
(三)用Normal Equation擬合Liner Regression模型
繼續考慮Liner Regression的問題,把它寫成如下的矩陣形式,然後即可得到θ的Normal Equation.
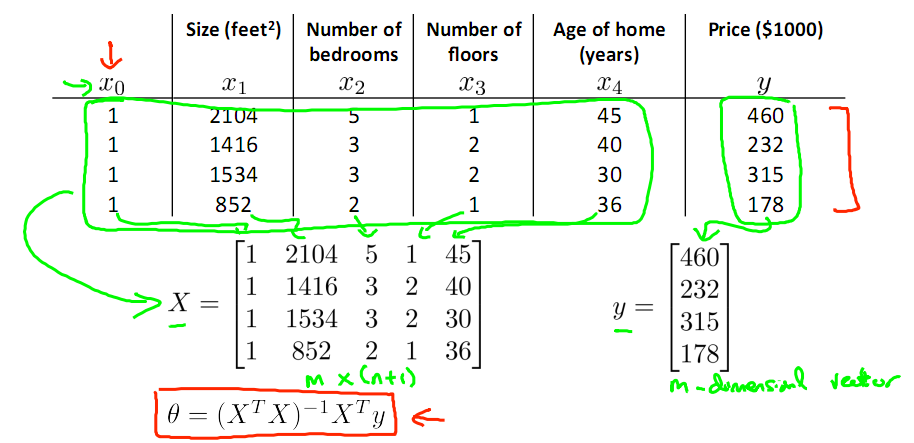

Normal Equation: θ=(XTX)-1XTy
當X可逆時,(XTX)-1XTy = X-1,(XTX)-1XTy其實就是X的偽逆(Pseudo inverse)。這也對應著Xθ = y ,θ = X-1y
考慮特殊情況 XTX 不可逆
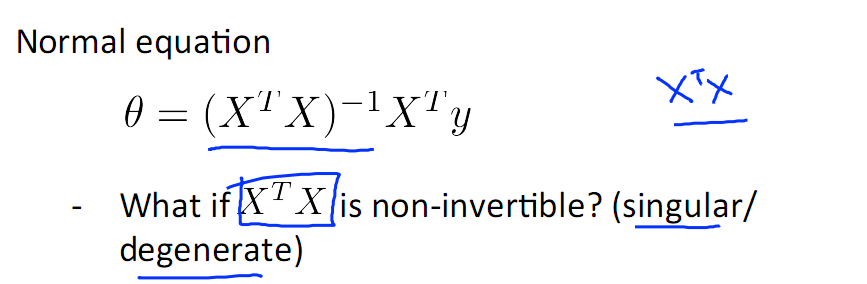
解決辦法:
1)考慮是否有冗餘的特徵,例如特徵中有平方米,還有平方釐米,這兩個特徵就是冗餘的,解決辦法是去掉冗餘
2)再有就是n<<m,其中n 為特徵數,m為樣本數,比如說用10個樣本去學習100個引數的問題,這種情況的解決辦法是去feature或者進行Regularization

