
selenium使用xpath定位元素
在學習XPath之前你應該對XML的節點,元素,屬性,原子值(文字),處理指令,註釋,根節點(文件節點),名稱空間以及對節點間的關係如:父(Parent),子(Children),兄弟(Sibling),先輩(Ancestor),後代(Descendant)等概念有所瞭解。這裡不在說明。
路徑表示式語法:
- 路徑 = 相對路徑 | 絕對路徑
- XPath路徑表示式 = 步進表示式 | 相對路徑 "/"步進表示式。
- 步進表示式=軸 節點測試 謂詞
說明:
- 其中軸表示步進表示式選擇的節點和當前上下文節點間的樹狀關係(層次關係),節點測試指定步進表示式選擇的節點名稱副檔名,謂詞即相當於過濾表示式以進一步過濾細化節點集。
- 謂詞可以是0個或多個。多個多個謂詞用邏輯操作符and, or連線。取邏輯非用not()函式。
請看一個典型的XPath查詢表示式:/messages/message//child::node()[@id=0],其中/messages/message是路徑(絕對路徑以"/"開始),child::是軸表示在子節點下選擇,node()是節點測試表示選擇所有的節點。[@id=0]是謂詞,表示選擇所有有屬性id並且值為0的節點。
相對路徑與絕對路徑:
如果"/"處在XPath表示式開頭則表示文件根元素,(表示式中間作為分隔符用以分割每一個步進表示式)如:/messages/message/subject是一種絕對路徑表示法,它表明是從文件根開始查詢節點。假設當前節點是在第一個
