
資料清洗- Pandas 清洗“髒”資料(一)
概要
- 準備工作
- 檢查資料
- 處理缺失資料
- 新增預設值
- 刪除不完整的行
- 刪除不完整的列
- 規範化資料型別
- 必要的轉換
- 重新命名列名
- 儲存結果
- 更多資源
Pandas 是 Python 中很流行的類庫,使用它可以進行資料科學計算和資料分。他可以聯合其他資料科學計算工具一塊兒使用,比如,SciPy,NumPy 和 Matplotlib,建模工程師可以通過建立端到端的分析工作流來解決業務問題。
雖然我們可以 Python 和資料分析做很多強大的事情,但是我們的分析結果的好壞依賴於資料的好壞。很多資料集存在資料缺失,或資料格式不統一(畸形資料),或錯誤資料的情況。不管是不完善的報表,還是技術處理資料的失當都會不可避免的引起“髒”資料。
慶幸的是,Pandas 提供功能強大的類庫,不管資料處於什麼狀態,他可以幫助我們通過清洗資料,排序資料,最後得到清晰明瞭的資料。對於案例的資料,準備使用 movie_metadata.csv(連結: https://pan.baidu.com/s/1i673EsPLY2iSQWXwKO_E_w 密碼: dvqqhttps://pan.baidu.com/s/1i5zUvOD)。這個資料集包含了很多資訊,演員、導演、預算、總輸入,以及 IMDB 評分和上映時間。實際上,可以使用上百萬或者更大的資料庫,但是,案例資料集對於開始入門還是很好的。
不幸的是,有一些列的值是缺失的,有些列的預設值是0,有的是 NaN(Nota Number)。
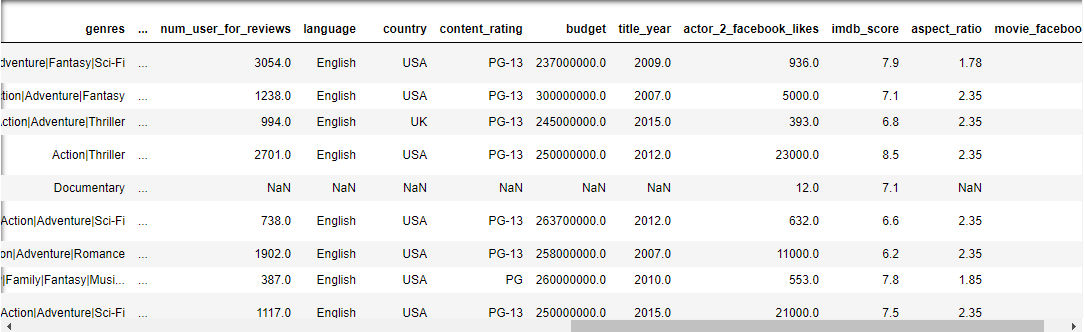
下面我們通過使用 Pandas 提供的功能來清洗“髒”資料
準備工作
首先,第一次使用 Pandas 之前,我們需要安裝 Pandas。安裝命令如下:
pip install pandas
接下來,匯入 Pandas 到我們的程式碼中,程式碼如下:
#可以使用其他的別名, 但是,pd 是官方推薦的別名,也是大家習慣的別名
import pandas as pd
最後,載入資料集,程式碼如下:
data = pd.read_csv('../data/tmdb_5000_credits.csv')
注意,確保已經下載資料集,如果你的程式碼和資料集的存放結構與我的一樣,直接執行就可以
否則,要根據實際的情況,修改 read_csv() 的檔案路徑
檢查資料
檢查一下我們剛剛讀入資料的基本結構,Pandas 提供了 head() 方法列印輸出前五行資料。目的是讓我們對讀入的資料有一個大致的瞭解。
data.head()
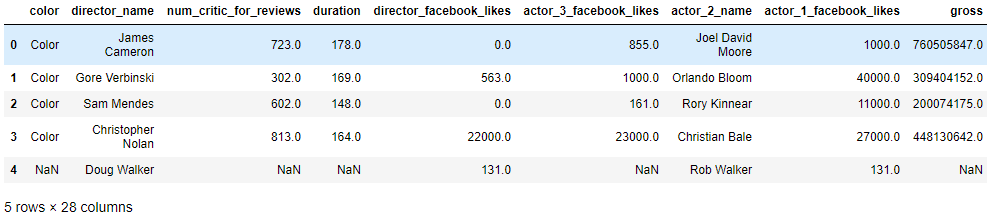
我們可以通過上面介紹的 Pandas 的方法檢視資料,也可以通過傳統的 Excel 程式檢視資料,這個時候,我們可以開始記錄資料上的問題,然後,我們再想辦法解決問題。
Pandas 提供了一些選擇的方法,這些選擇的方法可以把資料切片,也可以把資料切塊。下面我們簡單介紹一下:
- 檢視一列的一些基本統計資訊:data.columnname.describe()
- 選擇一列:data['columnname']
- 選擇一列的前幾行資料:data['columnsname'][:n]
- 選擇多列:data[['column1','column2']]
- Where 條件過濾:data[data['columnname'] > condition]
處理缺失資料
缺失資料是最常見的問題之一。產生這個問題可能的原因
- 從來沒有填正確過
- 資料不可用
- 計算錯誤
無論什麼原因,只要有空白值得存在,就會引起後續的資料分析的錯誤。下面介紹幾個處理缺失資料的方法:
- 為缺失資料賦值預設值
- 去掉/刪除缺失資料行
- 去掉/刪除缺失率高的列
新增預設值
我們應該去掉那些不友好的 NaN 值。但是,我們應該用什麼值替換呢?在這裡,我們就應該稍微掌握一下資料。對於我們的例子,我們檢查一下“country”列。這一列非常簡單,然而有一些電影沒有提供地區,所以有些資料的值是 NaN。在我們的案例中,我們推斷地區並不是很重要,所以,我們可是使用“”空字串或其他預設值。
data.country= data.country.fillna('')
上面,我們就將“country”整個列使用“”空字串替換了,或者,我們也可以輕易地使用“None Given”這樣的預設值進行替換。如果想了解更多 fillna() 的詳細資訊參考pandas.DataFrame.fillna。
使用數字型別的資料,比如,電影的時長,計算像電影平均時長可以幫我們甚至是資料集。這並不是最優解,但這個持續時間是根據其他資料估算出來的。這樣的方式下,就不會因為像 0 或者 NaN這樣的值在我們分析的時候而拋錯。
data.duration = data.duration.fillna(data.duration.mean())
