
face recognition[variations of softmax][L-Softmax]
本文來自《Large-Margin Softmax Loss for Convolutional Neural Networks》,時間線為2016年12月,是北大和CMU的作品。
0 引言
過去十幾年,CNN被應用在各個領域。大家設計的結構,基本都包含卷積層和池化層,可以將區域性特徵轉換成全域性特徵,並具有很強的視覺表徵能力。在面對更復雜的資料下,結構也變得更深(VGG),更小的strides(VGG),新的非線性啟用函式(ReLU)。同時受益於很強的學習能力,CNN同樣需要面對過擬合的問題。所以一些如大規模的訓練集,dropout,資料增強,正則,隨機池化等都不斷被提出。
最近的主流方向傾向於讓CNN能夠學到更具辨識性的特徵。直觀上來說,如果特徵具有可分性且同時具有辨識性,這是極好的。可是因為許多工中本身包含較大的類內變化,所以這樣的特徵也不是輕易能夠學到的。不過CNN強大的表徵能力可以學到該方向上的不變性特徵,受到這樣的啟發,contrastive loss和triplet loss都因此提出來增強類內緊湊性和類間可分性。然而,一個後續問題是,所需要的圖片二元組或者三元組理論上需要的量是\(O(N^2)\)
本文中,作者將softmax loss定義為cross-entropy loss,softmax函式和最後一層全連線層的組合。如下圖

基於這樣的設定,許多流行的CNN模型可以被看成一個卷積特徵學習元件和一個softmax loss元件的組合。可是之前的softmax loss不能顯式的推進類內緊湊和類間可分。作者一個直觀觀點是模型的引數和樣本可以因式分解成幅度和具有cos的相似性角度:
\[\mathbf{W}_cx=||\mathbf{W}_c||_2||x||_2cos(\theta_c)\]
這裡 \(c\)是類別索引,對應的最後全連線層引數 \(\mathbf{W}_c\)可以看成是關於類 \(c\)的線性分類器的引數。基於softmax loss,標籤預測決策規則很大程度上是被每個類別的角度相似度決定的(因為softmax loss使用餘弦距離作為分類得分)。
作者本文的目的就是通過角度相似度項,泛化softmax loss到一個更通用的大邊際softmax(L-Softmax)loss上,從而讓學到的特徵之間具有更大的角度可分性。通過預設常數\(m\),乘以樣本和ground-truth類別分類器之間的角度。\(m\)確定了靠近ground-truth類的強度,提供了一個角度邊際。而傳統的softmax loss可以看成是L-sofmax loss的一個特例。
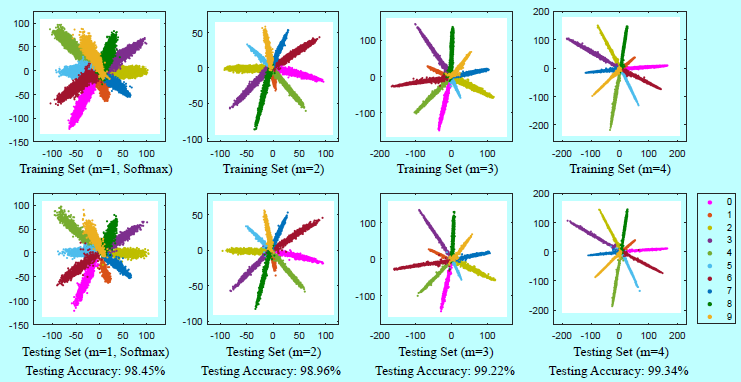

如上圖可以看出,L-Softmax學到的特徵可以變得更緊湊和更可分。
L-Softmax loss是一個靈活的可以調整類內角度邊際限制的目標函式。它提出了可調節難度的學習任務,其中隨著所需邊際變大,難度逐漸增加。L-Softmax loss有好幾個優勢:
- 傾向擴大類之間的角度決策邊際,生成更多辨識性的特徵。它的幾何解釋也十分清晰和直觀;
- 通過定義一個更困難的學習目標來部分避免過擬合,即採用了不同的觀點來闡述過擬合;
- L-Softmax不止得益於分類問題。在驗證問題中,最小的類間距離也會大於最大的類內距離。這種情況下,學習可分性的特徵可以明顯的提升效能。
