深度學習下海血淚史【2】VGG回顧
0 摘要
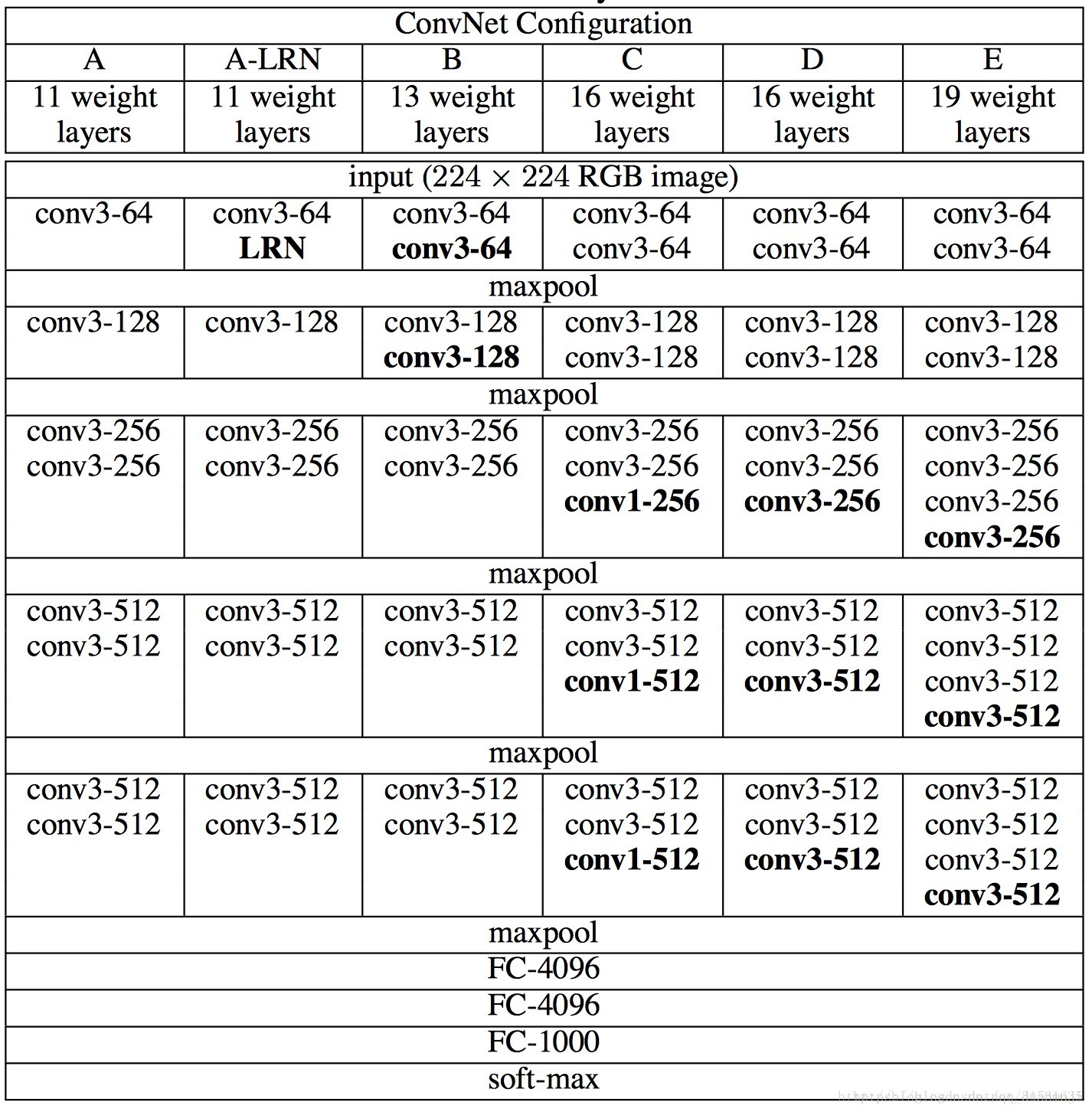
VGG模型(由牛津大學Visual Geometry Group提出)是2014年ILSVRC競賽的第二名,第一名是GoogLeNet。VGG模型在多個遷移學習任務中的表現要優於GoogLeNet,缺點是其引數量達140M之多,需要更大的儲存空間。 VGGNet 特點:
- 小卷積核。作者將卷積核全部替換為3x3(極少用了1x1)
- 小池化核。相比AlexNet的3x3的池化核,VGG全部為2x2的池化核
- 層數更深特徵圖更寬。基於前兩點外,由於卷積核專注於擴大通道數、池化專注於縮小寬和高,使得模型架構上更深更寬的同時,計算量的增加放緩
- 全連線轉卷積。網路測試階段將訓練階段的三個全連線替換為三個卷積,測試重用訓練時的引數,使得測試得到的全卷積網路因為沒有全連線的限制,因而可以接收任意寬或高為的輸入
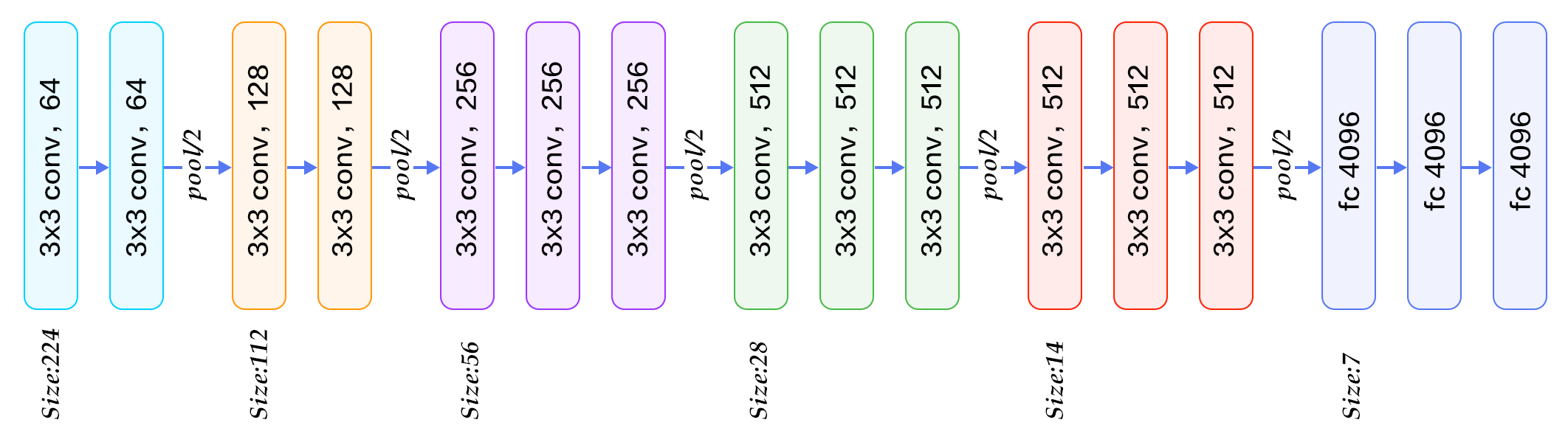
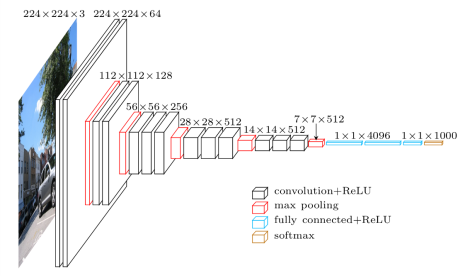
1 網路架構
VGG使用兩種卷積核 1x1卷積核:降維,增加非線性性(ReLU的效果) 3x3卷積核:多個卷積核疊加,增加空間感受野,減少引數
1.1 小卷積核
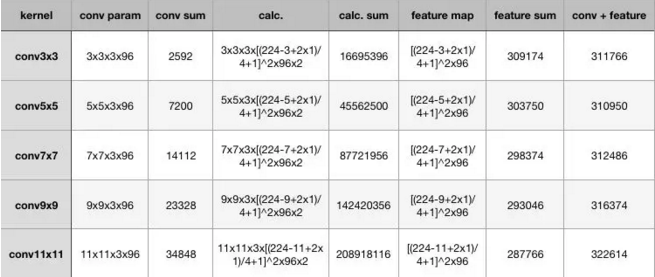
