
The j.u.c Synchronizer Framework翻譯(三)使用、效能與總結
4 用法
AQS類將上述的功能結合到一起,並且作為一種基於“模版方法模式”[6]的基類提供給同步器。子類只需定義狀態的檢查與更新相關的方法,這些方法控制著acquire和 release操作。然而,將AQS的子類作為同步器ADT並不適合,因為這個類必須提供方法在內部控制acquire和release的規則,這些都不應該被使用者所看到。所有java.util.concurrent包中的同步器類都聲明瞭一個私有的繼承了AbstractQueuedSynchronizer的內部類,並且把所有同步方法都委託給這個內部類。這樣各個同步器類的公開方法就可以使用適合自己的名稱。
下面是一個最簡單的Mutex類的實現,它使用同步狀態0表示解鎖,1表示鎖定。這個類並不需要同步方法中的引數,因此這裡在呼叫的時候使用0作為實參,方法實現裡將其忽略。
class Mutex {
class Sync extends AbstractQueuedSynchronizer {
public boolean tryAcquire(int ignore) {
return compareAndSetState(0, 1);
}
public boolean tryRelease(int ignore) {
setState(0); return true;
}
}
private final Sync sync = new Sync();
public void lock() { sync.acquire(0); }
public void unlock() { sync.release(0); }
}
這個例子的一個更完整的版本,以及其它用法指南,可以在J2SE的文件中找到。還可以有一些變體。如,tryAcquire可以使用一種“test-and-test-and-set”策略,即在改變狀態值前先對狀態進行校驗。
令人詫異的是,像互斥鎖這樣效能敏感的東西也打算通過委託和虛方法結合的方式來定義。然而,這正是現代動態編譯器一直在重點研究的面向物件設計結構。編譯器擅長將這方面的開銷優化掉,起碼會優化頻繁呼叫同步器的那些程式碼。
AbstractQueuedSynchronizer類也提供了一些方法用來協助策略控制。例如,基礎的acquire方法有可超時和可中斷的版本。雖然到目前為止,我們的討論都集中在像鎖這樣的獨佔模式的同步器上,但AbstractQueuedSynchronizer
acquireShared),它們的不同點在於tryAcquireShared和tryReleaseShared方法能夠告知框架(通過它們的返回值)尚能接受更多的請求,最終框架會通過級聯的signal(cascading signals)喚醒多個執行緒。
雖然將同步器序列化(持久化儲存或傳輸)一般來說沒有太大意義,但這些類經常會被用於構造其它類,例如執行緒安全的集合,而這些集合通常是可序列化的。AbstractQueuedSynchronizer和ConditionObject類都提供了方法用於序列化同步狀態,但不會序列化潛在的被阻塞的執行緒,也不會序列化其它內部暫時性的簿記(bookkeeping)變數。即使如此,在反序列化時,大部分同步器類也只僅將同步狀態重置為初始值,這與內建鎖的隱式策略一致 —— 總是反序列化到一個解鎖狀態。這相當於一個空操作,但仍必須顯式地支援以便final欄位能夠反序列化。
4.1 公平排程的控制
儘管同步器是基於FIFO佇列的,但它們並不一定就得是公平的。可以注意到,在基礎的acquire演算法(3.3節)中,tryAcquire是在入隊前被執行的。因此一個新的acquire執行緒能夠“竊取”本該屬於佇列頭部第一個執行緒通過同步器的機會。
