
Spark之Shuffle機制和原理
Spark Shuffle簡介
Shuffle就是對資料進行重組,由於分散式計算的特性和要求,在實現細節上更加繁瑣和複雜
在MapReduce框架,Shuffle是連線Map和Reduce之間的橋樑,Map階段通過shuffle讀取資料並輸出到對應的Reduce;而Reduce階段負責從Map端拉取資料並進行計算。在整個shuffle過程中,往往伴隨著大量的磁碟和網路I/O。所以shuffle效能的高低也直接決定了整個程式的效能高低。Spark也會有自己的shuffle實現過程
HashShuffle
什麼是HashShuffle?
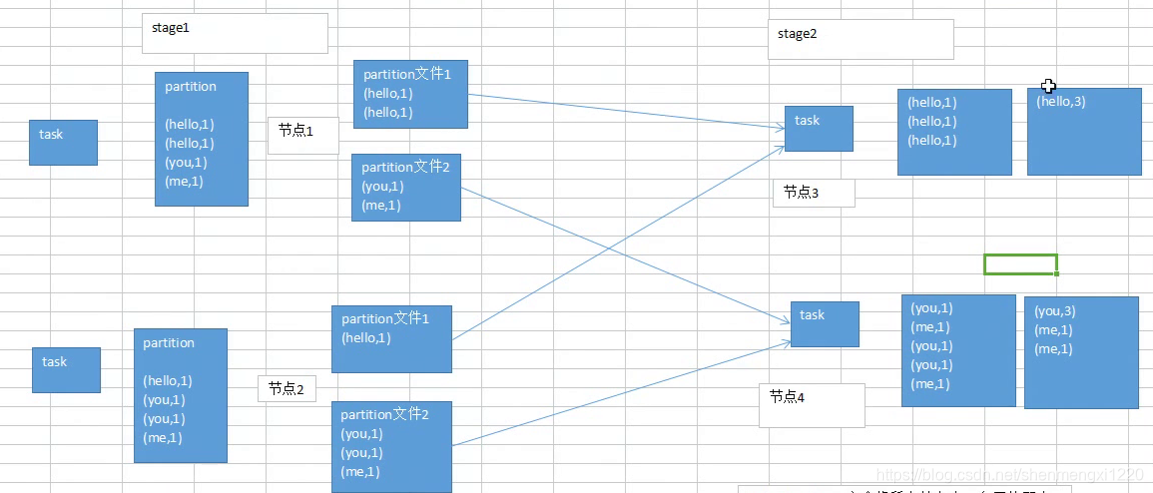
每一個task的計算結果根據key的hashcode與reduce task的個數取模決定寫入到哪一個分割槽檔案,這樣就能保證相同的資料一定是落入到某一個分割槽檔案中。
shuffle可能面臨的問題?
- 小檔案過多,耗時低效的IO操作
- 記憶體溢位,讀寫檔案以及快取過多
磁碟小檔案的個數 = map task num × reduce task num
磁碟小檔案過多帶來什麼問題?
