
神經網路啟用函式學習要點記錄
如下圖所示,在神經元中,輸入通過加權,求和後,還被作用於一個函式,這個函式就是啟用函式/激勵函式 Activation Function。啟用函式的作用是為了增加神經網路的非線性。

常用的啟用函式:
1、Sigmoid函式:
![]()

特點:能夠把輸入的連續實值變換為0和1之間的輸出,特別的,如果是非常大的負數,那麼輸出就是0;如果是非常大的正數,輸出就是1。
缺點:在深度神經網路中梯度反向傳遞時導致梯度爆炸和梯度消失,其中梯度爆炸發生的概率非常小,而梯度消失發生的概率比較大。
解析式中含有冪運算,計算機求解時相對來講比較耗時。對於規模比較大的深度網路,這會較大地增加訓練時間。
其輸出並不是以0為中心的。會導致後一層的神經元將得到上一層輸出的非0均值的訊號作為輸入。 產生的一個結果就是:如果資料進入神經元的時候是正的,那麼計算出的梯度也會始終都是正的。
不建議在網路中使用。
2、tanh函式:
![]()

它解決了Sigmoid函式的不是zero-centered輸出問題,然而,梯度消失(gradient vanishing)的問題和冪運算的問題仍然存在。
不建議在網路中使用。
3、ReLU函式(Rectified Linear Unit,修正線性單元):
![]()

優點:解決了梯度消失(gradient vanishing)問題 (在正區間)
計算速度非常快,只需要判斷輸入是否大於0
收斂速度遠快於sigmoid和tanh
缺點:隨著訓練的進行,可能會出現神經元死亡、權重無法更新的情況。可以通過設定learning rate來緩解。
4、PReLU(Parametric Rectified Linear Unit)函式:
f(x) = max(ax, x) 一般來說a為很小的係數,在訓練中取一定範圍內的隨機值,在測試時固定。當a=0.01時為Leaky ReLU。
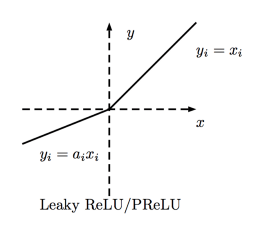
有ReLU函式的優點,解決了神經元死亡的問題。
Softmax 函式:
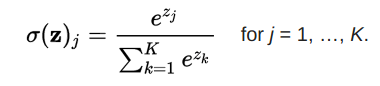
多用於輸出層,計算分類概率。
結論:
選擇啟用函式時,優先選擇ReLU及其變體,而不是sigmoid或tanh。ReLU及其變體訓練起來更快。如果ReLU導致神經元死亡,使用Leaky ReLU或者ReLU的其他變體。sigmoid和tanh受到消失梯度問題的困擾,不應該在隱藏層中使用。隱藏層使用ReLU及其變體較好。使用容易求導和訓練的啟用函式。