1.通過相對路徑的屬性值查詢多個屬性值使用and進行連線。
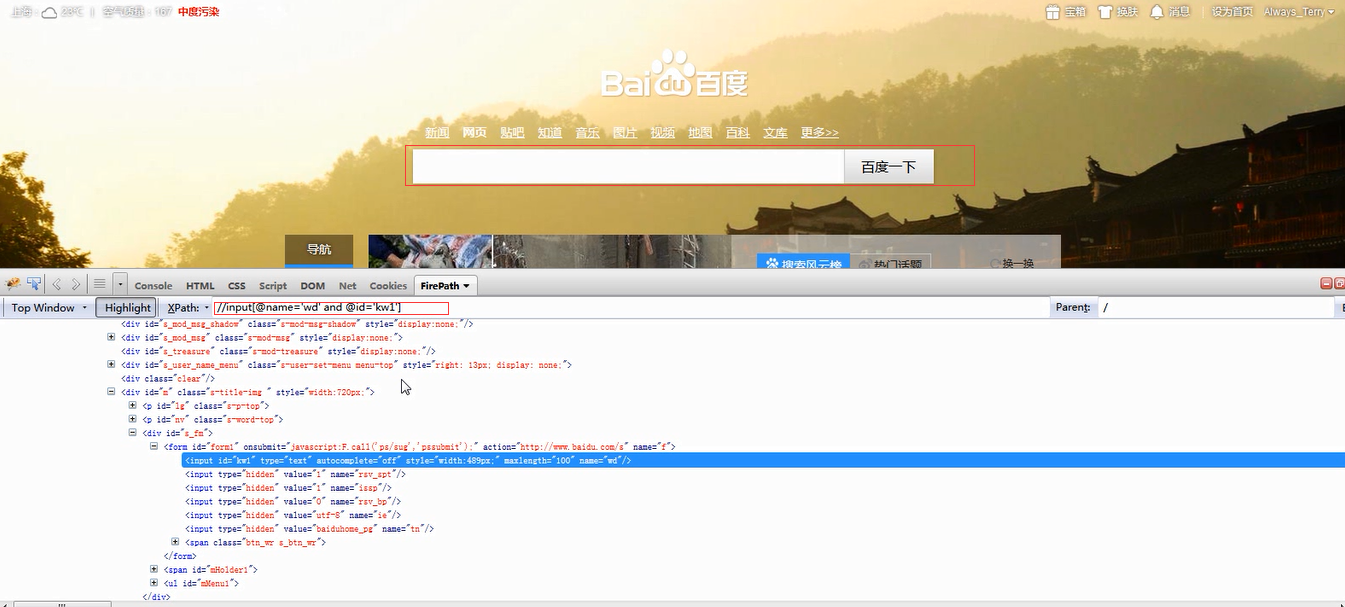
2.通過text函式進行查詢,依舊可以和其他條件聯合使用。記住函式是使用的()結尾
3.使用contains 屬性值 text() 聯合進行定位主要contains的方法不帶等號
//a[contains(text(),'新聞') and contains(@href,'new') and @target='_blank' and text()='新聞']
4.根據索引值進行定位使用last()函式。也可以直接賦索引值,因為標籤個數有可能會變化,儘量使用函式進行加減
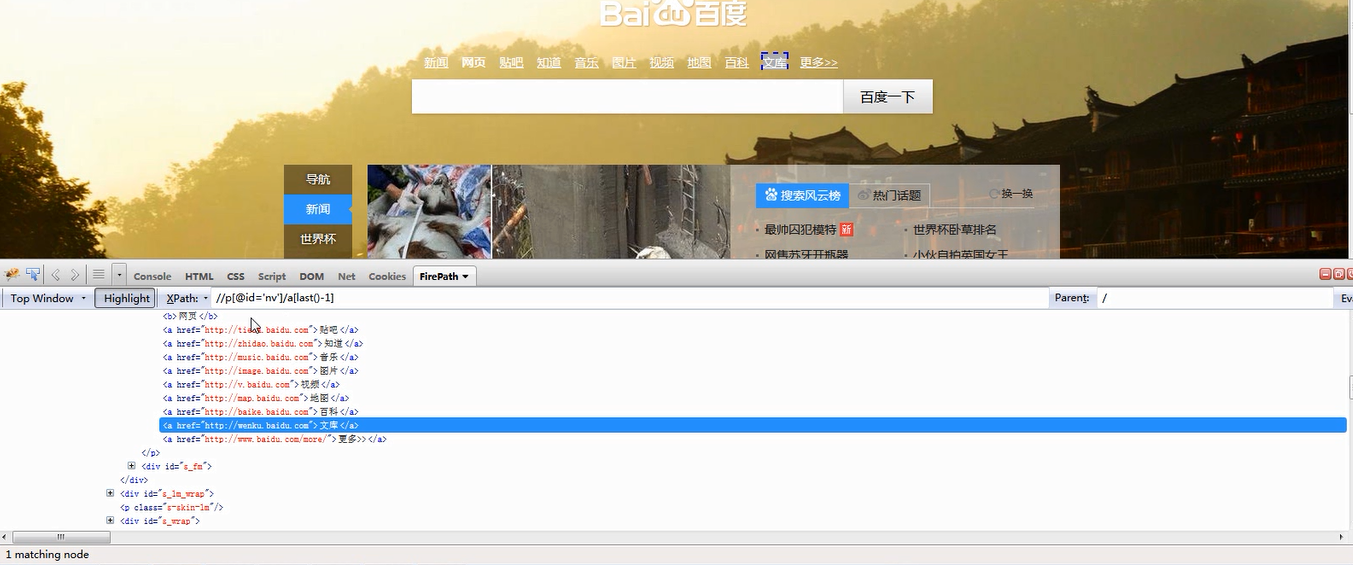
5使用xpath軸進行定位
|
軸名稱 |
結果 |
|
ancestor |
選取當前節點的所有先輩(父、祖父等) |
|
ancestor-or-self |
選取當前節點的所有先輩(父、祖父等)以及當前節點本身 |
|
attribute |
選取當前節點的所有屬性 |
|
child |
選取當前節點的所有子元素。 |
|
descendant |
選取當前節點的所有後代元素(子、孫等)。 |
|
descendant-or-self |
選取當前節點的所有後代元素(子、孫等)以及當前節點本身。 |
|
following |
選取文件中當前節點的結束標籤之後的所有節點。 |
|
namespace |
選取當前節點的所有名稱空間節點 |
|