刪除不完整的行
假設我們想刪除任何有缺失值得行。這種操作太據侵略性,但是我們可以根據我們的需要進行擴充套件。
刪除任何包含 NA 值的行是很容的:
data.dropna()
當然,我們也可以刪除一整行的值都為 NA:
data.dropna(how='all')
我們也可以增加一些限制,在一行中有多少非空值的資料是可以保留下來的(在下面的例子中,行資料中至少要有 5 個非空值)
data.drop(thresh=5)
比如說,我們不想要不知道電影上映時間的資料:
data.dropna(subset=['title_year'])
上面的 subset 引數允許我們選擇想要檢查的列。如果是多個列,可以使用列名的 list 作為引數。
刪除不完整的列
我們可以上面的操作應用到列上。我們僅僅需要在程式碼上使用 axis=1 引數。這個意思就是操作列而不是行。(我們已經在行的例子中使用了 axis=0,因為如果我們不傳引數 axis,預設是axis=0。)
刪除一正列為 NA 的列:
data.drop(axis=1, how='all')
刪除任何包含空值的列:
data.drop(axis=1. how='any')
這裡也可以使用像上面一樣的 threshold 和 subset,更多的詳情和案例,請參考pandas.DataFrame.dropna。
規範化資料型別
有的時候,尤其當我們讀取 csv 中一串數字的時候,有的時候數值型別的數字被讀成字串的數字,或將字串的數字讀成資料值型別的數字。Pandas 還是提供了規範化我們資料型別的方式:
data = pd.read_csv('../data/moive_metadata.csv', dtype={'duration': int})
這就是告訴 Pandas ‘duration’列的型別是數值型別。同樣的,如果想把上映年讀成字串而不是數值型別,我們使用和上面類似的方法:
data = pd.read_csv('./data/moive_metadata.csv', dtype={'title_year':str})
注意,需要記住的是,再次從磁碟上讀取 csv ,確保規範化了我們的資料型別,或者在讀取之前已經儲存了中間結果。
必要的變換
人工錄入的資料可能都需要進行一些必要的變換。
- 錯別字
- 英文單詞時大小寫的不統一
- 輸入了額外的空格
將我們資料中所有的 movie_title 改成大寫:
data['movie_title'].str.upper()
同樣的,幹掉末尾空格:
data['movie_title'].str.strip()
這裡並沒有介紹關於英文的拼寫錯誤的問題,可以參考模糊匹配。
重新命名列名
最終的資料可能是有計算機生成的,那麼,列名有可能也是計算機按照一定計算規律生成的。這些列名對計算機沒有什麼,但是對於人來說可能就不夠友好,這時候,我們就需要重新命名成對人友好的列名,程式碼如下:
data,rename(columns = {‘title_year’:’release_date’, ‘movie_facebook_likes’:’facebook_likes’})
像上面這樣,我們就完成了兩個列的重新命名。需要注意的是,這個方法並沒有提供 inpalce 引數,我們需要將結果賦值給自己才可以:
data = data.rename(columns = {‘title_year’:’release_date’, ‘movie_facebook_likes’:’facebook_likes’})
儲存結果
我們完成資料清洗之後,一般會把結果再以 csv 的格式儲存下來,以便後續其他程式的處理。同樣,Pandas 提供了非常易用的方法:
data.to_csv(‘cleanfile.csv’ encoding=’utf-8’)
更多資源
這次介紹僅僅是冰山一角。有很多方式可能造成資料集變“髒”或被破壞:
- 使用者環境的不同、
- 所使用語言的差異
- 使用者輸入的差別
在這裡,我介紹了 Python 用 Pandas 清洗資料最一般的方式。
概要
- 瞭解資料
- 分析資料問題
- 清洗資料
- 整合程式碼
瞭解資料
在處理任何資料之前,我們的第一任務是理解資料以及資料是幹什麼用的。我們嘗試去理解資料的列/行、記錄、資料格式、語義錯誤、缺失的條目以及錯誤的格式,這樣我們就可以大概瞭解資料分析之前要做哪些“清理”工作。
本次我們需要一個 patient_heart_rate.csv (連結:https://pan.baidu.com/s/1geX8oYf 密碼:odj0)的資料檔案,這個資料很小,可以讓我們一目瞭然。這個資料是 csv 格式。資料是描述不同個體在不同時間的心跳情況。資料的列資訊包括人的年齡、體重、性別和不同時間的心率。
import pandas as pd
df = pd.read_csv('../data/patient_heart_rate.csv')
df.head()

