
淺析Postgres中的併發控制(Concurrency Control)與事務特性(下)
上文我們討論了PostgreSQL的MVCC相關的基礎知識以及實現機制。關於PostgreSQL中的MVCC,我們只講了元組可見性的問題,還剩下兩個問題沒講。一個是"Lost Update"問題,另一個是PostgreSQL中的序列化快照隔離機制(SSI,Serializable Snapshot Isolation)。今天我們就來繼續討論。
3.2 Lost Update
所謂"Lost Update"就是寫寫衝突。當兩個併發事務同時更新同一條資料時發生。"Lost Update"必須在REPEATABLE READ 和 SERIALIZABLE 隔離級別上被避免,即拒絕併發地更新同一條資料。下面我們看看在PostgreSQL上如何處理"Lost Update"
有關PostgreSQL的UPDATE操作,我們可以看看ExecUpdate()這個函式。然而今天我們不講具體的函式,我們形而上一點。只從理論出發。我們只討論下UPDATE執行時的情形,這意味著,我們不討論什麼觸發器啊,查詢重寫這些雜七雜八的,只看最"乾淨"的UPDATE操作。而且,我們討論的是兩個併發事務的UPDATE操作。
請看下圖,下圖顯示了兩個併發事務中UPDATE同一個tuple時的處理。
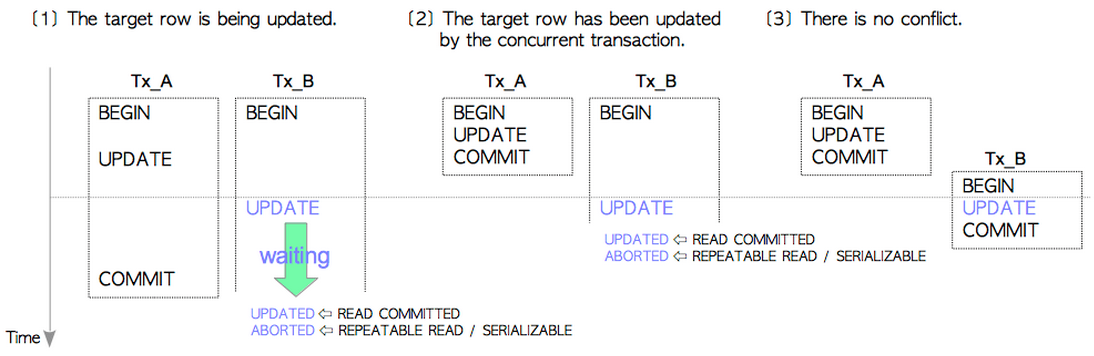
- [1]目標tuple處於正在更新的狀態
我們看到Tx_A和Tx_B在併發執行,Tx_A先更新了tuple,這時Tx_B準備去更新tuple,發現Tx_A更新了tuple,但是還沒有提交。於是,Tx_B處於等待狀態,等待Tx_A結束(commit或者abort)。
當Tx_A提交時,Tx_B解除等待狀態,準備更新tuple,這時分兩個情況:如果Tx_B的隔離級別是READ COMMITTED,那麼OK,Tx_B進行UPDATE(可以看出,此時發生了Lost Update)。如果Tx_B的隔離級別是REPEATABLE READ或者是SERIALIZABLE,那麼Tx_B會立即被abort,放棄更新。從而避免了Lost Update的發生。
當Tx_A和Tx_B的隔離級別都為READ COMMITTED時的例子:
| Tx_A | Tx_B |
|---|---|
| postgres=# START TRANSACTION ISOLATION LEVEL READ COMMITTED ;START TRANSACTIONpostgres=# update test set b = b+1 where a =1;UPDATE 1postgres=# commit;COMMIT | postgres=# START TRANSACTION ISOLATION LEVEL READ COMMITTED;START TRANSACTIONpostgres=# update test set b = b+1;↓↓this transaction is being blocked↓UPDATE 1 |
當Tx_A的隔離級別為READ COMMITTED,Tx_B的隔離級別為REPEATABLE READ時的例子:
| Tx_A | Tx_B |
|---|---|
| postgres=# START TRANSACTION ISOLATION LEVEL READ COMMITTED ;START TRANSACTIONpostgres=# update test set b = b+1 where a =1;UPDATE 1postgres=# commit;COMMIT | postgres=# START TRANSACTION ISOLATION LEVEL REPEATABLE READ;START TRANSACTIONpostgres=# update test set b = b+1;↓↓this transaction is being blocked↓ERROR:couldn't serialize access due to concurrent update |