可闖入的FIFO策略通常會提供比其它技術更高的總吞吐率。當一個有競爭的鎖已經空閒,而下一個準備獲取鎖的執行緒又正在解除阻塞的過程中,這時就沒有執行緒可以獲取到這個鎖,如果使用闖入策略,則可減少這之間的時間間隔。與此同時,這種策略還可避免過分的,無效率的競爭,這種競爭是由於只允許一個(第一個)排隊的執行緒被喚醒然後嘗試acquire操作導致的。在只要求短時間持有同步器的場景中,建立同步器的開發者可以通過定義tryAcquire在控制權返回之前重複呼叫自己若干次,來進一步凸顯闖入的效果。
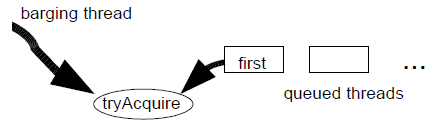
可闖入的FIFO同步器只有概率性的公平屬性。鎖佇列頭部一個解除了阻塞的執行緒擁有一次無偏向的機會(譯者注:即不會偏向隊頭的執行緒也不會偏向闖入的執行緒)來贏得與闖入的執行緒之間的競爭,如果競爭失敗,要麼重新阻塞要麼進行重試。然而,如果闖入的執行緒到達的速度比隊頭的執行緒解除阻塞快,那麼在佇列中的第一個執行緒將很難贏得競爭,以至於幾乎總要重新阻塞,並且它的後繼節點也會一直保持阻塞。對於短暫持有的同步器來說,在佇列中第一個執行緒被解除阻塞期間,多處理器上很可能發生過多次闖入(譯者注:即闖入的執行緒的acquire操作)和release了。正如下文所提到的,最終結果就是保持一或多個執行緒的高進展速度的同時,仍至少在一定概率上避免了飢餓的發生。
當有更高的公平性需求時,實現起來也很簡單。如果需要嚴格的公平性,程式設計師可以把tryAcquire方法定義為,若當前執行緒不是佇列的頭節點(可通過getFirstQueuedThread方法檢查,這是框架提供的為數不多的幾個檢測方法之一),則立即失敗(返回false)。
一個更快,但非嚴格公平的變體可以這樣做,若佇列為空(判斷的瞬間),仍然允許tryAcquire執行成功。在這種情況下,多個執行緒同時遇到一個空佇列時可能會去競爭以使自己第一個獲得鎖,這樣,通常至少有一個執行緒是無需入佇列的。java.util.concurrent包中所有支援公平模式的同步器都採用了這種策略。
儘管公平性設定在實踐中很有用,但是它們並沒有保障,因為Java Language Specification沒有提供這樣的排程保證。例如:即使是嚴格公平的同步器,如果一組執行緒永遠不需要阻塞來達到互相等待,那麼JVM可能會決定純粹以順序方式執行它們。在實際中,單處理器上,在搶佔式上下文切換之前,這樣的執行緒有可能是各自運行了一段時間。如果這樣一個執行緒正持有某個互斥鎖,它將很快會被切換回來,僅是為了釋放其持有的鎖,然後會繼續阻塞,因為它知道有另外一個執行緒需要這把鎖,這更增加了同步器可用但沒有執行緒能來獲取之間的間隔。同步器公平性設定在多處理器上的影響可能會更大,因為在這種環境下會產生更多的交錯,因此一個執行緒就會有更多的機會發現鎖被另一個執行緒請求。
在高競爭下,當保護的是短暫持有鎖的程式碼體時,儘管效能可能會較差,但公平鎖仍然能有效地工作。例如,當公平性鎖保護的是相對長的程式碼體和/或有著相對長的鎖間(inter-lock)間隔,在這種情況下,闖入只能帶來很小的效能優勢,但卻可能會大大增加無限等待的風險。同步器框架將這些工程決策留給使用者來確定。
4.2 同步器
下面是java.util.concurrent包中同步器定義方式的概述:
ReentrantLock類使用AQS同步狀態來儲存鎖(重複)持有的次數。當鎖被一個執行緒獲取時,ReentrantLock也會記錄下當前獲得鎖的執行緒標識,以便檢查是否是重複獲取,以及當錯誤的執行緒(譯者注:如果執行緒不是鎖的持有者,在此執行緒中執行該鎖的unlock操作就是非法的)試圖進行解鎖操作時檢測是否存在非法狀態異常。ReentrantLock也使用了AQS提供的ConditionObject,還向外暴露了其它監控和監測相關的方法。ReentrantLock通過在內部宣告兩個不同的AbstractQueuedSynchronizer實現類(提供公平模式的那個禁用了闖入策略)來實現可選的公平模式,在建立ReentrantLock例項的時候根據設定(譯者注:即ReentrantLock構造方法中的fair引數)使用相應的AbstractQueuedSynchronizer實現類。
