
如何使用scrapyd部署爬蟲專案
功能:相當於一個伺服器,用於將自己本地的爬蟲程式碼,打包上傳到伺服器上,讓這個爬蟲在伺服器上執行,可以實現對爬蟲的遠端管理。(遠端啟動爬蟲、關閉爬蟲、檢視爬蟲的一些日誌)
1.scrapyd的安裝:在cmd中,輸入指令
:pip install scrapyd
2.安裝服務與客戶端
a>scrapyd提供了一個客戶端工具,就是scrapyd-client,使用這個工具對scrapyd這個服務進行操作,比如:向scrapyd服務打包上傳專案。scrapyd-client類似於redis-cli.exe、MongoDB資料庫的client。 scrapyd-client下載地址:https://github.com/scrapy/scrapyd-client
b>pip install scrapyd-client=1.2.0a1
注意:服務端scrapyd(預設版本1.2)和客戶端scrapyd-client(預設版本1.1)安裝的版本一定要一致
3.安裝完服務與客戶端之後,啟動scrapyd,直接在cmd中輸入scrapyd就可以啟動了,服務啟動之後不要關閉cmd視窗
然後開啟瀏覽器訪問網址127.0.0.1:6800,出現以下頁面表示成功啟動scrapyd服務:
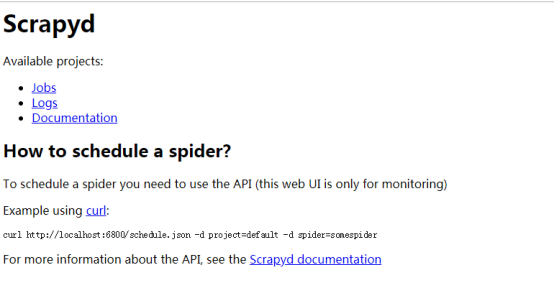
4.配置爬蟲專案,完成之後,再通過addversion.json進行打包。
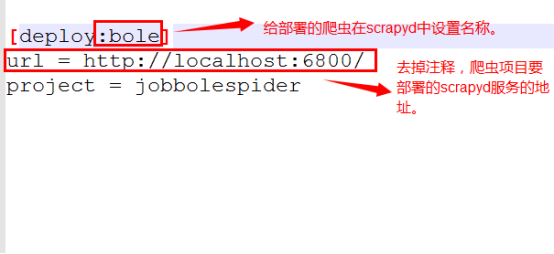
修改scrapy.cfg檔案:
5.上述的scrapyd服務視窗cmd不要關閉,再新開一個cmd視窗,用於連線scrapyd服務
a>進入專案根目錄,輸入scrapyd-deploy命令,檢視scrapyd-client客戶端是否能使用

b>檢視當前可用於打包上傳的爬蟲專案

c>使用scrapyd-deploy命令打包上傳專案;
命令:Scrapyd-deploy bole -p jobbolespider
引數:
Status: “ok”/”error” 專案上傳狀態
Project: 上傳的專案名稱
Version: 專案的版本號,值是時間戳
Spiders: 專案Project包含的爬蟲個數

d>通過API介面,檢視已經上傳至scrapyd服務的專案;
命令:curl http://localhost:6800/listprojects.json
鍵值:
Projects: [ ] 所有已經上傳的爬蟲專案,都會顯示在這個 列表中。

e>通過api介面,檢視某一個專案中的所有爬蟲名稱;
命令:curl http://localhost:6800/listspiders.json?project=jobbolespider

注意:如果專案上傳失敗,需要先將爬蟲專案中打包生成的檔案刪除(build、project.egg-info、setup.py),然後再重新打包上傳。
f>通過api介面,啟動爬蟲專案
命令:curl http://localhost:6800/schedule.json -d project="爬蟲專案名稱" -d spider="專案中某一個爬蟲名稱"
鍵值:
Jobid: 是根據專案(jobbolespider)和爬蟲(bole)生成的一個id,將來用於取消爬蟲任務。

g>如果上傳的專案無法執行,在本地調整程式碼之後,需要重新打包上傳,將失效的專案刪除
命令:curl http://localhost:6800/delproject.json -d project=jobbolespider

h>通過api介面,取消爬蟲任務;
引數:
Jobid:啟動爬蟲的時候分配的