作者的實驗驗證了L-Softmax可以有效的加速分類和驗證任務的效能。更直觀的,圖2和圖5中的特徵視覺化都揭示了L-Softmax loss更好的辨識性
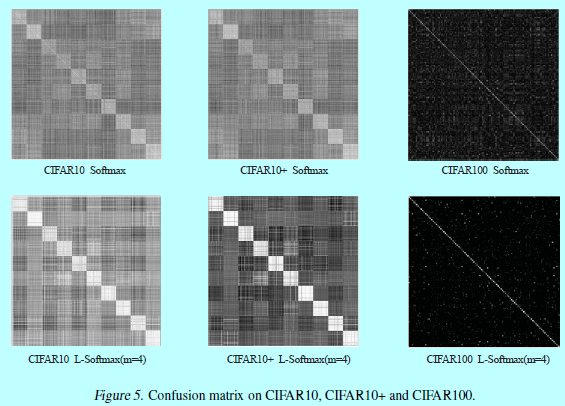
作為一個直觀的softmax loss泛化,L-softmax loss不止是繼承了所有softmax loss的優點,同時讓特徵體現不同類別之間大角度邊際特性。
1 Softmax Loss以cos方式呈現
當前廣泛使用的資料loss函式包含歐式loss,hinge(平方) loss,資訊增益loss,contrastive loss, triplet loss, softmax loss等等。為了增強類內緊湊性和類間可分性,《Deep learning face representation by joint identificationverification》提出將softmax和contrastive相結合。contrastive loss輸入的是一對訓練樣本,如果這對樣本屬於同一個類,那麼contrastive loss需要他們的特徵儘可能的相似;否則,contrastive loss會讓他們的距離超過一個邊際閾值。
而不管是contrastive loss還是triplet loss都需要仔細的設計樣本選擇過程。而他們都更加傾向類內緊湊性和類間可分性,這也給作者一些靈感:在原始softmax loss上增加一個邊際限制。
作者提出在原始softmax loss上進行泛化。假設第\(i\)個輸入特徵\(x_i\)和對應的label是\(y_i\)。那麼原始softmax loss可以寫成:
\[L=\frac{1}{N}\sum_i L_i=\frac{1}{N}\sum_i-\log \left ( \frac{e^{f_{y_i}}}{\sum_j e^{f_j}}\right ) \tag{1}\]
其中,\(f_j\)表示類別得分\(\mathbf{f}\)向量的第\(j\)個元素(\(j\in [1,K]\),K表示類別個數),N表示樣本個數。在softmax loss中,\(\mathbf{f}\)通常表示全連線層\(\mathbf{W}\)的啟用函式,所以\(f_{y_i}\)可以寫成\(f_{y_i}=\mathbf{W}_{y_i}^Tx_i\),這裡\(\mathbf{W}_{y_i}\)是\(\mathbf{W}\)的第\(y_i\)列。注意到,忽略了\(f_j\)中的常量\(b\),\(\forall j\)為了簡化分析,但是L-Softmax loss仍然可以容易的修改成帶有\(b\)的(效能沒什麼差別)。
因為\(f_j\)是基於\(\mathbf{W}_j\)和\(x_i\)的內積,可以寫成\(f_j=||\mathbf{W}_j||||x_i||cos(\theta_j)\),這裡\(\theta_j(0\leq \theta_j \leq \pi)\)是基於\(\mathbf{W}_j\)和\(x_i\)向量的夾角,因此loss變成:
\[L_i=-\log\left( \frac{ e^{||\mathbf{W}_{y_i}||||x_i||cos(\theta_{y_i})} }{ \sum_i e^{||\mathbf{W}_j|| ||x_i|| cos(\theta_j)} } \right ) \]