- write階段建立大量的寫檔案的物件
- read階段就要進行多次網路通訊
- read階段建立大量的讀檔案的物件
優化後的HashShuffleManager
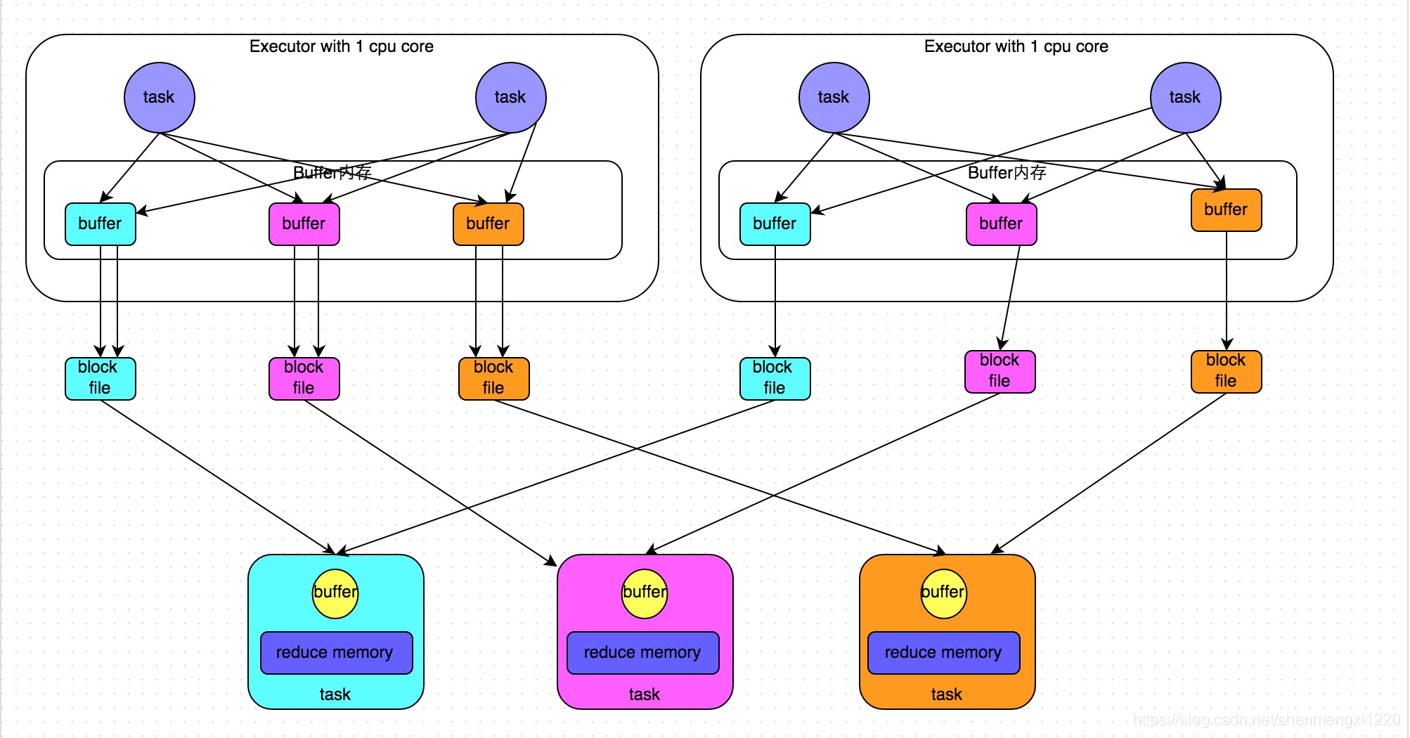
使用HashShuffle並且開啟合併機制,shuffle過程中磁碟小檔案個數為 cores × reduce task num
SortShuffle
該機制每一個MapTask不會為後續的任務建立單獨的檔案,而是會將所有的Task結果寫入同一個檔案,並且對應生成一個索引檔案。以前的資料是放在記憶體快取中,等到資料完了再刷到磁碟,現在為了減少記憶體的使用,在記憶體不夠用的時候,可以將輸出溢寫到磁碟,結束的時候,再將這些不同的檔案聯合記憶體的資料一起進行歸併,從而減少記憶體的使用量。
