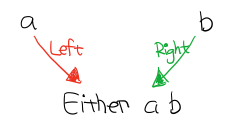
Figure 19: Coproduct
像這樣,能通過兩個箭頭到達同一個東西,就是 Coproduct。這裡箭頭 Left 能讓 a 到 Either a b , 箭頭 Right 也能讓 b 到達 Either a b
有意思的是還肯定存在一個 Coproduct 和 箭頭,使得下圖成立 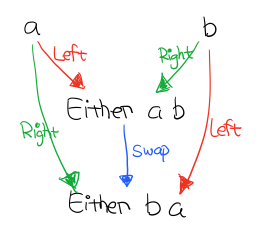
箭頭反過來,就是 Product, 比如 Tuple
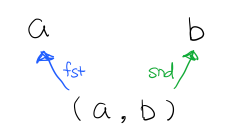
Figure 20: Product
Tuple 的 fst 箭頭能讓 (a, b) 到達 a 物件,而箭頭 snd 能讓其到達 b物件。
2.3.2 Either Monad
確切的說,Either 不是 monad, Either a 才是。還記得 monad 的 class 定義嗎?
class Endofunctor m => Monad m where
eta :: a -> (m a)
mu :: m m a -> m a
所以 m 必須是個 Endofunctor,也就是要滿足Functor
class Functor t where
fmap :: (a -> b) -> (t a -> t b)
t a 的 kind 是 *,所以 t 必須是 kind * -> * 也就是說,m 必須是接收一個型別引數的型別構造器
而 Either 的 kind 是 * -> * -> *, Either a 才是 * -> *
所以只能定義 Either a 的 Monad
instance Monad (Either a) where
Left l >>= _ = Left l
Right r >>= k = k r
很明顯的,>>= 任何函式到左邊Left 都不會改變,只有 >>= 右邊才能產生新的計算。
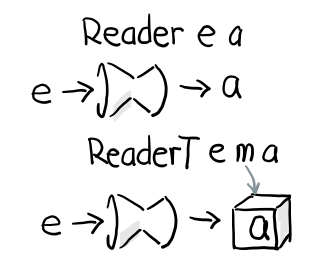
2.4 Reader
Reader 的作用是給一個計算喂資料。
在描述計算的時候,並不需要關心輸入時什麼,只需要 asks 就可以拿到輸入值
而真正的輸入,會在執行計算時給予。
跟 Identity 一樣,我們用 newtype 來定義一個同構的 Reader 型別
newtype Reader e a = Reader { runReader :: (e -> a) }
其中
- e 是輸入
- a 是結果
- 構造 Reader 型別需要確定 輸入的型別 e 與輸出的型別 a
runReader的型別是runReader:: (Reader e a) -> (e -> a)
也就是說在描述完一個 Reader 的計算後,使用 runReader 可以得到一個 e -> a 的函式,使用這個函式,就可以接收輸入,通過構造好的計算,算出結果 a 返回。
那麼,讓我們來實現 Reader 的 monad instance,就可以描述一個可以 ask 的計算了。
instance Monad (Reader e) where
return a = Reader $ \_ -> a
(Reader g) >>= f = Reader $ \e -> runReader (f (g e)) e
跟Either一樣,我們只能定義 Reader e 的 monad instance。
注意這裡的
- f 型別是
(a -> Reader e a) - g 其實就是是 destructure 出來的 runReader,也就是 e -> a
- 所以 (g e) 返回 a
- f (g e) 就是
Reader e a - 再 run 一把最後得到 a
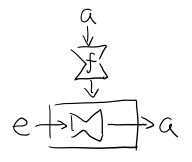
Figure 21: f 函式,接收 a 返回一個 從 e 到 a 的 Reader
讓我們來看看如何使用 Reader
import Control.Monad.Reader
data Environment = Env
{ fistName :: String
, lastName :: String
} deriving (Show)
helloworld :: Reader Environment String
helloworld = do
f <- asks firstName
l <- asks lastName
return "Hello " ++ f ++ l
runHelloworld :: String
runHelloworld = runReader helloworld $ Env "Jichao" "Ouyang"
這段程式碼很簡單,helloworld 負責打招呼,也就是在名字前面加個 "Hello",而跟誰打招呼,這個函式並不關心,而單純的是向 Environment 問asks 就好。
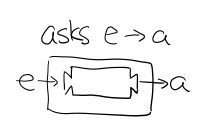
Figure 22: asks 可以將 e -> a 的函式變換成 Reader e a
在執行時,可以提供給 Reader 的輸入 Env fistname lastname。 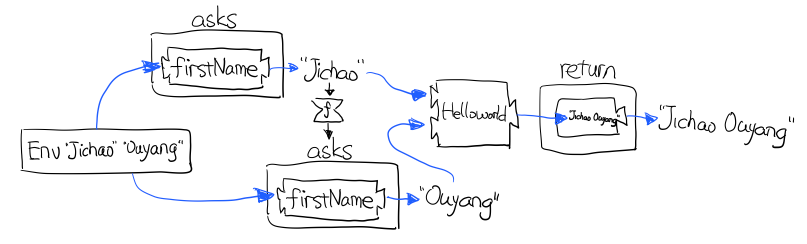