2 Large-Margin Softmax Loss
2.1 直觀
這裡先給出一個簡單的例子來直觀的描述一下。考慮一個二分類問題,有一個來自類別1的樣本\(x\),為了正確分類,原始softmax表現為\(\mathbf{W}_1^Tx> \mathbf{W}_2^Tx\)(即,\(||\mathbf{W}_1||||x||cos(\theta_1)> ||\mathbf{W}_2||||x||cos(\theta_2)\))。然而,為了生成一個決策邊際而讓分類更嚴格,作者認為可以\(||\mathbf{W}_1||||x||cos(m\theta_1)>||\mathbf{W}_2||||x||cos(\theta_2)(0 \leq \theta_1 \leq \frac{\pi}{m})\),這裡\(m\)是一個正整數,因為有下面不等式:
\[ ||\mathbf{W}_1||||x||cos(\theta_1) \geq ||\mathbf{W}_1||||x||cos(m\theta_1) > ||\mathbf{W}_2||||x||cos(\theta_2) \]
因此,\(||\mathbf{W}_1||||x||cos(\theta_1) > ||\mathbf{W}_2||||x||cos(\theta_2)\).所以新分類標準是一個更強的標準。
2.2 定義
按照上面的解釋,L-Softmax loss定義為:
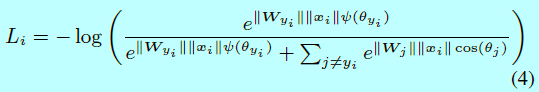
其中定義為:
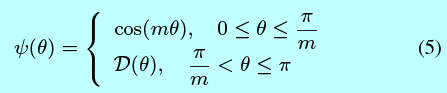
這裡 \(m\)是一個整數,與分類邊際密切相關。當 \(m\)變得更大時,分類邊際也更大,學習的目標同時也變得更難。同時 \(\mathcal{D}(\theta)\)是一個單調遞減的函式, \(\mathcal{D}(\frac{\pi}{m})\)等於 \(cos(\frac{\pi}{m})\)

為了簡化前向和後向傳播,本文中作者構建了一個特殊的函式 \(\psi (\theta_i)\):
\[\psi (\theta)=(-1)^kcos(m\theta)-2k,\, \, \theta\in\left [ \frac{k\pi}{m},\, \frac{(k+1)\pi}{m}\right ] \tag{6} \]
這裡 \(k\in[0, m-1]\), \(k\)是一個整數。將式子1,式子4,式子6相結合,得到的L-Softmax loss。對於前向和後向傳播,需要將 \(cos(\theta_j)\)替換為 \(\frac{\mathbf{W}_j^Tx_i}{||\mathbf{W}_j||||x_i||}\),然後將 \(cos(m \theta_{y_i})\)替換成:
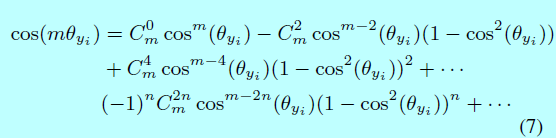
這裡n是整數且 \(2n \leq m\)。在消掉 \(\theta\)之後,可以求關於 \(x\)和 \(\mathbf{W}\)的偏導。
2.3 幾何解釋
作者的目標是通過L-Softmax loss來得到一個角度邊際。為了簡化幾何上的解釋,這裡分析二分類情況,其中只有\(\mathbf{W}_1\)和\(\mathbf{W}_2\)。
首先,假設\(||\mathbf{W}_1||=||\mathbf{W}_2||\),如圖4。
