
Python分散式爬蟲詳解(三)
上一章中,利用scrapy-redis做了一個簡單的分散式爬蟲,雖然很一般(只有30個請求)但是基本能說清楚原理,本章中,將對該專案進行升級,使其成為一個完整的分散式爬蟲專案。
本章知識點:
a.代理ip的使用
b.Master端程式碼編寫
c.資料轉存到mysql
一、使用代理ip
在 中,介紹了ip代理池的獲取方式,那麼獲取到這些ip代理後如何使用呢?
首先,在setting.py檔案中建立USER_AGENTS和PROXIES兩個列表:
USER_AGENTS = [ 'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36', 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4094.1 Safari/537.36' ] PROXIES = [ {'ip_port': '118.190.95.43:9001', "user_passwd": None}, {'ip_port': '61.135.217.7:80', "user_passwd": None}, {'ip_port': '118.190.95.35:9001', "user_passwd": None}, ]
我們知道,下載中介軟體是介於Scrapy的request/response處理的鉤子,每個請求都需要經過中介軟體。所以在middlewares.py中新建兩個類,用於隨機選擇使用者代理和ip代理:
# 隨機的User-Agent class RandomUserAgent(object): def process_request(self, request, spider): useragent = random.choice(USER_AGENTS) #print useragent request.headers.setdefault("User-Agent", useragent) # 隨機的代理ip class RandomProxy(object): def process_request(self, request, spider): proxy = random.choice(PROXIES) # 沒有代理賬戶驗證的代理使用方式 request.meta['proxy'] = "http://" + proxy['ip_port']
在setting.py中開啟下載中介軟體:
DOWNLOADER_MIDDLEWARES = {
'dytt_redis_slaver.middlewares.RandomUserAgent': 543,
'dytt_redis_slaver.middlewares.RandomProxy': 553,
}
二、Master端程式碼
Scrapy-Redis分散式策略中,Master端(核心伺服器),不負責爬取資料,只負責url指紋判重、Request的分配,以及資料的儲存,但是一開始要在Master端中lpush開始位置的url,這個操作可以在控制檯中進行,開啟控制檯輸入:
redis-cli
