
Java記憶體模型是什麼,為什麼要有Java記憶體模型,Java記憶體模型解決了什麼問題等。。。
本文中,有很多定義和說法,都是筆者自己理解後定義出來的。希望能夠讓讀者可以對Java記憶體模型有更加清晰的認識。當然,如有偏頗,歡迎指正。
為什麼要有記憶體模型
在介紹Java記憶體模型之前,先來看一下到底什麼是計算機記憶體模型,然後再來看Java記憶體模型在計算機記憶體模型的基礎上做了哪些事情。要說計算機的記憶體模型,就要說一下一段古老的歷史,看一下為什麼要有記憶體模型。
記憶體模型,英文名Memory Model,他是一個很老的老古董了。他是與計算機硬體有關的一個概念。那麼我先給你介紹下他和硬體到底有啥關係。
CPU和快取一致性
我們應該都知道,計算機在執行程式的時候,每條指令都是在CPU中執行的,而執行的時候,又免不了要和資料打交道。而計算機上面的資料,是存放在主存當中的,也就是計算機的實體記憶體啦。
剛開始,還相安無事的,但是隨著CPU技術的發展,CPU的執行速度越來越快。而由於記憶體的技術並沒有太大的變化,所以從記憶體中讀取和寫入資料的過程和CPU的執行速度比起來差距就會越來越大,這就導致CPU每次操作記憶體都要耗費很多等待時間。
這就像一家創業公司,剛開始,創始人和員工之間工作關係其樂融融,但是隨著創始人的能力和野心越來越大,逐漸和員工之間出現了差距,普通員工原來越跟不上CEO的腳步。老闆的每一個命令,傳到到基層員工之後,由於基層員工的理解能力、執行能力的欠缺,就會耗費很多時間。這也就無形中拖慢了整家公司的工作效率。
可是,不能因為記憶體的讀寫速度慢,就不發展CPU技術了吧,總不能讓記憶體成為計算機處理的瓶頸吧。
所以,人們想出來了一個好的辦法,就是在CPU和記憶體之間增加快取記憶體。快取的概念大家都知道,就是儲存一份資料拷貝。他的特點是速度快,記憶體小,並且昂貴。
那麼,程式的執行過程就變成了:
當程式在執行過程中,會將運算需要的資料從主存複製一份到CPU的快取記憶體當中,那麼CPU進行計算時就可以直接從它的快取記憶體讀取資料和向其中寫入資料,當運算結束之後,再將快取記憶體中的資料重新整理到主存當中。
之後,這家公司開始設立中層管理人員,管理人員直接歸CEO領導,領導有什麼指示,直接告訴管理人員,然後就可以去做自己的事情了。管理人員負責去協調底層員工的工作。因為管理人員是瞭解手下的人員以及自己負責的事情的。所以,大多數時候,公司的各種決策,通知等,CEO只要和管理人員之間溝通就夠了。
而隨著CPU能力的不斷提升,一層快取就慢慢的無法滿足要求了,就逐漸的衍生出多級快取。
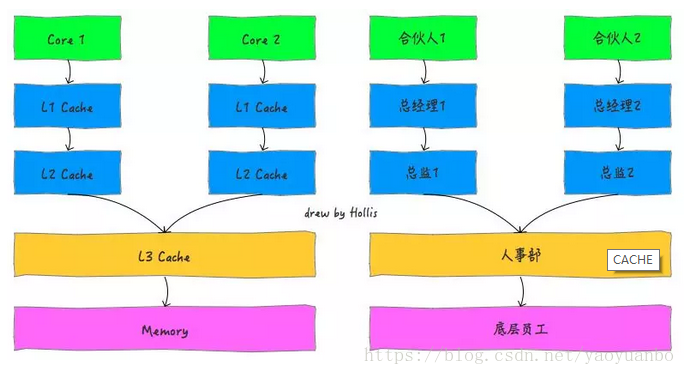
按照資料讀取順序和與CPU結合的緊密程度,CPU快取可以分為一級快取(L1),二級快取(L3),部分高階CPU還具有三級快取(L3),每一級快取中所儲存的全部資料都是下一級快取的一部分。
這三種快取的技術難度和製造成本是相對遞減的,所以其容量也是相對遞增的。
那麼,在有了多級快取之後,程式的執行就變成了:
當CPU要讀取一個數據時,首先從一級快取中查詢,如果沒有找到再從二級快取中查詢,如果還是沒有就從三級快取或記憶體中查詢。
隨著公司越來越大,老闆要管的事情越來越多,公司的管理部門開始改革,開始出現高層,中層,底層等管理者。一級一級之間逐層管理。
單核CPU只含有一套L1,L2,L3快取;
如果CPU含有多個核心,即多核CPU,則每個核心都含有一套L1(甚至和L2)快取,而共享L3(或者和L2)快取。