ReentrantReadWriteLock類使用AQS同步狀態中的16位來儲存寫鎖持有的次數,剩下的16位用來儲存讀鎖的持有次數。WriteLock的構建方式同ReentrantLock。ReadLock則通過使用acquireShared方法來支援同時允許多個讀執行緒。
Semaphore類(計數訊號量)使用AQS同步狀態來儲存訊號量的當前計數。它裡面定義的acquireShared方法會減少計數,或當計數為非正值時阻塞執行緒;tryRelease方法會增加計數,可能在計數為正值時還要解除執行緒的阻塞。
CountDownLatch類使用AQS同步狀態來表示計數。當該計數為0時,所有的acquire操作(譯者注:acquire操作是從aqs的角度說的,對應到CountDownLatch中就是await方法)才能通過。
FutureTask類使用AQS同步狀態來表示某個非同步計算任務的執行狀態(初始化、執行中、被取消和完成)。設定(譯者注:FutureTask的set方法)或取消(譯者注:FutureTask的cancel方法)一個FutureTask時會呼叫AQS的release操作,等待計算結果的執行緒的阻塞解除是通過AQS的acquire操作實現的。
SynchronousQueues類(一種CSP(Communicating Sequential Processes)形式的傳遞)使用了內部的等待節點,這些節點可以用於協調生產者和消費者。同時,它使用AQS同步狀態來控制當某個消費者消費當前一項時,允許一個生產者繼續生產,反之亦然。
java.util.concurrent包的使用者當然也可以為自定義的應用定義自己的同步器。例如,那些曾考慮到過的,但沒有采納進這個包的同步器包括提供WIN32事件各種風格的語義類,二元訊號量,集中管理的鎖以及基於樹的屏障。
5 效能
雖然AQS框架除了支援互斥鎖外,還支援其它形式的同步方式,但鎖的效能是最容易測量和比較的。即使如此,也還存在許多不同的測量方式。這裡的實驗主要是設計來展示鎖的開銷和吞吐量。
在每個測試中,所有執行緒都重複的更新一個偽隨機數,該隨機數由nextRandom(int seed)方法計算:
int t = (seed % 127773) * 16807 - (seed / 127773) * 2836; return (t > 0) ? t : t + 0x7fffffff;
在每次迭代中,執行緒以概率S在一個互斥鎖下更新共享的生成器,否則(譯者注:概率為1-S)更新其自己區域性的生成器,此時是不需要鎖的。如此,鎖佔用區域的耗時是短暫的,這就使執行緒持有鎖期間被搶佔時的外界干擾降到了最小。這個函式的隨機性主要是為了兩個目的:確定是否需要使用鎖(這個生成器足以應付這裡的需求),以及使迴圈中的程式碼不可能被輕易地優化掉。
這裡比較了四種鎖:內建鎖,用的是synchronized塊;互斥鎖,用的是像第四節例子中的那樣簡單的Mutex類;可重入鎖,用的是ReentrantLock;以及公平鎖,用的是ReentrantLock的公平模式。所有測試都執行在J2SE1.5 JDK build46(大致與beta2相同)的server模式下。在收集測試資料前,測試程式先執行20次非競爭的測試,以排除JVM“預熱”()過程的影響。除了公平模式下的測試只跑了一百萬次迭代,其它每個執行緒中的測試都運行了一千萬次迭代。