127.0.0.1:6379> lpush dytt:start_urls https://www.dy2018.com/0/
也可以寫一個爬蟲對url進行爬取,然後動態的lpush到redis資料庫中,這種方法對於url數量多且有規律的時候很有用(不需要在控制檯中一條一條去lpush,當然最省事的方法是在slaver端程式碼中增加rule規則去實現url的獲取)。比如要想獲取所有電影的分類。
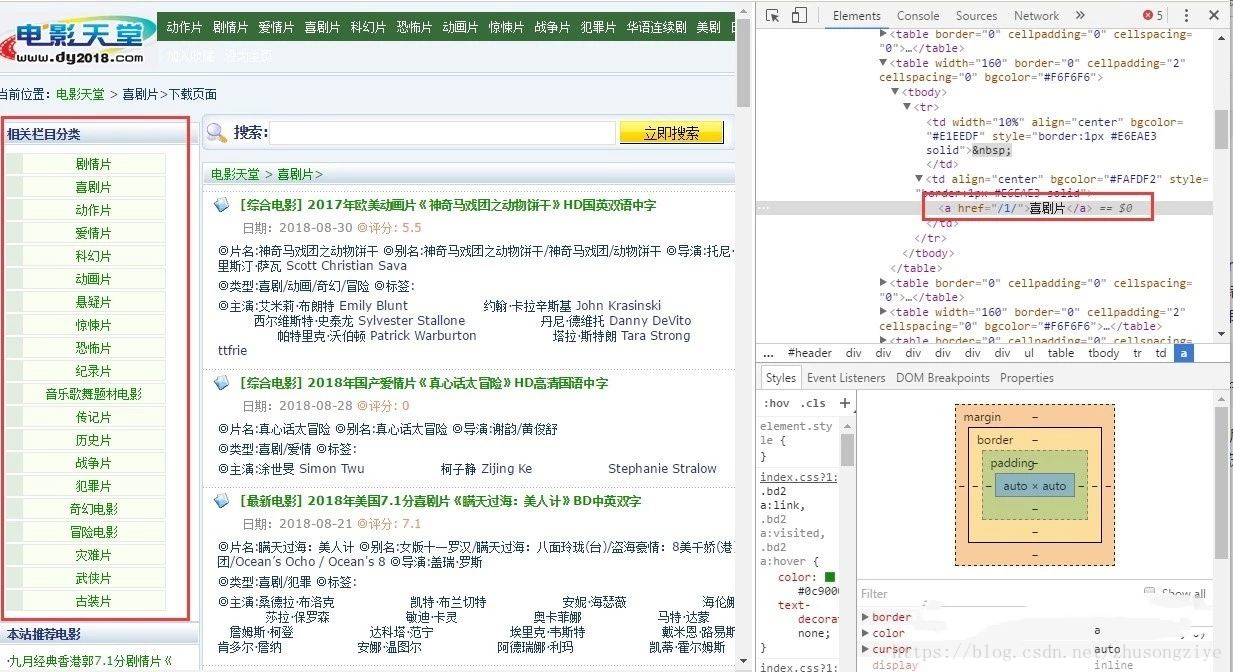
連結就是一個或者兩個數字,所以rule規則為:
rules = (
Rule(LinkExtractor(allow=r'/\d{1,2}/$'), callback='parse_item'),
)
在parse_item中返回這個請求連結:
def parse_item(self, response):
# print(response.url)
items = DyttRedisMasterItem()
items['url'] = response.url
yield items
piplines.py中,將獲得的url全部lpush到redis資料庫:
import redis
class DyttRedisMasterPipeline(object):
def __init__(self):
# 初始化連線資料的變數
self.REDIS_HOST = '127.0.0.1'
self.REDIS_PORT = 6379
# 連結redis
self.r = redis.Redis(host=self.REDIS_HOST, port=self.REDIS_PORT)
def process_item(self, item, spider):
# 向redis中插入需要爬取的連結地址
self.r.lpush('dytt:start_urls', item['url'])
return item
執行slaver端時,程式會等待請求的到來,當starts_urls有值的時候,爬蟲將開始爬取,但是一開始並沒有資料,因為會過濾掉重複的連結:
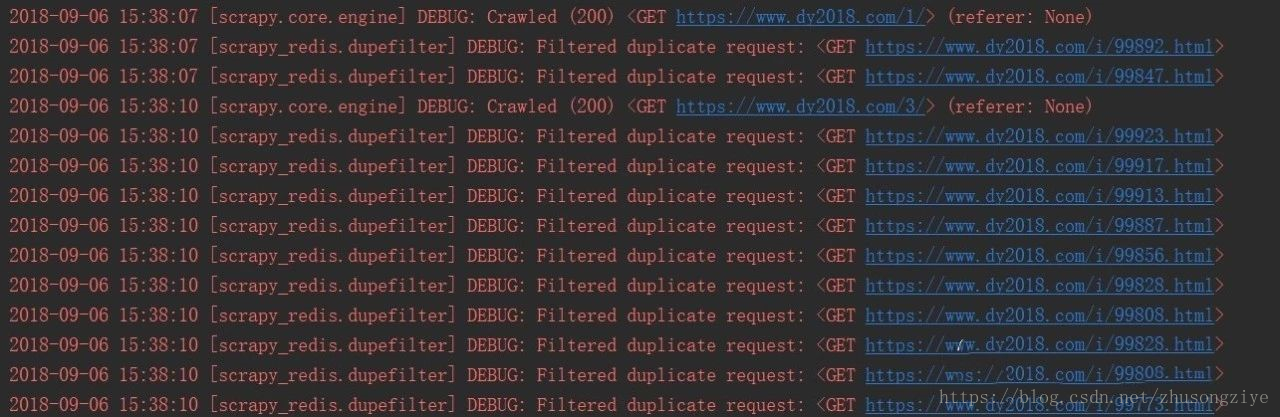
畢竟有些電影的型別不止一種:
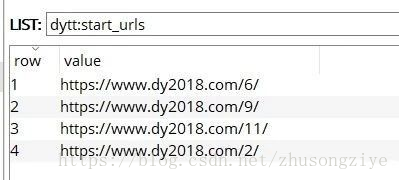
scrapy預設16個執行緒(當然可以修改為20個啊),而分類有20個,所以start_urls會隨機剩下4個,等待任務分配:
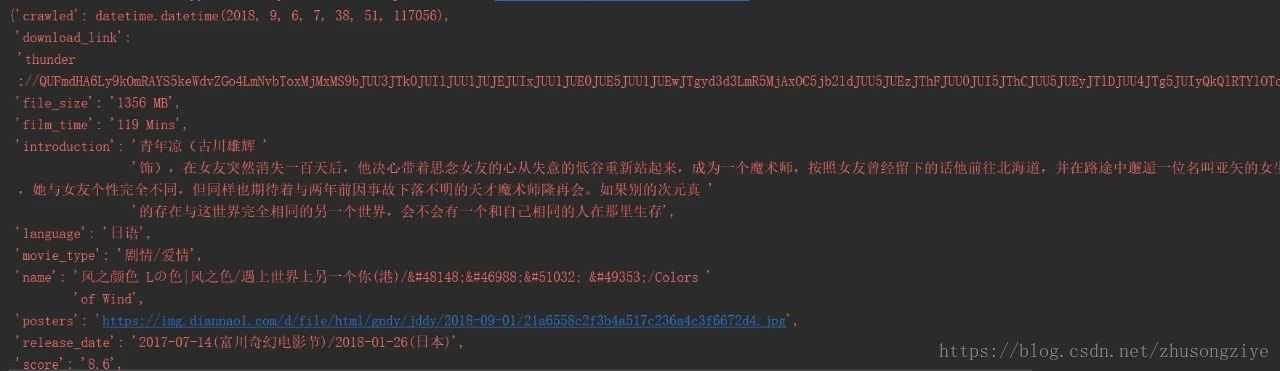
當連結過濾完畢後,就有資料了:
因為在setting.py中設定了:
SCHEDULER_PERSIST = True
所以重新啟動爬蟲的時候,會接著之前未完成的任務進行爬取。在slaver端中新增rule規則可以實現翻頁功能:
page_links = LinkExtractor(allow=r'/index_\d*.html')
rules = (
# 翻頁規則
Rule(page_links),
# 進入電影詳情頁
Rule(movie_links, callback='parse_item'),