parent |
選取當前節點的父節點。 |
|
preceding |
直到所有這個節點的父輩節點,順序選擇每個父輩節點前的所有同級節點 |
|
preceding-sibling |
選取當前節點之前的所有同級節點。 |
|
self |
選取當前節點。 |
ancestor節點使用方法(descendant的使用方法也是如此):
1.使用當前節點定位,找尋先輩的標籤。
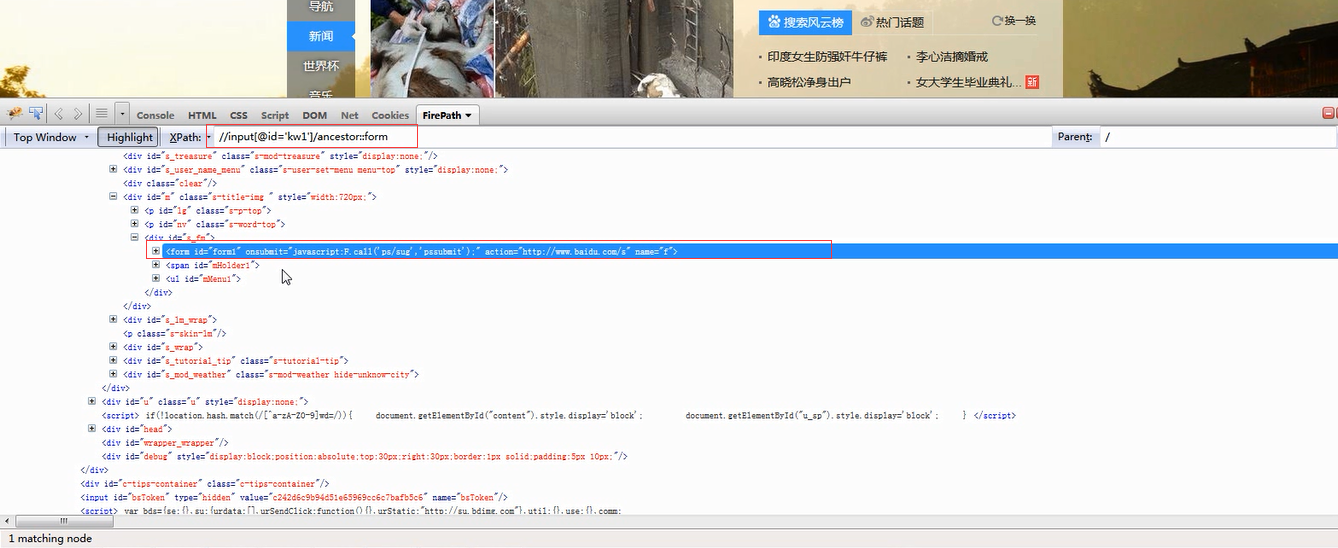
2.將祖輩是某個節點作為當前節點唯一祖輩
precedi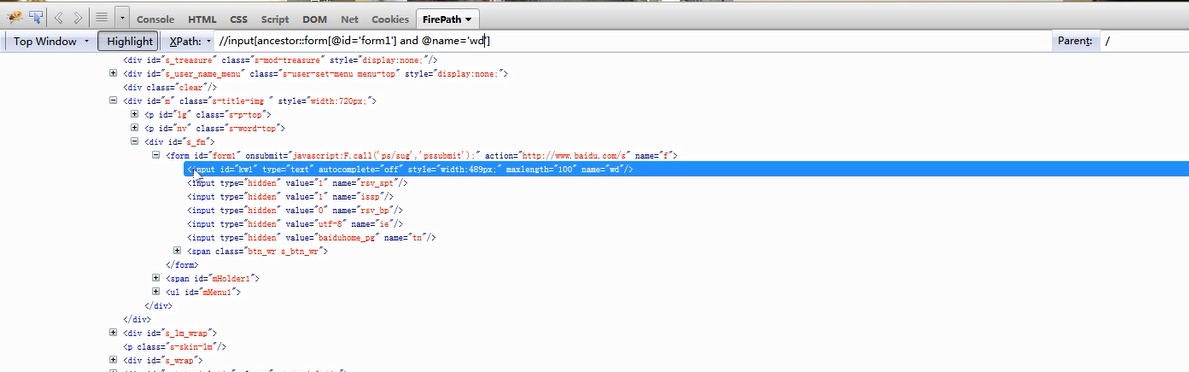 ng-sibling(following-sibling用法一致)
ng-sibling(following-sibling用法一致)
找到同級節點標籤為input,屬性為name=ie 並且,想要查詢的節點的標籤是input,name屬性是tn
//input[preceding-sibling::input[@name='ie'] and @name='tn']
找到input標籤屬性name=ie的同級節點下input下屬性name為f
//input[@name='ie']/preceding-sibling::input[@name='f']
parent和child用法類似,代表當前節點的父節點和子節點
其實看過好多部落格,有人說xpath定位比較慢,用了這麼長時間,感覺速度還好啊,個人感覺慢是相對的,1ms和50ms對於肉眼來說可以忽略不計的。