卷積不僅涉及到計算量(卷積核尺寸小的計算量小,由下圖可知),還影響到感受野。前者關係到是否方便部署到移動端、是否能滿足實時處理、是否易於訓練等,後者關係到引數更新、特徵圖的大小、特徵是否提取的足夠多、模型的複雜度和引數量等等。 由 【1.2 感受野】可知,可用兩層3*3的卷積層替代5*5卷積,層數更多,經歷兩次ReLU使得決策函式(decision function)的判斷力更強,同時減少計算量
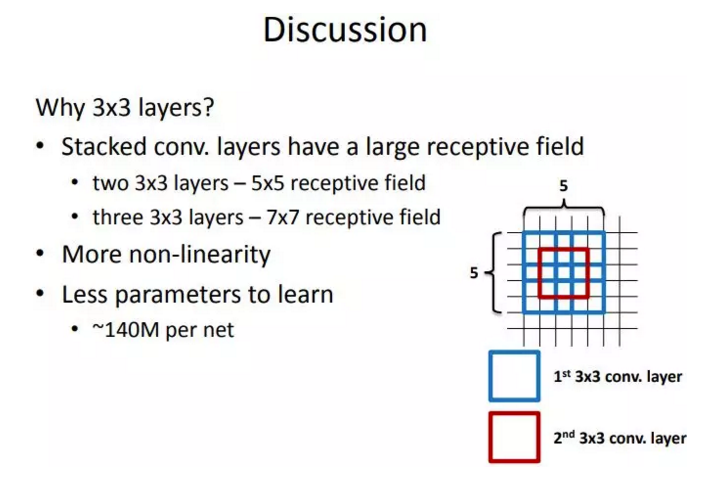
1.2 感受野
作者認為兩個3x3的卷積堆疊獲得的感受野大小,相當一個5x5的卷積;而3個3x3卷積的堆疊獲取到的感受野相當於一個7x7的卷積。
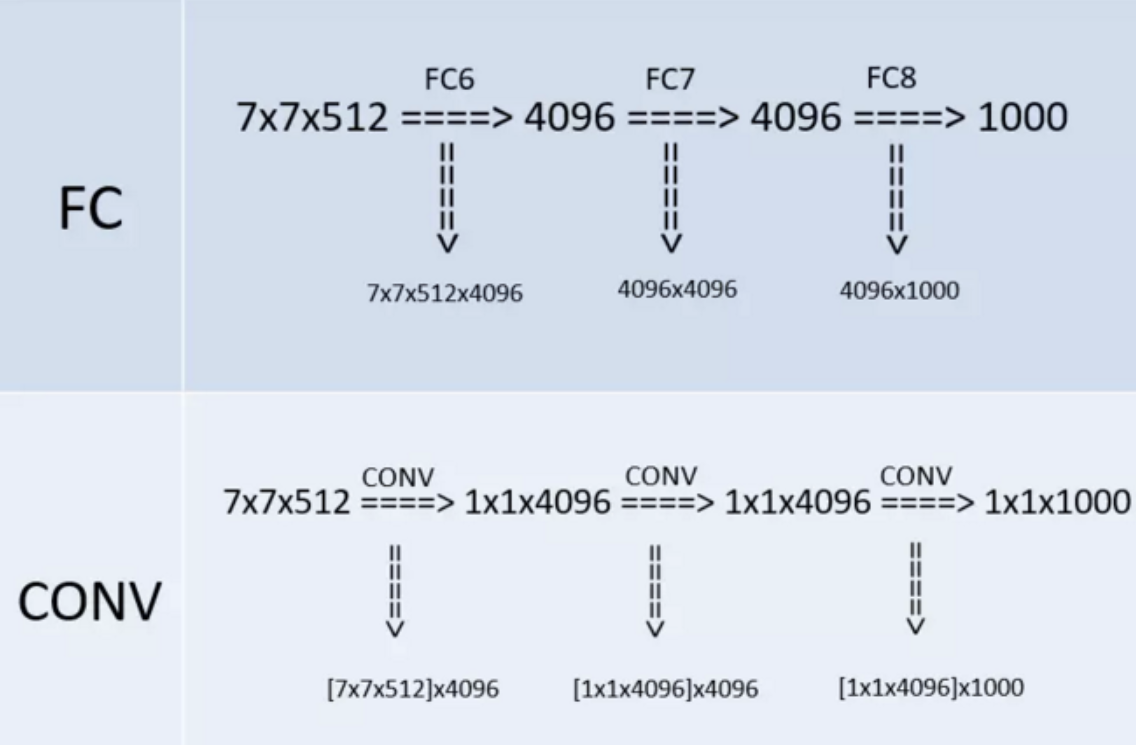
1.3 全連線轉卷積
下圖的上半部分是訓練階段,最後三層都是FC。下半部分是測試階段,最後三層都是CONV。VGG的作者把訓練階段的全連線替換為卷積是參考了OverFeat的工作,OverFeat將全連線換成卷積後,帶來可以處理任意解析度(在整張圖)上計算卷積,而無需對原圖resize的優勢。
1.4 1x1卷積
VGG在最後的三個階段都用到了1x1卷積核,選用1x1卷積核的最直接原因是在維度上繼承全連線,然而作者首先認為1x1卷積可以增加決策函式(decision function,這裡的決策函式我認為就是softmax)的非線效能力,非線性是由啟用函式ReLU決定的,本身1x1卷積則是線性對映,即將輸入的feature map對映到同樣維度的feature map。