2.4.1 do notation
這可能是你第一次見到 do 和 <-. 如果不是,隨意跳過這節。
- do 中所有 <- 的右邊都是
Reader Environment String型別 - do 中的 return 返回型別也必須為
Reader Environment String asks firstName返回的是Reader Environment String型別,<-可以理解成吧 monadReader Environment的內容放到左邊的 f, 所以 f 的型別是 String。
看起來像命令式的語句,其實只是 >>= 的語法糖,但是明顯用do可讀性要高很多。
helloworld = (asks firstName) >>=
\f -> (asks lastName) >>=
\l -> return "Hello " ++ f ++ l
2.5 Writer
除了返回值,計算會需要產生一些額外的資料,比如 log
此時就需要一個 Writter,其返回值會是一個這樣 (result, log) 的 tuple
限制是 log 的型別必須是個 含么半群monoid
example :: Writer String String
example = do
tell "How are you?"
tell "I'm fine thank you, and you?"
return "Hehe Da~"
output :: (String, String)
output = runWriter example
-- ("Hehe Da~", "How are you?I'm fine thank you, and you?")
Writer 的定義更簡單
newtype Writer l a = Writer { runWriter :: (a,l) }
裡面只是一個 tuple 而已
- w 是 log
- a 是 返回值
看看如何實現 Writer monad
instance (Monoid w) => Monad (Writer w) where
return a = Writer (a,mempty)
(Writer (a,l)) >>= f = let (a',l') = runWriter $ f a in
Writer (a',l `mappend` l')
- return 不會有任何 log,l 是 monoid 的 mempty
- f 的型別為
a -> Writer l a runWriter $ f a返回(a, l)
所以在 >>= 時,我們先把 f a 返回的 Writer run了,然後把兩次 log mappend 起來。 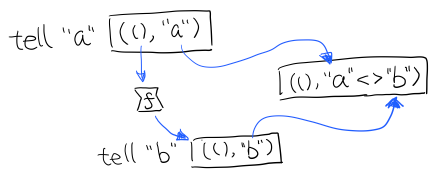
2.6 State
跟名字就看得出來 State monad 是為了處理狀態。雖然函數語言程式設計不應該有狀態,不然會引用透明性。但是,state monad並不是在計算過程中修改狀態,而是通過描述這種變化,然後需要時在執行返回最終結果。這一點跟 Reader 和 Writer 這兩個看起來是副作用的 IO 是一樣的。
先看下 State 型別的定義
newtype State s a = State { runState :: s -> (a, s) }
可以看到 State 只包含一個 從舊狀態 s 到新狀態 s 和返回值 a 的 Tuple 的函式。
通過實現 Monad,State 就可以實現指令式程式設計中的變數的功能。
instance Monad (State s) where
return a = State $ \s -> (a,s)
(State x) >>= f = State $ \s -> let (v,s') = x s in
runState (f v) s'
return 很簡單,就不用解釋了。
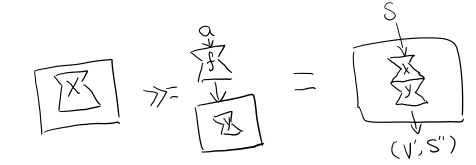
x 型別是 s -> (a, s) ,所以 x s 之後會返回 結果和狀態。也就是運行當前 State,把結果 v 傳給函式 f,返回的 State 再接著上次狀態執行。
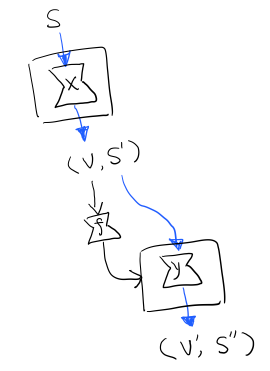
Figure 25: State x >>= f 後runState的資料流(啊啊啊,畫歪了,感覺需要脈動一下)
使用起來也很方便,State 提供 get put moidfy 三個方便的函式可以生成修改狀態的State monad
import Control.Monad.Trans.State.Strict
test :: State Int Int
test = do
a <- get
modify (+1)
b <- get
return (a + b)
main = print $ show $ runState test 3
-- (7, 4)
2.7 Validation
如果你有注意到,前面的 Either 可以用在處理錯誤和正確的路徑分支,但是問題是錯誤只發生一次。
Validation 沒有在標準庫中,但是我覺得好有用啊,你可以在 ekmett 的 github 中找到原始碼
想象一下這種場景,使用者提交一個表單,我們需要對每一個field進行驗證,如果有錯誤,需要把錯誤的哪幾個field的錯誤訊息返回。顯然如果使用 Either 來做,只能返回第一個field的錯誤資訊,後面的計算都會被跳過。