- [2]目標tuple已經被併發的事務更新
我們看到Tx_A和Tx_B在併發執行,Tx_A先更新了tuple並且已經commit,Tx_B再去更新tuple時發現它已經被更新過了並且已經提交。如果Tx_B的隔離級別是READ COMMITTED,根據我們前面說的,,Tx_B在執行UPDATE前會重新獲取snapshot,發現Tx_A的這次更新對於Tx_B是可見的,因此Tx_B繼續更新Tx_A更新過得元組(Lost Update)。而如果Tx_B的隔離級別是REPEATABLE READ或者是SERIALIZABLE,那麼顯然我們會終止當前事務來避免Lost Update。
當Tx_A的隔離級別為READ COMMITTED,Tx_B的隔離級別為REPEATABLE READ時的例子:
| Tx_A | Tx_B |
|---|---|
| postgres=# START TRANSACTION ISOLATION LEVEL READ COMMITTED ;START TRANSACTIONpostgres=# update test set b = b+1 where a =1;UPDATE 1postgres=# commit;COMMIT | postgres=# START TRANSACTION ISOLATION LEVEL REPEATABLE READ;START TRANSACTIONpostgres=# select * from test ; a b---+--- 1 5(1 row)postgres=# update test set b = b+1ERROR: could not serialize access due to concurrent update |
- [3]更新無衝突
這個很顯然,沒有衝突就沒有傷害。Tx_A和Tx_B照常更新,不會有Lost Update。
從上面我們也可以看出,在使用SI(Snapshot Isolation)機制時,兩個併發事務同時更新一條記錄時,先更新的那一方獲得更新的優先權。但是在下面提到的SSI機制中會有所不同,先提交的事務獲得更新的優先權。
3.3 SSI(Serializable Snapshot Isolation)
SSI,可序列化快照隔離,是PostgreSQL在9.1之後,為了實現真正的SERIALIZABLE(可序列化)隔離級別而引入的。
對於SERIALIZABLE隔離級別,官方介紹如下:
可序列化隔離級別提供了最嚴格的事務隔離。這個級別為所有已提交事務模擬序列事務執行;就好像事務被按照序列一個接著另一個被執行,而不是並行地被執行。但是,和可重複讀級別相似,使用這個級別的應用必須準備好因為序列化失敗而重試事務。事實上,這個隔離級別完全像可重複讀一樣地工作,除了它會監視一些條件,這些條件可能導致一個可序列化事務的併發集合的執行產生的行為與這些事務所有可能的序列化(一次一個)執行不一致。這種監控不會引入超出可重複讀之外的阻塞,但是監控會產生一些負荷,並且對那些可能導致序列化異常的條件的檢測將觸發一次序列化失敗。講的比較繁瑣,我的理解是:
1.只針對隔離級別為SERIALIZABLE的事務;
2.併發的SERIALIZABLE事務與按某一個順序單獨的一個一個執行的結果相同。條件1很好理解,系統只判斷併發的SERIALIZABLE的事務之間的衝突; 條件2我的理解就是併發的SERIALIZABLE的事務不能同時修改和讀取同一個資料,否則由併發執行和先後按序列執行就會不一致。
但是這個不能同時修改和讀取同一個資料要限制在多大的粒度呢? 我們分情況討論下。
- [1] 讀寫同一條資料
似乎沒啥問題嘛,根據前面的論述,這裡的一致性在REPEATABLE READ階段就保證了,不會有問題。
以此類推,我們同時讀寫2,3,4....n條資料,沒問題。
- [2]讀寫閉環
啥是讀寫閉環?這我我造的概念,類似於作業系統中的死鎖,即事務Tx_A讀tuple1,更新tuple2,而Tx_B恰恰相反,讀tuple2, 更新tuple1.