2 訓練細節
2.1 初始化策略
對於深度網路來說,網路權值的初始化十分重要。為此,論文中首先訓練一個淺層的網路結構A,訓練這個淺層的網路時,隨機初始化它的權重就足夠得到比較好的結果。然後,當訓練深層的網路時,前四層卷積層和最後的三個全連線層使用的是學習好的A網路的權重來進行初始化,而其餘層則隨機初始化。這也就是上一點提到的某些層的預初始化。(隨機初始化權重時,使用的是0均值,方差0.01的正態分佈;偏置則都初始化為0)。
2.2 訓練資料增強
S是訓練影象的最小邊。訓練尺度 Q是測試影象的最小邊。測試尺度 對原始圖片進行等比例縮放,使得S大於224,然後在圖片上隨機提取224x224視窗,進行訓練。
- 單一尺度訓練:固定 S 的大小,對應了單一尺度的訓練,訓練多個分類器。訓練S=256和S=384兩個分類器,其中S=384的分類器用S=256的權重進行初始化;
- 多尺度(Multi-scale)訓練(尺度抖動):直接訓練一個分類器,每次資料輸入的時候,每張圖片被重新縮放,縮放的短邊S隨機從[256,512]中選擇一個,也可以認為通過尺度抖動(scale jittering)進行訓練集增強。影象中的目標可能具有不同的大小,所以訓練時認為這是有用的。
3 實驗結論