針對這種情況, Validation 更適合
data Validation e a = Failure e | Success a
ADT定義看起來跟 Either 是一樣的,不同的是 左邊Left Failure 是 含么半群Monoid
2.7.1 含么半群Monoid
monoid 首先得是 半群Semigroup ,然後再 含么。
class Semigroup a where
(<>) :: a -> a -> a
(<>) = mappend
半群非常簡單,只要是可以 <> (mappend) 的型別就是了。
含么只需要有一個 mempty 的 么元就行
class Monoid a where
mempty :: a
mappend :: a -> a -> a
比如 List 就是 Semigroup
instance Semigroup [a] where
(<>) = (++)
也是 Monoid
instance Monoid [a] where
mempty = []
mappend = (++)
Monoid 的 <> 滿足:
- mempty <> a = a
- a <> b <> c = a <> (b <> c)
2.7.2 回到 Validation
現在讓 Failure e 滿足 Monoid,就可以 mappend 錯誤資訊了。
instance Semigroup e => Semigroup (Validation e a) where
Failure e1 <> Failure e2 = Failure (e1 <> e2)
Failure _ <> Success a2 = Success a2
Success a1 <> Failure _ = Success a1
Success a1 <> Success _ = Success a1
下來,我們用一個簡單的例子來看看 Validation 與 Either 有什麼區別。
假設我們有一個form,需要輸入姓名與電話,驗證需要姓名是非空而電話是11位數字。
首先,我們需要有一個函式去建立包含姓名和電話的model
data Info = Info {name: String, phone: String} deriving Show
然後我們需要驗證函式
notEmpty :: String -> String -> Validation [String] String
notEmpty desc "" = Failure [desc <> " cannot be empty!"]
notEmpty _ field = Success field
notEmpty 檢查字元是否為空,如果是空返回 Failure 包含錯誤資訊,若是非空則返回 Success 包含 field
同樣的可以建立 11位數字的驗證函式
phoneNumberLength :: String -> String -> Validation [String] String
phoneNumberLength desc field | (length field) == 11 = Success field
| otherwise = Failure [desc <> "'s length is not 11"]
實現 Validation 的 Applicative instance,這樣就可以把函式呼叫lift成帶有驗證的 Applicative
instance Semigroup e => Applicative (Validation e) where
pure = Success
Failure e1 <*> Failure e2 = Failure e1 <> Failure e2
Failure e1 <*> Success _ = Failure e1
Success _ <*> Failure e2 = Failure e2
Success f <*> Success a = Success (f a)
- 失敗應用到失敗會 concat 起來
- 失敗跟應用或被成功應用還是失敗
- 只有成功應用到成功才能成功,這很符合驗證的邏輯,一旦驗證中發生任何錯誤,都應該返回失敗。
createInfo :: String -> String -> Validation [String] Info
createInfo name phone = Info <$> notEmpty "name" name <*> phoneNumberLength "phone" phone
現在我們就可以使用帶validation的 createInfo 來安全的建立 Info 了
createInfo "jichao" "12345678910" -- Success Info "jichao" "12345678910"
createInfo "" "123" -- Failure ["name cannot be empty!", "phone's length is not 11"]
2.8 Cont
Cont 是 Continuation Passing StyleCPS 的 monad,也就是說,它是包含 cps 計算 monad。