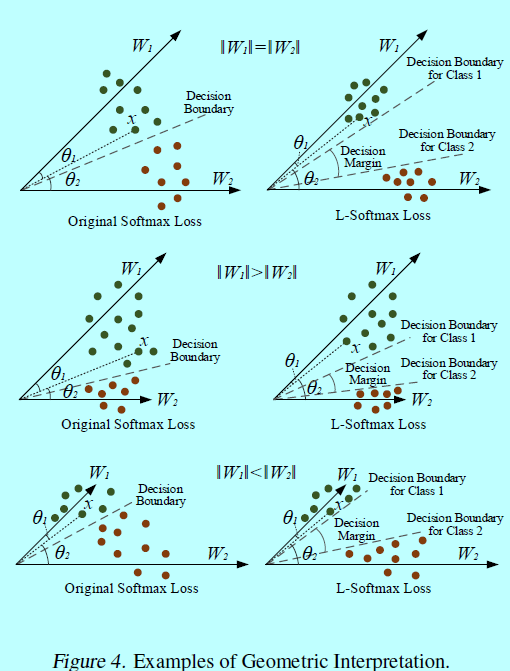
當 \(||\mathbf{W}_1||=||\mathbf{W}_2||\)時,分類結果完全依賴介於 \(x\)和 \(\mathbf{W}_1(\mathbf{W}_2)\)。在訓練階段,原始的softmax需要 \(\theta_1<\theta_2\)去將樣本 \(x\)分為1類,同時,L-Softmax loss需要 \(m\theta_1<\theta_2\)來保證同樣的決策。可以發現L-Softmax是更嚴格的分類標準,從而生成一個介於類1和類2分類邊際。假設softmax和L-Softmax都優化到相同的值,然後所有的訓練特徵可以十分完美的分類,那麼,介於類1和類2之間的角度邊際可以通過 \(\frac{m-1}{m+1}\theta_{1,2}\)得出,這裡 \(\theta_{1,2}\)是基於向量 \(\mathbf{W}_1\)和 \(\mathbf{W}_2\)之間的角度。L-Softmax loss同樣也會建立類1和類2的決策面。從另一個角度,讓 \(\theta_1^{'}=m\theta_1\),並假設原始softmax和L-Softmax可以優化到相同的值。那麼可以知道在原始softmax中 \(\theta_1^{'}\)是L-Softmax中 \(\theta_1\)的m-1倍。所以介於學到的特徵和 \(\mathbf{W}_1\)之間的角度會變得更小。對於每個類別,都有相同的結論。本質上,L-Softmax 會縮小每個類可行的角度,並在這些類上生成 一個邊際。
對於\(||\mathbf{W}_1||>||\mathbf{W}_2||\)和\(||\mathbf{W}_1||<||\mathbf{W}_2||\)等情況,幾何解釋更復雜一些。因為\(\mathbf{W}_1\)和\(\mathbf{W}_2\)的模是不同的,類1和類2的可行角度也是不同的。正常的更大的\(\mathbf{W}_j\),對應的類就有更大的可行角度。所以,L-Softmax loss會對不同的類生成不同角度的邊際。同時也會對不同的類生成不同的邊際。
2.4 討論
L-Softmax loss在原始softmax上做了一個簡單的修改,在類之間獲得了一個分類角度邊際。通過設定不同的m值,就定義了一個可調整難度的CNN模型。L-Softmax loss有許多不錯的特性:
- L-Softmax 有一個清晰的幾何解釋。m控制著類別之間的邊際。更大的m(在相同訓練loss下),表示類別之間理想的邊際也更大,同時學習的困難程度也會上升。當m=1,L-Softmax就是原始softmax;
- L-Softmax 定義了一個帶有可調整邊際(困難)的學習目標。一個困難的學習目標可以有效的避免過擬合,同時繼承深度和廣度結構上很強的學習能力;
- L-Softmax 可以很容易的作為標準loss的一個選擇,就和其他標準loss一樣,也包含可學習的啟用函式,資料增強,池化函式或其他網路結構模型。
3 優化
L-Softmax loss的前向和後向是很容易計算的,所以也很容易通過SGD進行迭代優化。對於\(L_i\),原始softmax和L-Softmax之間的差別在於\(f_{y_i}\)。因此只需要在前向和後向中計算\(f_{y_i}\),且同時其他的\(f_j,\, j \neq y_i\)與原始softmax是一樣的,將式子6和式子7相結合,得到\(f_{y_i}\):