我們假設事務開始前的tuple1,tuple2為tuple1_1,tuple2_1,Tx_A和Tx_B更新後的tuple1,tuple2為tuple1_2,tuple2_2。
這樣在併發下:
Tx_A讀到的tuple1是tuple1_1,tuple2是tuple2_1。
同理,Tx_B讀到的tuple1是tuple1_1,tuple2是tuple2_1。而如果我們以Tx_A,Tx_B的順序序列執行時,結果為:
Tx_A讀到的tuple1是tuple1_1,tuple2是tuple2_1。
Tx_B讀到的tuple1是tuple1_2(被Tx_A更新了),tuple2是tuple2_1。反之,而如果我們以Tx_B,Tx_A的順序序列執行時,結果為:
Tx_B讀到的tuple1是tuple1_1,tuple2是tuple2_1。
Tx_A讀到的tuple1是tuple1_1,tuple2是tuple2_2(被Tx_B更新了)。
可以看出,這三個結果都不一樣,不滿足條件2,即併發的Tx_A和Tx_B不能被模擬為Tx_A和Tx_B的任意一個序列執行,導致序列化失敗。
其實我上面提到的讀寫閉環,更正式的說法是:序列化異常。上面說的那麼多,其實下面兩張圖即可解釋。
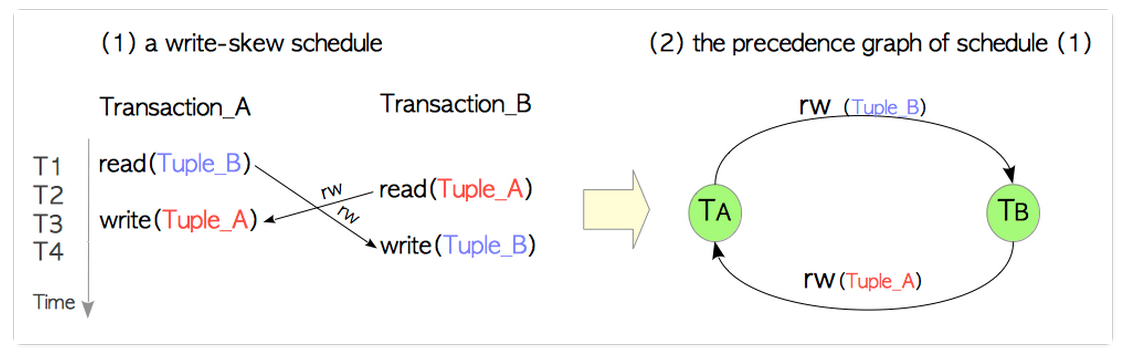
關於這個*-conflicts我們遇到好幾個了。我們先總結下:
wr-conflicts (Dirty Reads)
ww-conflicts (Lost Updates)
rw-conflicts (serialization anomaly)下面說的SSI機制,就是用來解決rw-conflicts的。
好的,下面就開始說怎麼檢測這個序列化異常問題,也就是說,我們要開始瞭解下SSI機制了。
在PostgreSQL中,使用以下方法來實現SSI:
利用SIREAD LOCK(謂詞鎖)記錄每一個事務訪問的物件(tuple、page和relation);
在事務寫堆表或者索引元組時利用SIREAD LOCK監測是否存在衝突;
如果發現到衝突(即序列化異常),abort該事務。
從上面可以看出,SIREAD LOCK是一個很重要的概念。解釋了這個SIREAD LOCK,我們也就基本上理解了SSI。
所謂的SIREAD LOCK,在PostgreSQL內部被稱為謂詞鎖。他的形式如下:
SIREAD LOCK := { tuple|page|relation, {txid [, ...]} }也就是說,一個謂詞鎖分為兩個部分:前一部分記錄被"鎖定"的物件(tuple、page和relation),後一部分記錄同時訪問了該物件的事務的virtual txid(有關它和txid的區別,這裡就不做多介紹了)。
SIREAD LOCK的實現在函式CheckForSerializableConflictOut中。該函式在隔離級別為SERIALIZABLE的事務中發生作用,記錄該事務中所有DML語句所造成的影響。
例如,如果txid為100的事務讀取了tuple_1,則建立一個SIREAD LOCK為{tuple_1, {100}}。此時,如果另一個txid為101的事務也讀取了tuple_1,則該SIREAD LOCK升級為{tuple_1, {100,101}}。需要注意的是如果在DML語句中訪問了索引,那麼索引中的元組也會被檢測,建立對應的SIREAD LOCK。