SortShuffle的執行機制主要分成兩種:
- 普通執行機制
- bypass執行機制
SortShuffleManager普通執行機制
比較適合資料量很大的場景或者叢集規模很大

SortShuffleManager bypass執行機制
主要用於處理Reducer任務數量比較少或不需要排序和聚合的Shuffle操作,資料是直接寫入檔案,資料量較大的時候,網路I/O和記憶體負擔較重。
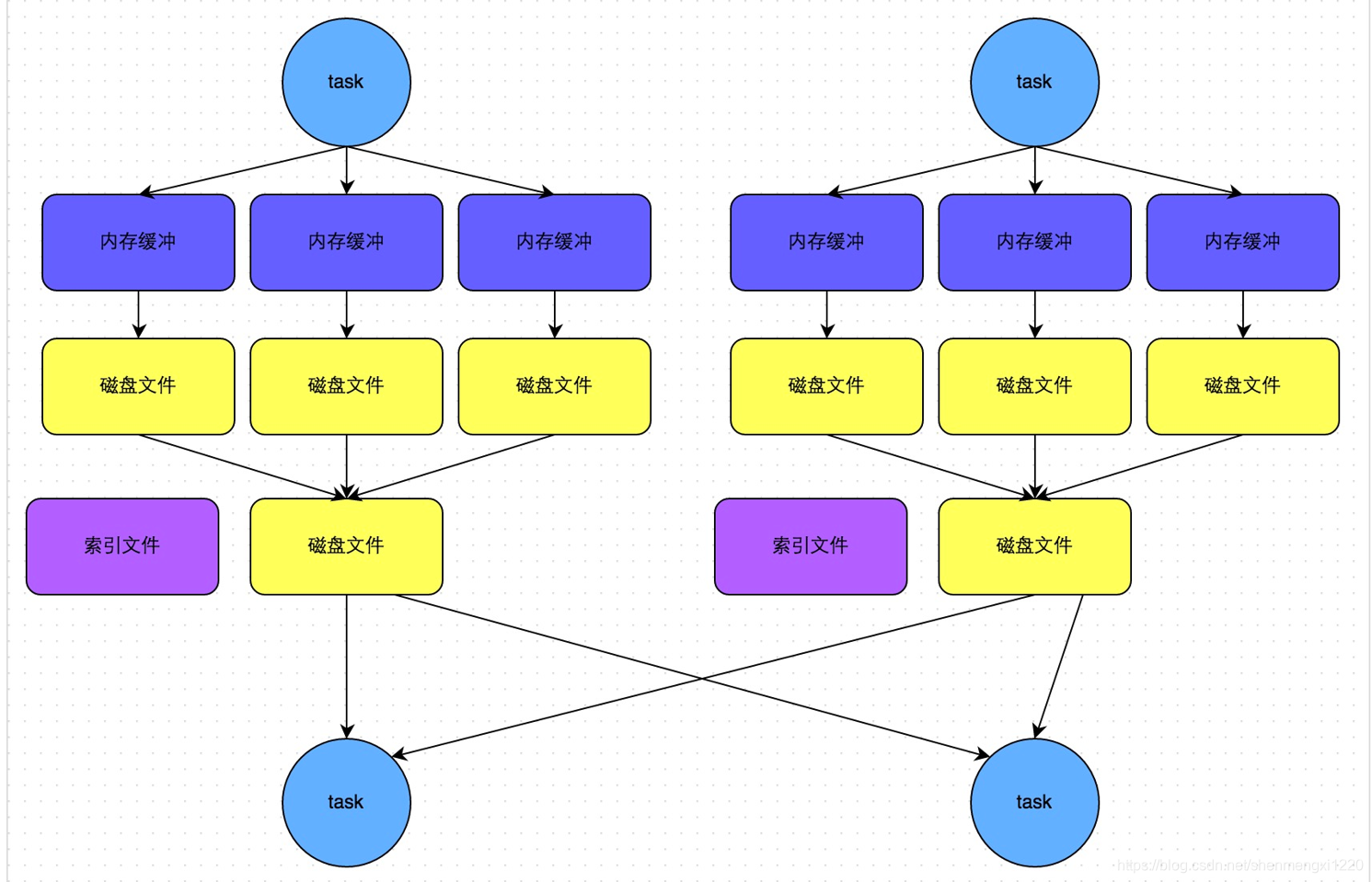
bypass執行機制的觸發條件如下:
shuffle reduce task數量小於spark.shuffle.sort.bypassMergeThreshold引數的值。