公司也分很多種,有些公司只有一個大Boss,他一個人說了算。但是有些公司有比如聯席總經理、合夥人等機制。
單核CPU就像一家公司只有一個老闆,所有命令都來自於他,那麼就只需要一套管理班底就夠了。
多核CPU就像一家公司是由多個合夥人共同創辦的,那麼,就需要給每個合夥人都設立一套供自己直接領導的高層管理人員,多個合夥人共享使用的是公司的底層員工。
還有的公司,不斷壯大,開始差分出各個子公司。各個子公司就是多個CPU了,互相之前沒有共用的資源。互不影響。
下圖為一個單CPU雙核的快取結構。
隨著計算機能力不斷提升,開始支援多執行緒。那麼問題就來了。我們分別來分析下單執行緒、多執行緒在單核CPU、多核CPU中的影響。
單執行緒。cpu核心的快取只被一個執行緒訪問。快取獨佔,不會出現訪問衝突等問題。
單核CPU,多執行緒。程序中的多個執行緒會同時訪問程序中的共享資料,CPU將某塊記憶體載入到快取後,不同執行緒在訪問相同的實體地址的時候,都會對映到相同的快取位置,這樣即使發生執行緒的切換,快取仍然不會失效。但由於任何時刻只能有一個執行緒在執行,因此不會出現快取訪問衝突。
多核CPU,多執行緒。每個核都至少有一個L1 快取。多個執行緒訪問程序中的某個共享記憶體,且這多個執行緒分別在不同的核心上執行,則每個核心都會在各自的caehe中保留一份共享記憶體的緩衝。由於多核是可以並行的,可能會出現多個執行緒同時寫各自的快取的情況,而各自的cache之間的資料就有可能不同。
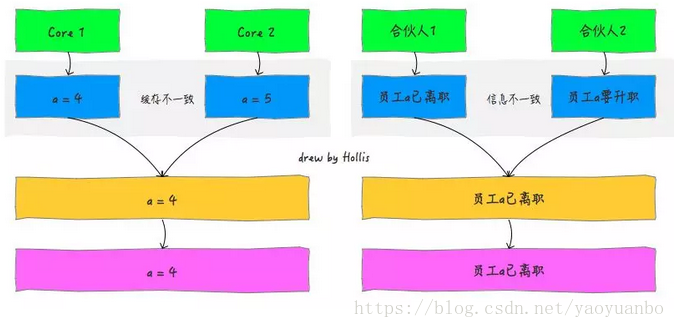
在CPU和主存之間增加快取,在多執行緒場景下就可能存在快取一致性問題,也就是說,在多核CPU中,每個核的自己的快取中,關於同一個資料的快取內容可能不一致。
如果這家公司的命令都是序列下發的話,那麼就沒有任何問題。
如果這家公司的命令都是並行下發的話,並且這些命令都是由同一個CEO下發的,這種機制是也沒有什麼問題。因為他的命令執行者只有一套管理體系。
如果這家公司的命令都是並行下發的話,並且這些命令是由多個合夥人下發的,這就有問題了。因為每個合夥人只會把命令下達給自己直屬的管理人員,而多個管理人員管理的底層員工可能是公用的。
比如,合夥人1要辭退員工a,合夥人2要給員工a升職,升職後的話他再被辭退需要多個合夥人開會決議。兩個合夥人分別把命令下發給了自己的管理人員。合夥人1命令下達後,管理人員a在辭退了員工後,他就知道這個員工被開除了。而合夥人2的管理人員2這時候在沒得到訊息之前,還認為員工a是在職的,他就欣然的接收了合夥人給他的升職a的命令。
處理器優化和指令重排
上面提到在在CPU和主存之間增加快取,在多執行緒場景下會存在快取一致性問題。除了這種情況,還有一種硬體問題也比較重要。那就是為了使處理器內部的運算單元能夠儘量的被充分利用,處理器可能會對輸入程式碼進行亂序執行處理。這就是處理器優化。
除了現在很多流行的處理器會對程式碼進行優化亂序處理,很多程式語言的編譯器也會有類似的優化,比如Java虛擬機器的即時編譯器(JIT)也會做指令重排。
可想而知,如果任由處理器優化和編譯器對指令重排的話,就可能導致各種各樣的問題。
關於員工組織調整的情況,如果允許人事部在接到多個命令後進行隨意拆分亂序執行或者重排的話,那麼對於這個員工以及這家公司的影響是非常大的。
併發程式設計的問題
前面說的和硬體有關的概念你可能聽得有點蒙,還不知道他到底和軟體有啥關係。但是關於併發程式設計的問題你應該有所瞭解,比如原子性問題,可見性問題和有序性問題。
