
基於Spark UI效能優化與除錯——初級篇
阿新 • • 發佈:2018-12-14
Spark有幾種部署的模式,單機版、叢集版等等,平時單機版在資料量不大的時候可以跟傳統的java程式一樣進行斷電除錯、但是在叢集上除錯就比較麻煩了...遠端斷點不太方便,只能通過Log的形式進行資料分析,利用spark ui做效能調整和優化。
那麼本篇就介紹下如何利用Ui做效能分析,因為本人的經驗也不是很豐富,所以只能作為一個入門的介紹。
大體上會按照下面的思路進行講解:
- 怎麼訪問Spark UI
- SparkUI能看到什麼東西?job,stage,storage,environment,excutors
- 調優的一些經驗總結
Spark UI入口
如果是單機版本,在單機除錯的時候輸出資訊中已經提示了UI的入口:
17/02/26 13:55:48 INFO SparkEnv: Registering OutputCommitCoordinator
17/02/26 13:55:49 INFO Utils: Successfully started service 'SparkUI' on port 4040.
17/02/26 13:55:49 INFO SparkUI: Started SparkUI at http://192.168.1.104:4040
17/02/26 13:55:49 INFO Executor: Starting executor ID driver on host localhost如果是叢集模式,可以通過Spark日誌伺服器xxxxx:18088者yarn的UI進入到應用xxxx:8088,進入相應的Spark UI介面。
主頁介紹
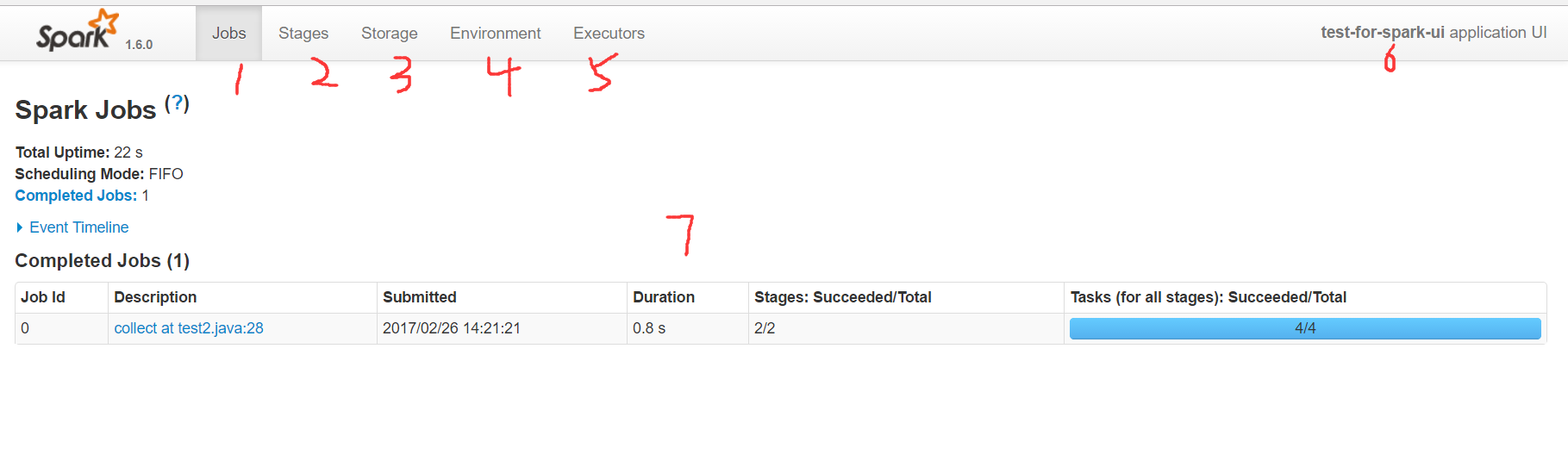
上面就是Spark的UI主頁,首先進來能看到的是Spark當前應用的job頁面,在上面的導航欄:
- 1 代表job頁面,在裡面可以看到當前應用分析出來的所有任務,以及所有的excutors中action的執行時間。
- 2 代表stage頁面,在裡面可以看到應用的所有stage,stage是按照寬依賴來區分的,因此粒度上要比job更細一些
- 3 代表storage頁面,我們所做的cache persist等操作,都會在這裡看到,可以看出來應用目前使用了多少快取
- 4 代表environment頁面,裡面展示了當前spark所依賴的環境,比如jdk,lib等等
- 5 代表executors頁面,這裡可以看到執行者申請使用的記憶體以及shuffle中input和output等資料
- 6 這是應用的名字,程式碼中如果使用setAppName,就會顯示在這裡
- 7 是job的主頁面。
模組講解
下面挨個介紹一下各個頁面的使用方法和實踐,為了方便分析,我這裡直接使用了分散式計算裡面最經典的helloworld程式——WordCount,這個程式用於統計某一段文字中一個單詞出現的次數。原始的文字如下:
for the shadow of lost knowledge at least protects you from many illusions
上面這句話是有一次逛知乎,一個標題為 讀那麼多書,最後也沒記住多少,還為什麼讀書?其中有一個回覆,引用了上面的話,也是我最喜歡的一句。意思是:“知識,哪怕是知識的幻影,也會成為你的鎧甲,保護你不被愚昧反噬”(來自知乎——《為什麼讀書?》)
程式程式碼如下:
public static void main(String[] args) throws InterruptedException {
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local[2]");
sparkConf.setAppName("test-for-spark-ui");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
<span class="hljs-comment">//知識,哪怕是知識的幻影,也會成為你的鎧甲,保護你不被愚昧反噬。</span>
JavaPairRDD<<span class="hljs-built_in">String</span>,Integer> counts = sc.textFile( <span class="hljs-string">"C:\\Users\\xinghailong\\Desktop\\你為什麼要讀書.txt"</span> )
.flatMap(line -> Arrays.asList(line.split(<span class="hljs-string">" "</span>)).iterator())
.mapToPair(s -> <span class="hljs-keyword">new</span> Tuple2<<span class="hljs-built_in">String</span>,Integer>(s,<span class="hljs-number">1</span>))
.reduceByKey((x,y) -> x+y);
counts.cache();
<span class="hljs-built_in">List</span><Tuple2<<span class="hljs-built_in">String</span>,Integer>> result = counts.collect();
<span class="hljs-keyword">for</span>(Tuple2<<span class="hljs-built_in">String</span>,Integer> t2 : result){
System.out.println(t2._1+<span class="hljs-string">" : "</span>+t2._2);
}
sc.stop();