其中:

且,k是一個整數,取值為 \([0,m-1]\)。對於後向傳播,使用鏈式法則去計算偏導
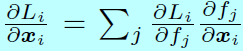 和
和
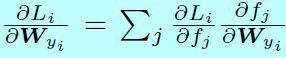
因為 \(\frac{\partial L_i}{\partial f_j}\)和 \(\frac{\partial f_j}{\partial x_i},\, \frac{\partial f_j}{\mathbf{W}_{y_i}},\forall j \neq y_i\)在原始softmax和L-Softmax都是一樣的,所以為了簡潔, \(\frac{\partial f_{y_i}}{\partial x_i}\)和 \(\frac{\partial f_{y_i}}{\partial \mathbf{W}_{y_i}}\)可以通過下面式子計算:
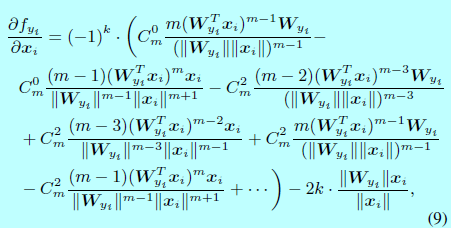
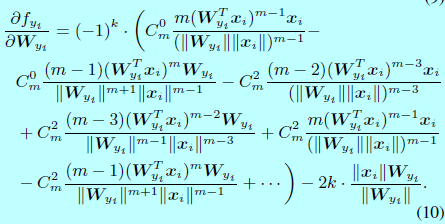
在實現過程中,k可以通過構建一個關於 \(\frac{\mathbf{W}_{y_i}^Tx_i}{||\mathbf{W}_{y_i}||||x_i||}\)(即 \(cos(\theta_{y_i})\))的查詢表。舉個例子,給定一個m=2時候的力氣,此時 \(f_i\)寫成:
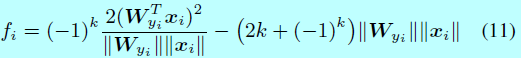
其中:
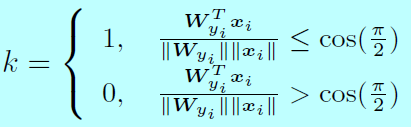
在後向傳播中, \(\frac{\partial f_{y_i}}{\partial x_i}\)和 \(\frac{\partial f_{y_i}}{\partial \mathbf{W}_{y_i}}\)計算為:
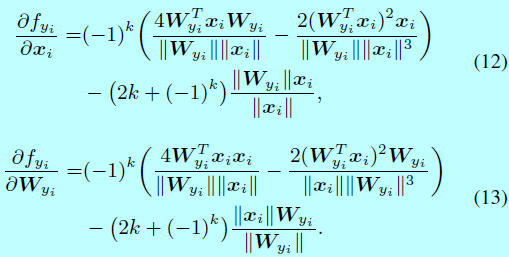
當 \(m\geq 3\)時,仍然可以通過式子8,式子9,式子10來計算前向和後向。
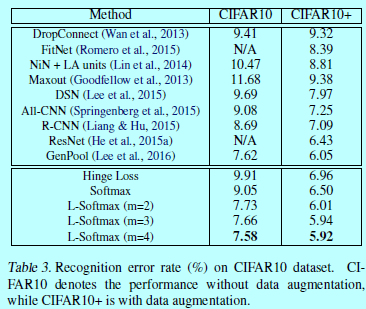
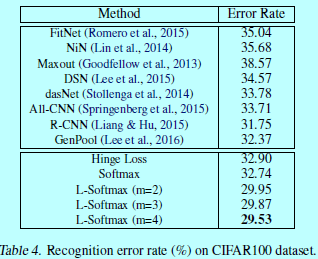
4 實驗細節
在兩個型別資料集上進行了本文方法的測試:影象分類和人臉驗證。在影象分類中使用MNIST,CIFAR10,CIFAR100;在人臉驗證中使用LFW。只有在softmax層有差別,前面的網路結構在每個資料集上都是各自一樣的。如下圖
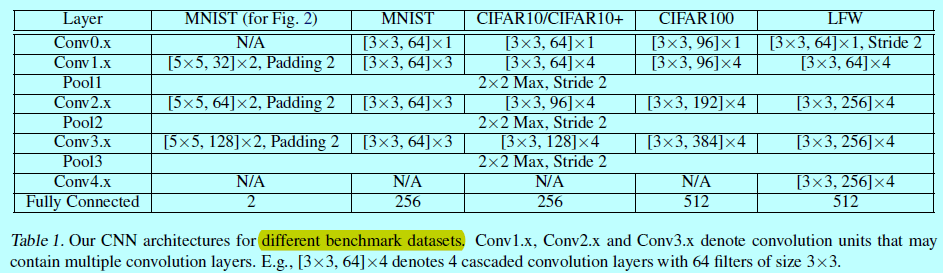
網路結構上,略
當訓練具有較多目標的資料集如CASIA-WebFace上,L-Softmax的收斂會變得比softmax 要困難,對於這種情況,L-Softmax就更難收斂,這時候的學習策略是
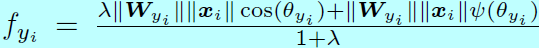
且梯度下降開始時採用較大值的 \(\lambda\)(接近原始softmax),然後逐步的減小 \(\lambda\),理想情況下 \(\lambda\)會減少到0,不過實際情況中,一個較小的值就能滿足了。
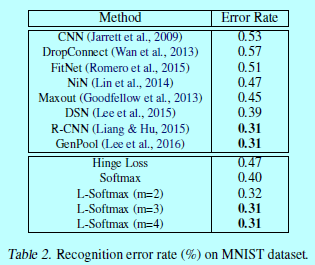

。