先看一下什麼是 CPS,比如有一個加法
add :: Int -> Int -> Int
add = (+)
但是如果你想在演算法加法後,能夠繼續進行一個其他的計算,那麼就可以寫一個 cps版本的加法
addCPS :: Int -> Int -> (Int -> r) -> r
addCPS a b k = k (a + b)
非常簡單,現在我們可以看看為什麼需要一個 Cont monad 來包住 CPS 計算,首先,來看 ADT 定義
newtype Cont r a = Cont { runCont :: ((a -> r) -> r) }
又是一個同構的型別,Cont 構造器只需要一個 runCount,也就是讓他能繼續計算的一個函式。
完了之後來把之前的 addCPS 改成 Cont
add :: Int -> Int -> Cont k Int
add a b = return (a + b)
注意到 addCPS 接收到 a 和 b 之後返回的型別是 (Int -> r) -> r ,而 Cont 版本的 add 返回 Cont k Int
明顯構造 Cont k Int 也正是需要 (Int -> r) -> r ,所以 Cont 就是算了 k 的抽象了。
instance Monad (Cont r) where
return a = Cont ($ a)
m >>= k = Cont $ \c -> runCont m $ \a -> runCont (k a) c
($ a) 比較有意思, 我們都知道 f $ g a 其實就是 f(g a), 所以 $ 其實就是一個 apply 左邊的函式到右邊表示式的中綴函式, 如果寫成字首則是 ($ (g a) f). 是反的是因為 $ 是有結合, 需要右邊表示式先求值, 所以只給一個 a 就相當於 ($ a) = \f -> f a
回到 Monad Cont…
ob-haskell
3 第三部分:搞基貓呢Advanced Monads
第二部分介紹了一些實用的monad instances,這些 monad 都通過同樣的抽象方式,解決了分離計算與副作用的工作。
通過它們可以解決大多數的基本問題,但是正對於複雜業務邏輯,我們可能還需要一些更高階的 monad 或者 pattern。
當有了第一部分的理論基礎和第二部分的實踐,這部分要介紹的貓呢其實並不是很搞基。通過這一部分介紹的搞基貓呢,我們還可以像 IO monad 一樣,通過 free 或者 Eff 自定義自己的計算,和可能帶副作用的直譯器。
3.1 RWS
RWS 是縮寫 Reader Writer State monad, 所以明顯是三個monad的合體。如果已經忘記 Reader Writer 或者 State,請到第二部分複習一下。
一旦把三個 monad 合體,意味著可以在同一個 monad 使用三個 monad 的方法,比如,可以同時使用 Reader 的 ask, State 的 get, put, 和 Writer 的 tell
readWriteState = do
e <- ask
a <- get
let res = a + e
put res
tell [res]
return res
runRWS readWriteState 1 2
-- (3 3 [3])
注意到跟 Reader 和 State 一樣,run的時候輸入初始值
其中 1 為 Reader 的值,2 為 State 的
3.2 Monad Transform
你會發現 RWS 一起用挺好的,能讀能寫能打 log,但是已經固定好搭配了,只能是 RWS ,如果我還想加入其它的 Monad,該怎麼辦呢?
這時候,簡單的解決方案是加個 T,比如對於 Reader,我們有 ReaderT,RWS,也有對應的 RWST。其中 T 代表 Transform。
3.2.1 ReaderT
讓我來通過簡單的 ReaderT 來解釋到底什麼是 T 吧, 首先跟 Reader 一樣我們有個 runReaderT
newtype ReaderT e m a = ReaderT { runReaderT :: e -> m a }
比較一下 Reader 的定義
newtype Reader e a = Reader { runReader :: (e -> a) }
有沒有發現多了一個 m, 也就是說, runReader e 會返回 a, 但是 runReaderT e 則會返回 m a
instance (Monad m) => Monad (ReaderT e m) where
return = lift . return
r >>= k = ReaderT $ \ e -> do
a <- runReaderT r e
runReaderT (k a) e
再看看 monad 的實現, 也是一樣的, 先 run 一下 r e 得到結果 a, 應用函式 k 到 a, 再 run 一把.
問題是, 這裡的 return 裡面的 lift 是哪來的?
instance MonadTrans (ReaderT e) where
lift m = ReaderT (const m)
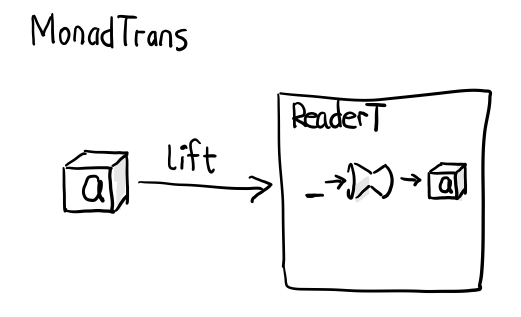
這個函式 lift 被定義在 MonadTrans 的例項中, 簡單的把 m 放到 ReaderT 結果中.