分析資料問題
- 沒有列頭
- 一個列有多個引數
- 列資料的單位不統一
- 缺失值
- 空行
- 重複資料
- 非 ASCII 字元
- 有些列頭應該是資料,而不應該是列名引數
清洗資料
下面我們就針對上面的問題一一擊破。
1. 沒有列頭
如果我們拿到的資料像上面的資料一樣沒有列頭,Pandas 在讀取 csv 提供了自定義列頭的引數。下面我們就通過手動設定列頭引數來讀取 csv,程式碼如下:
import pandas as pd
# 增加列頭
column_names= ['id', 'name', 'age', 'weight','m0006','m0612','m1218','f0006','f0612','f1218']
df = pd.read_csv('../data/patient_heart_rate.csv', names = column_names)
df.head()

上面的結果展示了我們自定義的列頭。我們只是在這次讀取 csv 的時候,多了傳了一個引數 names = column_names,這個就是告訴 Pandas 使用我們提供的列頭。
2. 一個列有多個引數
在資料中不難發現,Name 列包含了兩個引數 Firtname 和 Lastname。為了達到資料整潔目的,我們決定將 name 列拆分成 Firstname 和 Lastname
從技術角度,我們可以使用 split 方法,完成拆分工作。
我們使用 str.split(expand=True),將列表拆成新的列,再將原來的 Name 列刪除
# 切分名字,刪除源資料列
df[['first_name','last_name']] = df['name'].str.split(expand=True)
df.drop('name', axis=1, inplace=True)

上面就是執行執行程式碼之後的結果。
3. 列資料的單位不統一
如果仔細觀察資料集可以發現 Weight 列的單位不統一。有的單位是 kgs,有的單位是 lbs
# 獲取 weight 資料列中單位為 lbs 的資料
rows_with_lbs = df['weight'].str.contains('lbs').fillna(False)
df[rows_with_lbs]

為了解決這個問題,將單位統一,我們將單位是 lbs 的資料轉換成 kgs。
# 將 lbs 的資料轉換為 kgs 資料
for i,lbs_row in df[rows_with_lbs].iterrows():
weight = int(float(lbs_row['weight'][:-3])/2.2)
df.at[i,'weight'] = '{}kgs'.format(weight)