總結:Gradient descent VS Normal Equation

上圖可以看出梯度下降需要選擇引數a,並且要多次迭代,有點事特徵非常多時,依然正常工作
而Normal Equation 不用選擇a,並且不用迭代,只需計算X的偽逆即可,當n很大時,設計到非常大的n×n浮點矩陣運算,當然會很耗時,所以n很大時最好選擇Gradient Descent。
相關推薦
(三)用Normal Equation擬合Liner Regression模型
繼續考慮Liner Regression的問題,把它寫成如下的矩陣形式,然後即可得到θ的Normal Equation. Normal Equation: θ=(XTX)-1XTy 當X可逆時,(XTX)-1XTy = X-1,(XTX)-1XTy其實
新版Azure Automation Account 淺析(三) --- 用Runbook管理AAD Application Key
解決 objectid 自動生成 ror powers exception true ask 公眾 新版Azure Automation Account 淺析(三) --- 用Runbook管理AAD應用的Key 前篇講過有一個面向公眾的Runbook庫,社區和微軟一直
React學習及實例開發(三)——用react-router跳轉頁面
con 版本 wid css strong extends fault img doc 本文基於React v16.4.1 初學react,有理解不對的地方,歡迎批評指正^_^ 一、定義路由 1、安裝react-router npm install react-route
MVC學習筆記(三)—用EF向數據庫中添加數據
using gui guid framework create 創建數據庫 添加 添加數據 正在 1.在EFDemo文件夾中添加Controllers文件夾(用的是上一篇MVC學習筆記(二)—用EF創建數據庫中的項目) 2.在Controllers文件夾下添加一個空的控制器
idea上maven使用心得(三)——用pom.xml添加jar包
如何 -s depend idea 標簽 lin 前後端分離 tex end 下面是如何使用maven,maven在idea裏面得結構應該是這樣: scr底下是main,java是存放web的.java文件 resource目錄一般是存放數
idea上maven使用心得(三)——用pom.xml新增jar包
下面是如何使用maven,maven在idea裡面得結構應該是這樣: scr底下是main,java是存放web的.java檔案 resource目錄一般是存放資料庫連線
HDFS(三)——用 Java 建立一個 HDFS 目錄,HDFS 的許可權的問題
一、匯入 HDFS 所需 jar 包 把解壓後的 hadoop 資料夾下的 common 目錄中的 jar,和裡面的 lib 包中所有的 jar,以及 hdfs 目錄下的 jar,和裡面的 lib 包中所有的 jar 都新增到專案的環境變數中。 二、編寫測試程式碼 im
Maven3路程(三)用Maven建立第一個web專案(1)
轉自:https://www.cnblogs.com/leiOOlei/p/3361633.html 一.建立專案 1.Eclipse中用Maven建立專案 上圖中Next 2.繼續Next 3.選maven-archetype-webapp後,next
為什麼正則化(Regularization)可以減少過擬合風險
在解決實際問題的過程中,我們會傾向於用複雜的模型來擬合複雜的資料,但是使用複雜模型會產生過擬合的風險,而正則化就是常用的減少過擬合風險的工具之一。過擬合過擬合是指模型在訓練集上誤差很小,但是在測試集上表現很差(即泛化能力差),過擬合的原因一般是由於資料中存在噪聲或者用了過於複
spark機器學習筆記:(三)用Spark Python構建推薦系統
輸出結果: [[Rating(user=789, product=1012, rating=4.0), Rating(user=789, product=127, rating=5.0), Rating(user=789, product=475, rating=5.0), Rating(us
小程式磚塊(三)用wx.setStorage、wx.getStorage和wx.getStorageSync進行頁面間傳值
先是儲存wx.setStorage Page({ data: { testnum:""//設定測試引數 }, test:function(){ var Num = this.data.testnum; wx.setStorage({//儲
.NET學習(三)用DataSet快取資料庫中的資料
DataSet的使用 DataSet相當於一個數據快取容器。 DataAdapter用於將資料從資料庫中提取出來,存放到DataSet物件中。 大致有以下五個步驟: 1.例項化一個DataAdapter物件。 (注意:以下名稱空間均在MySql環境下!
Pytorch學習(三)--用50行程式碼搭建ResNet
#------------------------------用50行程式碼搭建ResNet------------------------------------------- from torch import nn import torch as t from torc
棧和佇列面試題(三)---用兩個佇列實現一個棧
一:queue是一種”先進先出”的資料結構,他在對尾插入元素,在隊頭刪除元素,他既可以取到自己的隊頭元素,也可以取到自己的隊尾元素; stack是一種”先進後出”的資料結構,他對元素的插入和
C語言:指標篇(三)用指標訪問二維陣列 & 例項分析
之前對指標的認識並不深入,最近在做影象處理,需要用二維陣列儲存影象資料,發現用指標訪問二維陣列的規律,感覺很有意思。 一般,我們定義一個二維陣列比如m[2][2]={ 1,2,3,4 },假如想訪問第i行,j列的元素,用m[i][j]即可,例如m[1][1]=4。 那麼二
Latex初學者入門(三)-- 用BibTeX生成參考文獻
昨boss要往期Elsevier 刊投文章,距上次排版貌似過了好久,生疏了不少,翻出以前的寫的一些筆記再複習複習。 不過這次好多了,僅僅是改個格式,原始的文章已經用latex編寫過了(個人感覺最頭疼的就是表格,特別是各種巢狀,真是。。。) 直接在官網上找了半天沒有
java 8(三)--用Optional取代null
一、引言先假設有三個類,Student, Bag, Book:class Student{ private Bag bag; public Student(Bag bag) {
C++ Builder高手進階 (三)用BCB設計DBTreeView元件(小結)
用BCB設計DBTreeView元件小結<?xml:namespace prefix = o ns = "urn:schemas-microsoft-com:office:office" /> 續二的最後一個函式,你是不是感到很納悶:這個函式到底是用來幹什麼的
深度學習筆記(三)用Torch實現多層感知器
上一次我們使用了輸出節點和輸入節點直接相連的網路。網路裡只有兩個可變引數。這種網路只能表示一條直線,不能適應複雜的曲線。我們將把它改造為一個多層網路。一個輸入節點,然後是兩個隱藏層,每個隱藏層有3個節點,每個隱藏節點後面都跟一個非線性的Sigmoid函式。如圖所示,這次
C++讀寫excel檔案(三)—— 用OLE讀寫
轉自http://blog.csdn.net/yukin_xue/article/details/11209283 參考博文: http://blog.csdn.net/rekrad/article/details/7666196http://blog.csdn.net/