SIREAD LOCK的粒度分為三級:tuple|page|relation。如果同一個page中的所有tuple都被建立了SIREAD LOCK,那麼直接建立page級別的SIREAD LOCK,同時釋放該page下的所有tuple級別的SIREAD LOCK。同理,如果一個relation的所有page都被建立了SIREAD LOCK,那麼直接建立relation級別的SIREAD LOCK,同時釋放該relation下的所有page級別的SIREAD LOCK。
當我們執行SQL語句使用的是sequential scan時,會直接建立一個relation 級別的SIREAD LOCK,而使用的是index scan時,只會對heap tuple和index page建立SIREAD LOCK。
同時,我還是要說明的是,對於index的處理時,SIREAD LOCK的最小粒度是page,也就是說你即使只訪問了index中的一個index tuple,該index tuple所在的整個page都被加上了SIREAD LOCK。這個特性常常會導致意想不到的序列化異常,我們可以在後面的例子中看到。
有了SIREAD LOCK的概念,我們現在使用它來檢測rw-conflicts。
所謂rw-conflicts,簡單地說,就是有一個SIREAD LOCK,還有分別read和write這個SIREAD LOCK中的物件的兩個併發的Serializable事務。
這個時候,另外一個函式閃亮登場:CheckForSerializableConflictIn()。每當隔離級別為Serializable事務中執行INSERT/UPDATE/DELETE語句時,則呼叫該函式判斷是否存在rw-conflicts。
例如,當txid為100的事務讀取了tuple_1,建立了SIREAD LOCK : {tuple_1, {100}}。此時,txid為101的事務更新tuple_1。此時呼叫CheckForSerializableConflictIn()發現存在這樣一個狀態: {r=100, w=101, {Tuple_1}}。顯然,檢測出這是一個rw-conflicts。
下面是舉例時間。
首先,我們有這樣一個表:
testdb=# CREATE TABLE tbl (id INT primary key, flag bool DEFAULT false);
testdb=# INSERT INTO tbl (id) SELECT generate_series(1,2000);
testdb=# ANALYZE tbl;併發執行的Serializable事務像下面那樣執行:

假設所有的SQL語句都走的index scan。這樣,當SQL語句執行時,不僅要讀取對應的heap tuple,還要讀取heap tuple 對應的index tuple。如下圖:
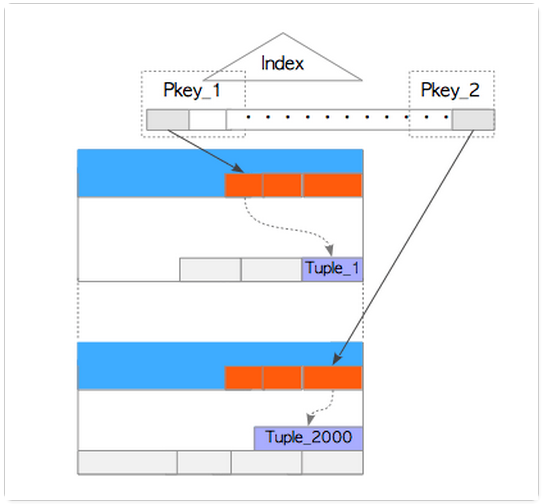
執行狀態如下: T1: Tx_A執行SELECT語句,該語句讀取了heap tuple(Tuple_2000)和index page(Pkey2);
T2: Tx_B執行SELECT語句,該語句讀取了heap tuple(Tuple_1)和index page(Pkey1);