4. 缺失值
在資料集中有些年齡、體重、心率是缺失的。我們又遇到了資料清洗最常見的問題——資料缺失。一般是因為沒有收集到這些資訊。我們可以諮詢行業專家的意見。典型的處理缺失資料的方法:
- 贗品:使用合法的初始值替換,數值型別可以使用 0,字串可以使用空字串“”
- 均值:使用當前列的均值
- 高頻:使用當前列出現頻率最高的資料
- 源頭優化:如果能夠和資料收集團隊進行溝通,就共同排查問題,尋找解決方案。
5. 空行
仔細對比會發現我們的資料中一行空行,除了 index 之外,全部的值都是 NaN。
Pandas 的 read_csv() 並沒有可選引數來忽略空行,這樣,我們就需要在資料被讀入之後再使用 dropna() 進行處理,刪除空行.
# 刪除全空的行 df.dropna(how='all',inplace=True)

6. 重複資料
有的時候資料集中會有一些重複的資料。在我們的資料集中也添加了重複的資料。

首先我們校驗一下是否存在重複記錄。如果存在重複記錄,就使用 Pandas 提供的 drop_duplicates() 來刪除重複資料。
# 刪除重複資料行 df.drop_duplicates(['first_name','last_name'],inplace=True)
7. 非 ASCII 字元
在資料集中 Fristname 和 Lastname 有一些非 ASCII 的字元。
處理非 ASCII 資料方式有多種
- 刪除
- 替換
- 僅僅提示一下
我們使用刪除的方式:
# 刪除非 ASCII 字元
df['first_name'].replace({r'[^\x00-\x7F]+':''}, regex=True, inplace=True)
df['last_name'].replace({r'[^\x00-\x7F]+':''}, regex=True, inplace=True)

8. 有些列頭應該是資料,而不應該是列名引數
有一些列頭是有性別和時間範圍組成的,這些資料有可能是在處理收集的過程中進行了行列轉換,或者收集器的固定命名規則。這些值應該被分解為性別(m,f),小時單位的時間範圍(00-06,06-12,12-18)

# 切分 sex_hour 列為 sex 列和 hour 列
sorted_columns = ['id','age','weight','first_name','last_name']
df = pd.melt(df,
id_vars=sorted_columns,var_name='sex_hour',value_name='puls_rate').sort_values(sorted_columns)
df[['sex','hour']] = df['sex_hour'].apply(lambda x:pd.Series(([x[:1],'{}-{}'.format(x[1:3],x[3:])])))[[0,1]]
df.drop('sex_hour', axis=1, inplace=True)
# 刪除沒有心率的資料
row_with_dashes = df['puls_rate'].str.contains('-').fillna(False)
df.drop(df[row_with_dashes].index,
inplace=True)

整合程式碼
import pandas as pd
# 增加列頭
column_names= ['id', 'name', 'age', 'weight','m0006','m0612','m1218','f0006','f0612','f1218']
df = pd.read_csv('../data/patient_heart_rate.csv', names = column_names)
# 切分名字,刪除源資料列
df[['first_name','last_name']] = df['name'].str.split(expand=True)
df.drop('name', axis=1, inplace=True)
# 獲取 weight 資料列中單位為 lbs 的資料
rows_with_lbs = df['weight'].str.contains('lbs').fillna(False)
df[rows_with_lbs]
# 將 lbs 的資料轉換為 kgs 資料
for i,lbs_row in df[rows_with_lbs].iterrows():
weight = int(float(lbs_row['weight'][:-3])/2.2)
df.at[i,'weight'] = '{}kgs'.format(weight)
# 刪除全空的行
df.dropna(how='all',inplace=True)
# 刪除重複資料行
df.drop_duplicates(['first_name','last_name'],inplace=True)
# 刪除非 ASCII 字元
df['first_name'].replace({r'[^\x00-\x7F]+':''}, regex=True, inplace=True)
df['last_name'].replace({r'[^\x00-\x7F]+':''}, regex=True, inplace=True)
# 切分 sex_hour 列為 sex 列和 hour 列
sorted_columns = ['id','age','weight','first_name','last_name']
df = pd.melt(df,
id_vars=sorted_columns,var_name='sex_hour',value_name='puls_rate').sort_values(sorted_columns)
df[['sex','hour']] = df['sex_hour'].apply(lambda x:pd.Series(([x[:1],'{}-{}'.format(x[1:3],x[3:])])))[[0,1]]
df.drop('sex_hour', axis=1, inplace=True)
# 刪除沒有心率的資料
row_with_dashes = df['puls_rate'].str.contains('-').fillna(False)
df.drop(df[row_with_dashes].index,
inplace=True)
# 重置索引,不做也沒關係,主要是為了看著美觀一點
df = df.reset_index(drop=True)
print(df)
還有一些問題在本例中沒有提及內容,下面有兩個比較重要,也比較通用的問題:
- 日期的處理
- 字元編碼的問題
預覽資料
這次我們使用 Artworks.csv ,我們選取 100 行資料來完成本次內容。具體步驟:
- 匯入 Pandas
- 讀取 csv 資料到 DataFrame(要確保資料已經下載到指定路徑)
DataFrame 是 Pandas 內建的資料展示的結構,展示速度很快,通過 DataFrame 我們就可以快速的預覽和分析資料。程式碼如下:
import pandas as pd
df = pd.read_csv('../data/Artworks.csv').head(100)
df.head(10)