)
三、資料轉存到Mysql
因為,redis只支援String,hashmap,set,sortedset等基本資料型別,但是不支援聯合查詢,所以它適合做快取。將資料轉存到mysql資料庫中,方便以後查詢:
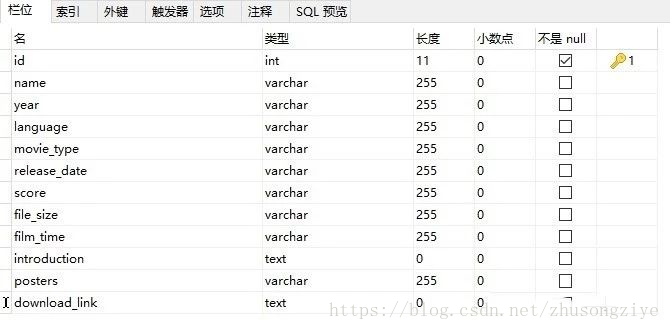
建立資料表:
程式碼如下:
# -*- coding: utf-8 -*-
import json
import redis
import pymysql
def main():
# 指定redis資料庫資訊
rediscli = redis.StrictRedis(host='127.0.0.1', port=6379, db=0)
# 指定mysql資料庫
mysqlcli = pymysql.connect(host='127.0.0.1', user='root', passwd='zhiqi', db='Scrapy', port=3306, use_unicode=True)
while True:
# FIFO模式為 blpop,LIFO模式為 brpop,獲取鍵值
source, data = rediscli.blpop(["dytt_slaver:items"])
item = json.loads(data)
try:
# 使用cursor()方法獲取操作遊標
cur = mysqlcli.cursor()
# 使用execute方法執行SQL INSERT語句
cur.execute("INSERT INTO dytt (name, year, language, "
"movie_type, release_date, score, file_size, "
"film_time, introduction, posters, download_link) VALUES "
"(%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s )",
[item['name'], item['year'], item['language'],
item['movie_type'], item['release_date'], item['score'],
item['file_size'], item['film_time'], item['introduction'],
item['posters'], item['download_link']])
# 提交sql事務
mysqlcli.commit()
#關閉本次操作
cur.close()
print ("inserted %s" % item['name'])
except pymysql.Error as e:
print ("Mysql Error %d: %s" % (e.args[0], e.args[1]))
if __name__ == '__main__':
main()
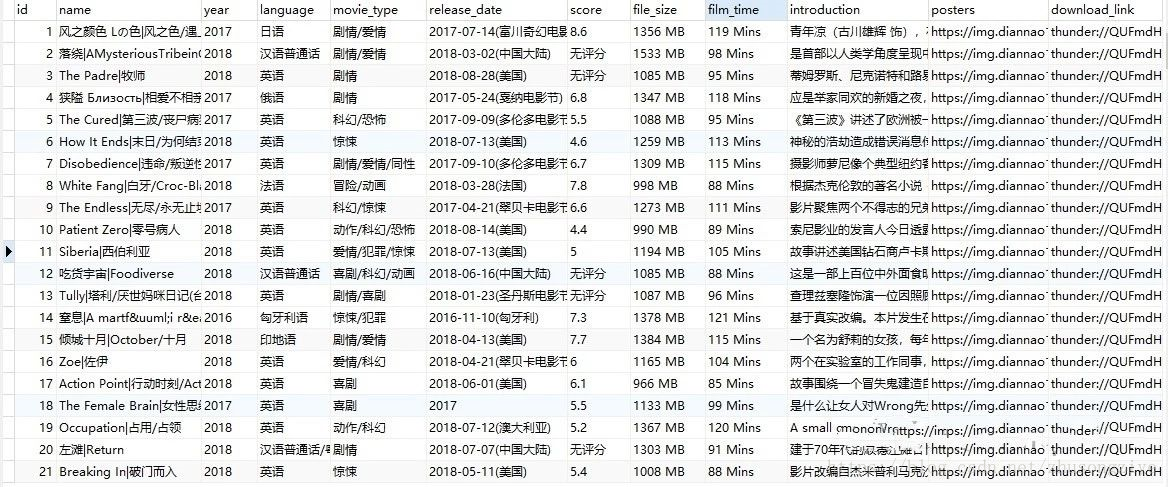
最終結果:
專案地址:
https://github.com/ZhiqiKou/Scrapy_notes