
你真的明白Java和Python3使用Unicode編碼的含義嗎?
經常會聽到Unicode是用兩個位元組表示世界上所有語言的編碼,那麼問題來了兩個位元組不過65535個符號,怎麼能表示所有語言?也經常搞不清楚Unicode和UTF-8到底有什麼區別。也曾聽說記憶體中都是Unicode統一表示,然後傳輸和儲存的時候轉換成UTF-8。總之網路時代就是這樣——眾說紛紜。這裡,我僅把此刻認為正確的說法記錄下來。
一. Unicode
世界上存在著多種編碼方式,同一個二進位制數字可以被解釋成不同的符號。因此,要想開啟一個文字檔案,就必須知道它的編碼方式,否則用錯誤的編碼方式解讀,就會出現亂碼。為什麼電子郵件常常出現亂碼?就是因為發信人和收信人使用的編碼方式不一樣。
可以想象,如果有一種編碼,將世界上所有的符號都納入其中。每一個符號都給予一個獨一無二的編碼,那麼亂碼問題就會消失。這就是 Unicode,就像它的名字所表示的,這是一種所有符號的編碼。
Unicode 當然是一個很大的集合,現在的規模可以容納100多萬個符號。每個符號的編碼都不一樣,比如,U+0639表示阿拉伯字母Ain,U+0041表示英語的大寫字母A,U+4E25表示漢字嚴。具體的符號對應表,可以查詢unicode.org,或者專門的漢字對應表。
需要注意的是,Unicode 只是一個符號集,它只規定了符號的二進位制程式碼,卻沒有規定這個二進位制程式碼應該如何儲存。
比如,漢字嚴的 Unicode 是十六進位制數4E25
100111000100101),也就是說,這個符號的表示至少需要2個位元組。表示其他更大的符號,可能需要3個位元組或者4個位元組,甚至更多。所以到這裡,我們可以明確的指出,Unicode是用兩個位元組表示字元這種說法是錯誤的。
誤區:java使用Unicode編碼,所以一個漢字用兩個位元組表示。
來解釋一下,首先明確java使用Unicode編碼的意思,所謂的java使用Unicode編碼其實是一個比較複雜的事情,說來話真的很長。
比如說,我們在.java原始檔中申請一個字串 String str = "中文"; 那麼當這個.java檔案被執行起來的時候,str在記憶體中為了表示"中文"這兩個漢字就會有一個對應的值,而這個對應的值使用的是Unicode編碼規則對應的。
但是,我們上面指出了,Unicode編碼裡中文並不是兩個位元組,可能是更多位元組來表示的,那麼java是怎麼做到只用兩個位元組來表示一箇中文的?
其實,正確來講,java使用Unicode編碼,準確來說其實是使用UTF-16,一箇中文字元絕大多數情況下都是兩個位元組。
這裡就有必要說一下UTF
二.UTF
UNICODE 來到時,一起到來的還有計算機網路的興起,UNICODE 如何在網路上傳輸也是一個必須考慮的問題,於是面向傳輸的眾多 UTF(UCS Transfer Format)標準出現了。為什麼會出現?因為如果你寫的文字基本上全部是英文的話,用Unicode編碼比ASCII編碼需要多一倍的儲存空間,在儲存和傳輸上就十分不划算。
所以,本著節約的精神,又出現了把Unicode編碼轉化為“可變長編碼”的UTF-8編碼。UTF-8編碼把一個Unicode字元根據不同的數字大小編碼成1-6個位元組,常用的英文字母被編碼成1個位元組,漢字通常是3個位元組,只有很生僻的字元才會被編碼成4-6個位元組。如果你要傳輸的文字包含大量英文字元,用UTF-8編碼就能節省空間。
再說UTF-16,即把Unicode字符集的抽象碼位對映為16位長的整數(即碼元)的序列,用於資料儲存或傳遞。UTF-16 使用二或四個位元組為每個字元編碼,其中大部分漢字採用兩個位元組編碼,少量不常用漢字採用四個位元組編碼。
誤區:記憶體和傳輸、儲存使用的是一種編碼
搞清楚了Unicode和UTF-8的關係,我們就可以總結一下現在計算機系統通用的字元編碼工作方式:
在計算機記憶體中,統一使用Unicode編碼,當需要儲存到硬碟或者需要傳輸的時候,就轉換為UTF-8編碼。
用記事本編輯的時候,從檔案讀取的UTF-8字元被轉換為Unicode字元到記憶體裡,編輯完成後,儲存的時候再把Unicode轉換為UTF-8儲存到檔案:
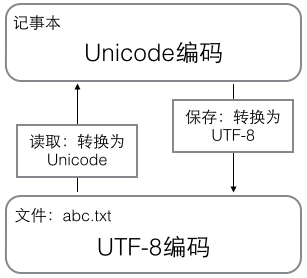
瀏覽網頁的時候,伺服器會把動態生成的Unicode內容轉換為UTF-8再傳輸到瀏覽器:
搞清楚UTF-8解決的問題和一種語言所使用的編碼(內碼)是什麼意思,對上面的說法就很容易理解
首先UTF出現就是為了在網路上傳輸和儲存中使用的,因此硬碟上或傳輸流上使用UTF-8沒有問題。
那麼為什麼記憶體中要統一使用一種編碼呢?其實也很簡單:.java原始碼檔案這個檔案本身也是有編碼的,不同.java原始檔這個編碼可以不同,當JVM去編譯這個原始檔的時候,根據這個編碼去識別才能夠正確編譯出.class檔案,並且把它們統一編碼成UTF-16在JVM中執行才不會因為各個原始檔編碼不同而出錯。
因此,同樣的道理,瀏覽網頁的時候,伺服器也用這種思路統一以Unicode編碼去執行程式,然後用UTF-8去傳輸。
最後在編寫程式中的例子去理解
python3使用Unicode編碼
str = ord('中') #ord獲取字元整數表示 這個整數表示也就是Unicode編碼去對映的 也就是'中'字在記憶體中真正表示的值
print(str)
#在記憶體中以Unicode表示,一個字元對應若干個位元組。如果要在網路上傳輸,或者儲存到磁碟上,就需要把str變為以位元組為單位的bytes
str = '中文'.encode('utf-8') #把Unicode字串編碼成utf-8的bytes
print(str)
#decode把utf-8編碼的bytes解碼成Unicode字串
str = b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8') #'中文'的utf-8編碼的bytes
print(str)output:
20013
b'\xe4\xb8\xad\xe6\x96\x87'
中文