例如, lift (Just 1) 會得到 ReaderT, 其中 e 隨意, m 為 Maybe Num
重點需要體會的是, Reader 可以越過 Maybe 直接操作到 Num, 完了再包回來.
有了 ReaderT, 搭配 Id Monad 就很容易創建出來 Reader Monad
type Reader r a= ReaderT r Identity a
越過 Id read 到 Id 內部, 完了再用 Id 包回來, 不就是 Reader 了麼
ReaderT { runReaderT :: r -> Identity a }
-- Identity a is a
ReaderT { runReaderT :: r -> a }
3.3 Alternative
class Applicative f => Alternative f where
empty :: f a
(<|>) :: f a -> f a -> f a
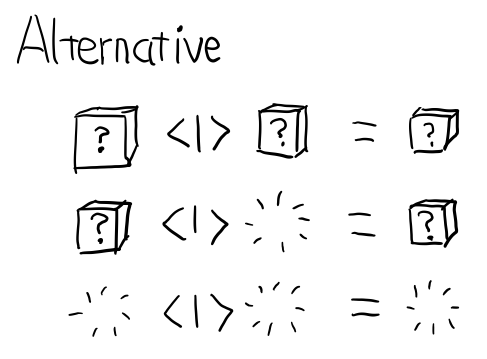
其實就是 Applicative 的 或
比如:
Just 1 <|> Just 2 -- Just 1
Just 1 <|> Nothing -- Just 1
Nothing <|> Just 1 -- Just 1
Nothing <|> Nothing -- Nothing
3.4 MonadPlus
這跟 Alternative 是一毛一樣的, 只是限制的更細, 必須是 Monad才行
class (Alternative m, Monad m) => MonadPlus m where
mzero :: m a
mzero = empty
mplus :: m a -> m a -> m a
mplus = (<|>)
看, 實現中直接就呼叫了 Alternative 的 empty 和 <|>
3.5 ST Monad
ST Monad 跟 State Monad 的功能有些像, 不過更厲害的是, 他不是 immutable 的, 而是 "immutable" 的在原地做修改. 改完之後 runST 又然他回到了 immutable 的 Haskell 世界.
sumST :: Num a => [a] -> a
sumST xs = runST $ do -- do 後面的事情會是不錯的記憶體操作, runST 可以把它拉會純的世界
n <- newSTRef 0 -- 在記憶體中建立一塊並指到 STRef
forM_ xs $ \x -> do -- 這跟命令式的for迴圈改寫變數是一毛一樣的
modifySTRef n (+x)
readSTRef n -- 返回改完之後的 n 的值
3.6 Free Monad
上一章說過的 RWS Monad 畢竟是固定搭配,當你的業務需要更多的 Monad 來表示 Effect 時,我們就需要有那麼個小豬手幫我們定義自己的 Monad。
那就是 Free, Free 可以將任意 datatype lift 成為 Monad
3.6.1 Free
先看 Free 什麼定義:
data Free f a = Roll (f (Free f a)) | Return a
其中 f 就是你業務需要的 effect 型別, a 是這個 effect 所產生的返回值型別。
右邊兩種建構函式,如果把 Role 改成 Cons, Return 改成 Nil 的話, 是不是跟 List 其實是 同構isomophic 的呢? 所以如果想象成 List, 那麼 f 在這裡就相當於 List 中的一個元素.
到那時, >>= 的操作又跟 List 略有不同, 我們都知道 >>= 會把每一個元素 map 成 List, 然後 flatten, 但 Free 其實是用來構建 順序的 effect 的, 所以:
instance Functor f => Monad (Free f) where
return a = Return a
Return a >>= fn = fn a
Roll ffa >>= fn = Roll $ fmap (>>= fn) ffa
你會發現 >>= 會遞迴的 fmap 到 Roll 上, 直到最後一個 Return.
如果你有一個
data Eff a = Eff1 a | Eff2 a | Eff3 a
program = Roll Eff1 (Roll Eff2 (Return Int))
>>= 一個函式 Int => Free Eff3 Int 到 program 會是什麼?