其實,原子性問題,可見性問題和有序性問題。是人們抽象定義出來的。而這個抽象的底層問題就是前面提到的快取一致性問題、處理器優化問題和指令重排問題等。
這裡簡單回顧下這三個問題,並不準備深入展開,感興趣的讀者可以自行學習。我們說,併發程式設計,為了保證資料的安全,需要滿足以下三個特性:
原子性是指在一個操作中就是cpu不可以在中途暫停然後再排程,既不被中斷操作,要不執行完成,要不就不執行。
可見性是指當多個執行緒訪問同一個變數時,一個執行緒修改了這個變數的值,其他執行緒能夠立即看得到修改的值。
有序性即程式執行的順序按照程式碼的先後順序執行。
有沒有發現,快取一致性問題其實就是可見性問題。而處理器優化是可以導致原子性問題的。指令重排即會導致有序性問題。所以,後文將不再提起硬體層面的那些概念,而是直接使用大家熟悉的原子性、可見性和有序性。
什麼是記憶體模型
前面提到的,快取一致性問題、處理器器優化的指令重排問題是硬體的不斷升級導致的。那麼,有沒有什麼機制可以很好的解決上面的這些問題呢?
最簡單直接的做法就是廢除處理器和處理器的優化技術、廢除CPU快取,讓CPU直接和主存互動。但是,這麼做雖然可以保證多執行緒下的併發問題。但是,這就有點因噎廢食了。
所以,為了保證併發程式設計中可以滿足原子性、可見性及有序性。有一個重要的概念,那就是——記憶體模型。
為了保證共享記憶體的正確性(可見性、有序性、原子性),記憶體模型定義了共享記憶體系統中多執行緒程式讀寫操作行為的規範。通過這些規則來規範對記憶體的讀寫操作,從而保證指令執行的正確性。它與處理器有關、與快取有關、與併發有關、與編譯器也有關。他解決了CPU多級快取、處理器優化、指令重排等導致的記憶體訪問問題,保證了併發場景下的一致性、原子性和有序性。
記憶體模型解決併發問題主要採用兩種方式:限制處理器優化和使用記憶體屏障。本文就不深入底層原理來展開介紹了,感興趣的朋友可以自行學習。
什麼是Java記憶體模型
前面介紹過了計算機記憶體模型,這是解決多執行緒場景下併發問題的一個重要規範。那麼具體的實現是如何的呢,不同的程式語言,在實現上可能有所不同。
我們知道,Java程式是需要執行在Java虛擬機器上面的,Java記憶體模型(Java Memory Model ,JMM)就是一種符合記憶體模型規範的,遮蔽了各種硬體和作業系統的訪問差異的,保證了Java程式在各種平臺下對記憶體的訪問都能保證效果一致的機制及規範。
提到Java記憶體模型,一般指的是JDK 5 開始使用的新的記憶體模型,主要由JSR-133: JavaTM Memory Model and Thread Specification 描述。感興趣的可以參看下這份PDF文件(http://www.cs.umd.edu/~pugh/java/memoryModel/jsr133.pdf)
Java記憶體模型規定了所有的變數都儲存在主記憶體中,每條執行緒還有自己的工作記憶體,執行緒的工作記憶體中儲存了該執行緒中是用到的變數的主記憶體副本拷貝,執行緒對變數的所有操作都必須在工作記憶體中進行,而不能直接讀寫主記憶體。不同的執行緒之間也無法直接訪問對方工作記憶體中的變數,執行緒間變數的傳遞均需要自己的工作記憶體和主存之間進行資料同步進行。
而JMM就作用於工作記憶體和主存之間資料同步過程。他規定了如何做資料同步以及什麼時候做資料同步。
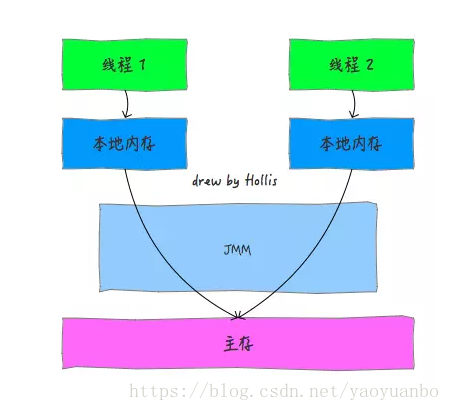