- LRN層無效能增益(A和A-LRN)。作者通過網路A和A-LRN發現AlexNet曾經用到的LRN層(local response normalization,LRN是一種跨通道去normalize畫素值的方法)沒有效能提升,因此在後面的4組網路中均沒再出現LRN層。 當然我也感覺沒啥用,想到max-pooling比average-pooling效果好,我就感覺這個LRN沒啥用,不過如果把LRN改成跨通道的max-normal,我感覺說不定會有效能提升。特徵得到retain更明顯。
- 深度增加,分類效能提高(A、B、C、D、E)。從11層的A到19層的E,網路深度增加對top1和top5的error下降很明顯,所以作者得出這個結論,但其實除了深度外,其他幾個網路寬度等因素也在變化,depth matters的結論不夠convincing。
- conv1x1的非線性變化有作用(C和D)。C和D網路層數相同,但D將C的3個conv3x3換成了conv1x1,效能提升。這點我理解是,跨通道的資訊交換/融合,可以產生豐富的特徵易於分類器學習。conv1x1相比conv3x3不會去學習local的區域性畫素資訊,專注於跨通道的資訊交換/融合,同時為後面全連線層(全連線層相當於global卷積)做準備,使之學習過程更自然。
- 多小卷積核比單大卷積核效能好(B)。作者做了實驗用B和自己一個不在實驗組裡的較淺網路比較,較淺網路用conv5x5來代替B的兩個conv3x3。多個小卷積核比單大卷積核效果好,換句話說當考慮卷積核大小時:depths matters。

4 附圖