T3: Tx_A執行UPDATE語句,該語句更新了Tuple_1;
T4: Tx_B執行UPDATE語句,該語句更新了Tuple_2000;
T5: Tx_A commit;
T6: Tx_B commit; 由於序列化異常,commit失敗,狀態為abort。
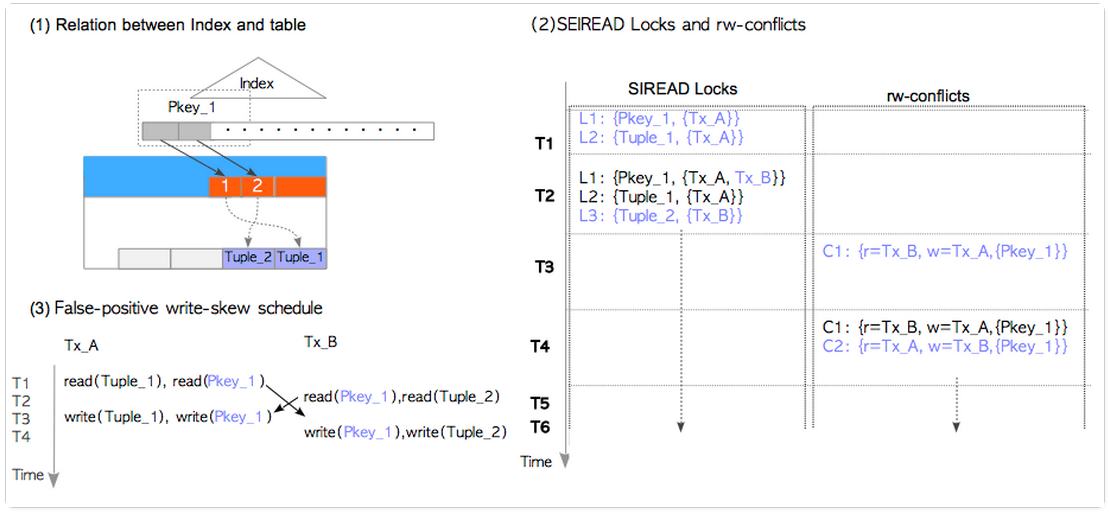
這時我們來看一下SIREAD LOCK的情況。

T1: Tx_A執行SELECT語句,呼叫CheckForSerializableConflictOut()建立了SIREAD LOCK:L1={Pkey_2,{Tx_A}} 和 L2={Tuple_2000,{Tx_A}};
T2: Tx_B執行SELECT語句,呼叫CheckForSerializableConflictOut建立了SIREAD LOCK:L3={Pkey_1,{Tx_B}} 和 L4={Tuple_1,{Tx_B}};
T3: Tx_A執行UPDATE語句,呼叫CheckForSerializableConflictIn(),發現並建立了rw-conflict :C1={r=Tx_B, w=Tx_A,{Pkey_1,Tuple_1}}。這很顯然,因為Tx_B和TX_A分別read和write這兩個object。
T4: Tx_A執行UPDATE語句,呼叫CheckForSerializableConflictIn(),發現並建立了rw-conflict :C1={r=Tx_A, w=Tx_B,{Pkey_2,Tuple_2000}}。到這裡,我們發現C1和C2構成了precedence graph中的一個環。因此,Tx_A和Tx_B這兩個事務都進入了non-serializable狀態。但是由於Tx_A和Tx_B都未commit,因此CheckForSerializableConflictIn()並不會abort Tx_B(為什麼不abort Tx_A?因此PostgreSQL的SSI機制中採用的是first-committer-win,即發生衝突後,先提交的事務保留,後提交的事務abort。)
T5: Tx_A commit;呼叫PreCommit_CheckForSerializationFailure()函式。該函式也會檢測是否存在序列化異常。顯然此時Tx_A和Tx_B處於序列化衝突之中,而由於發現Tx_B仍然在執行中,所以,允許Tx_A commit。
T6: Tx_B commit; 由於序列化異常,且和Tx_B存在序列化衝突的Tx_A已經被提交。因此commit失敗,狀態為abort。
更多更復雜的例子,可以參考這裡.
前面在討論SIREAD LOCK時,我們談到對於index的處理時,SIREAD LOCK的最小粒度是page。這個特性會導致意想不到的序列化異常。更專業的說法是"False-Positive Serialization Anomalies"。簡而言之實際上並沒有發生序列化異常,但是我們的SSI機制不完善,產生了誤報。
下面我們來舉例說明。

對於上圖,如果SQL語句走的是sequential scan,情形如下:

如果是index scan呢?還是有可能出現誤報:
這篇就是這樣。依然還是有很多問題沒有講清楚。留待下次再說吧(拖延症晚期)。