統計日期資料
我們仔細觀察一下 Date 列的資料,有一些資料是年的範圍(1976-1977),而不是單獨的一個年份。在我們使用年份資料畫圖時,就不能像單獨的年份那樣輕易的畫出來。我們現在就使用 Pandas 的 value_counts() 來統計一下每種資料的數量。
首先,選擇要統計的列,並呼叫 value_counts():
df['Date'].value_counts()

日期資料問題
Date 列資料,除了年份是範圍外,還有三種非正常格式。下面我們將這幾種列出來:
- 問題一,時間範圍(1976-77)
- 問題二,估計(c. 1917,1917 年前後)
- 問題三,缺失資料(Unknown)
- 問題四,無意義資料(n.d.)
接下來我們會處理上面的每一個問題,使用 Pandas 將這些不規則的資料轉換為統一格式的資料。
問題一和二是有資料的只是格式上欠妥當,問題三和四實際上不是有效資料。針對前兩個問題,我們可以通過程式碼將據格式化來達到清洗的目的,然而,後兩個問題,程式碼上只能將其作為缺失值來處理。簡單起見,我們將問題三和四的資料處理為0。
處理問題一
問題一的資料都是兩個年時間範圍,我們選擇其中的一個年份作為清洗之後的資料。為了簡單起見,我們就使用開始的時間來替換這樣問題的資料,因為這個時間是一個四位數的數字,如果要使用結束的年份,我們還要補齊前兩位的數字。
首先,我們需要找到問題一的資料,這樣我們才能將其更新。要保證其他的資料不被更新,因為其他的資料有可能是已經格式化好的,也有可能是我們下面要處理的。
我們要處理的時間範圍的資料,其中包含有“-”,這樣我們就可以通過這個特殊的字串來過濾我們要處理的資料,然後,通過 split() 利用“-”將資料分割,將結果的第一部分作為處理的最終結果。
程式碼如下
row_with_dashes = df['Date'].str.contains('-').fillna(False)
for i, dash in df[row_with_dashes].iterrows():
df.at[i,'Date'] = dash['Date'][0:4]
df['Date'].value_counts()
處理問題二
問題二的資料體現了資料本身的不準確性,是一個估計的年份時間,我們將其轉換為年份,那麼,就只要保留最後四位數字即可,該資料的特點就是資料包含“c”,這樣我們就可以通過這一特徵將需要轉換的資料過濾出來。
row_with_cs = df['Date'].str.contains('c').fillna(False)
for i,row in df[row_with_cs].iterrows():
df.at[i,'Date'] = row['Date'][-4:]
df[row_with_cs]
處理問題三四
將這問題三四的資料賦值成初始值 0。
df['Date'] = df['Date'].replace('Unknown','0',regex=True)
df['Date'] = df['Date'].replace('n.d.','0',regex=True)
df['Date']

程式碼整合
mport pandas as pd
df = pd.read_csv('../data/Artworks.csv').head(100)
df.head(10)
df['Date'].value_counts()
row_with_dashes = df['Date'].str.contains('-').fillna(False)
for i, dash in df[row_with_dashes].iterrows():
df.at[i,'Date'] = dash['Date'][0:4]
df['Date'].value_counts()
row_with_cs = df['Date'].str.contains('c').fillna(False)
for i,row in df[row_with_cs].iterrows():
df.at[i,'Date'] = row['Date'][-4:]
df['Date'].value_counts()
df['Date'] = df['Date'].replace('Unknown','0',regex=True)
df['Date'] = df['Date'].replace('n.d.','0',regex=True)
df['Date'].value_counts()