這裡面提到的主記憶體和工作記憶體,讀者可以簡單的類比成計算機記憶體模型中的主存和快取的概念。特別需要注意的是,主記憶體和工作記憶體與JVM記憶體結構中的Java堆、棧、方法區等並不是同一個層次的記憶體劃分,無法直接類比。《深入理解Java虛擬機器》中認為,如果一定要勉強對應起來的話,從變數、主記憶體、工作記憶體的定義來看,主記憶體主要對應於Java堆中的物件例項資料部分。工作記憶體則對應於虛擬機器棧中的部分割槽域。
所以,再來總結下,JMM是一種規範,目的是解決由於多執行緒通過共享記憶體進行通訊時,存在的本地記憶體資料不一致、編譯器會對程式碼指令重排序、處理器會對程式碼亂序執行等帶來的問題。目的是保證併發程式設計場景中的原子性、可見性和有序性。
Java記憶體模型的實現
瞭解Java多執行緒的朋友都知道,在Java中提供了一系列和併發處理相關的關鍵字,比如volatile、synchronized、final、concurren包等。其實這些就是Java記憶體模型封裝了底層的實現後提供給程式設計師使用的一些關鍵字。
在開發多執行緒的程式碼的時候,我們可以直接使用synchronized等關鍵字來控制併發,從來就不需要關心底層的編譯器優化、快取一致性等問題。所以,Java記憶體模型,除了定義了一套規範,還提供了一系列原語,封裝了底層實現後,供開發者直接使用。
本文並不準備把所有的關鍵字逐一介紹其用法,因為關於各個關鍵字的用法,網上有很多資料。讀者可以自行學習。本文還有一個重點要介紹的就是,我們前面提到,併發程式設計要解決原子性、有序性和一致性的問題,我們就再來看下,在Java中,分別使用什麼方式來保證。
原子性
在Java中,為了保證原子性,提供了兩個高階的位元組碼指令monitorenter和monitorexit。在synchronized的實現原理文章中,介紹過,這兩個位元組碼,在Java中對應的關鍵字就是synchronized。
因此,在Java中可以使用synchronized來保證方法和程式碼塊內的操作是原子性的。
可見性
Java記憶體模型是通過在變數修改後將新值同步回主記憶體,在變數讀取前從主記憶體重新整理變數值的這種依賴主記憶體作為傳遞媒介的方式來實現的。
Java中的volatile關鍵字提供了一個功能,那就是被其修飾的變數在被修改後可以立即同步到主記憶體,被其修飾的變數在每次是用之前都從主記憶體重新整理。因此,可以使用volatile來保證多執行緒操作時變數的可見性。
除了volatile,Java中的synchronized和final兩個關鍵字也可以實現可見性。只不過實現方式不同,這裡不再展開了。
有序性
在Java中,可以使用synchronized和volatile來保證多執行緒之間操作的有序性。實現方式有所區別:
volatile關鍵字會禁止指令重排。synchronized關鍵字保證同一時刻只允許一條執行緒操作。
好了,這裡簡單的介紹完了Java併發程式設計中解決原子性、可見性以及有序性可以使用的關鍵字。讀者可能發現了,好像synchronized關鍵字是萬能的,他可以同時滿足以上三種特性,這其實也是很多人濫用synchronized的原因。
但是synchronized是比較影響效能的,雖然編譯器提供了很多鎖優化技術,但是也不建議過度使用。
總結
在讀完本文之後,相信你應該瞭解了什麼是Java記憶體模型、Java記憶體模型的作用以及Java中記憶體模型做了什麼事情等。
關於Java中這些和記憶體模型有關的關鍵字,希望讀者還可以繼續深入學習,並且自己寫幾個例子親自體會一下。可以參考《深入理解Java虛擬機器》和《Java併發程式設計的藝術》兩本書。