Roll Eff1 (Roll Eff2 (Roll Eff3 (Return Int))
真的這麼神奇嗎?
細心的你可能早都發現了 Eff 這貨必須是個 Functor 才行. 那我們如何隨便定義一個 data Eff 直接能生成 Functor Eff 的例項呢?
3.6.2 Coyoneda
希望你還依然記得第一部分的米田 共 引理
data CoYoneda f a = forall b. CoYoneda (b -> a) (f b)
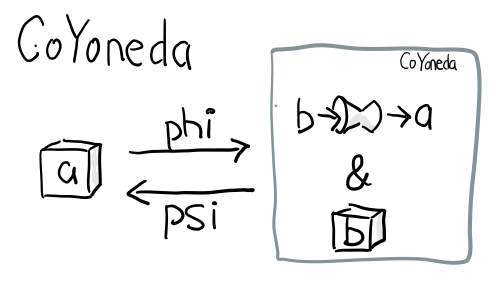
事實上很簡單可以把任何 f 變成 CoYoneda f
phi :: f a -> CoYoneda f a
phi fa = CoYoneda id fa
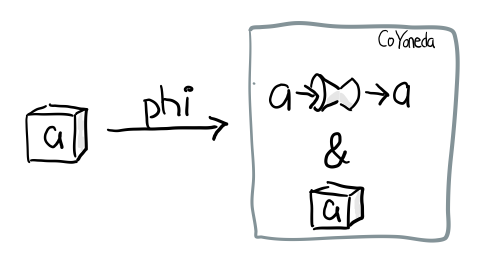
訣竅就是 id, 也就是你把 b 變成 a, 再把 fa 放到 CoYoneda 裡就好了
當 f 是 Functor 時, 又可以把 CoYoneda 變成 f
psi :: Functor f => CoYoneda f a -> f a
psi (CoYoneda g fa) = fmap g fa
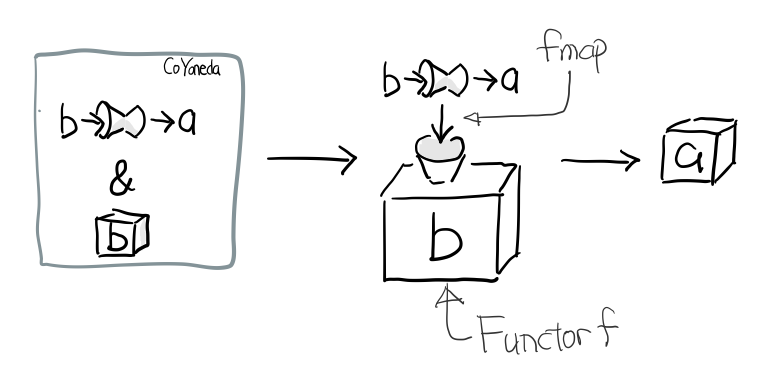
反過來的這個不重要, 重要的是 phi, 因為如果你可以把任何 f 變成 CoYoneda f, 而 CoYoneda f 又是 Functor, 我們不就免費得到一個 Functor?
instance Functor (Coyoneda f) where
fmap f (Coyoneda g fb) = Coyoneda (f . g) fb
3.6.3 Free Functor
比如我們的 Eff 就可以直接通過 phi 變成 CoYoneda Eff, 從而得到免費的 Functor
data Eff a = Eff1 a | Eff2 a | Eff3 a
program = Roll (phi (Eff1 (Roll (phi (Eff2 (Return Int))))))
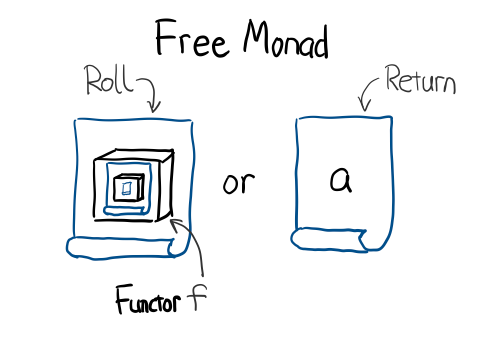
3.6.4 Interpreter
構造完一個 free program 後,我們得到的是一個巢狀的資料結構, 當我們需要 run 這個 program 時, 我們需要 foldMap 一個 Interpreter 去一層層撥開 這個 free program.
foldMap :: Monad m => (forall x . f x -> m x) -> Free f a -> m a
foldMap _ (Return a) = return a
foldMap f (Roll a) = f a >>= foldMap f