該測試執行在四個X86機器和四個UltraSparc機器上。所有X86機器都執行的是RedHat基於NPTL 2.4核心和庫的Linux系統。所有的UltraSparc機器都執行的是Solaris-9。測試時所有系統的負載都很輕。根據該測試的特徵,並不要求系統完全空閒(譯者注:即測試時作業系統上有其它較輕的負載也不會影響本次測試的結果。)。“4P”這個名字反映出雙核超執行緒的Xeon更像是4路機器,而不是2路機器。這裡沒有將測試資料規範化。如下所示,同步的相對開銷與處理器的數量、型別、速度之間不具備簡單的關係。
表1 測試的平臺
| 名字 | 處理器數量 | 型別 | 速度(Mhz) |
|---|---|---|---|
| 1P | 1 | Pentium3 | 900 |
| 2P | 2 | Pentium3 | 1400 |
| 2A | 2 | Athlon | 2000 |
| 4P | 2HT | Pentium4/Xeon | 2400 |
| 1U | 1 | UltraSparc2 | 650 |
| 4U | 4 | UltraSparc2 | 450 |
| 8U | 8 | UltraSparc3 | 750 |
| 24U | 24 | UltraSparc3 | 750 |
5.1 開銷
無競爭情況下的開銷是通過僅執行一個執行緒,將概率S為1時的每次迭代時間減去概率S為0(訪問共享記憶體的概率為0)時的每次迭代時間得到的(譯者注:這裡的“概率S”即前文提到的“概率S”,概率為0時是沒有鎖操作的,概率為1時是每次都有鎖操作,因此將概率為1時的耗時減去概率為0時的耗時就是整個鎖操作的開銷。)。表2以納秒為單位顯示了非競爭場景下每次鎖操作的開銷。Mutex類最接近於框架的基本耗時,可重入鎖的額外開銷是記錄當前所有者執行緒和錯誤檢查的耗時,對於公平鎖來說還包含開始時檢查佇列是否為空的耗時。
表格2也展示與內建鎖的“快速路徑(fast path)”對比,tryAcquire的耗時。這裡的差異主要反映出了各鎖和機器中使用的不同的原子指令以及記憶體屏障的耗時。在多處理器上,這些指令常常是完全優於所有其它指令的。內建鎖和同步器類之間的主要差別,顯然是由於Hotspot鎖在鎖定和解鎖時都使用了一次compareAndSet,而同步器的acquire操作使用了一次compareAndSet,但release操作用的是一次volatile寫(即,多處理器上的一次記憶體屏障以及所有處理器上的重排序限制)。每個鎖的絕對的和相對耗時因機器的不同而不同。
表2 無競爭時的單鎖開銷(單位:納秒)
| 機器 | 內建 | 互斥 | 可重入 | 公平可重入 |
|---|---|---|---|---|
| 1P | 18 | 9 | 31 | 37 |
| 2P | 58 | 71 | 77 | 81 |
| 2A | 13 | 21 | 31 | 30 |
| 4P | 116 | 95 | 109 | 117 |
| 1U | 90 | 40 | 58 | 67 |
| 4U | 122 | 82 | 100 | 115 |
| 8U | 160 | 83 | 103 | 123 |
| 24U | 161 | 84 | 108 | 119 |
從另一個極端看,表3展示了概率S為1,執行256個併發執行緒時產生了大規模的鎖競爭下每個鎖的開銷。在完全飽和的情況下,可闖入的FIFO鎖比內建鎖的開銷少了一個數量級(也就是更大的吞吐量),比公平鎖更是少了兩個數量級。這表現出即使有著極大的競爭,在維持執行緒進展方面可闖入FIFO策略的效率。
表3也說明了即使在內部開銷比較低的情況下,公平鎖的效能也完全是由上下文切換的時間所決定的。列出的時間大致上都與各平臺上執行緒阻塞和解除執行緒阻塞的時間相稱。
此外,後面增加的一個實驗(僅使用機器4P)表明,對於這裡用到的短暫持有的鎖,公平引數的設定在總差異中的影響很小。這裡將執行緒終止時間間的差異記錄成一個粗粒度的離散量數。在4P的機器上,公平鎖的時間度量的標準差平均為0.7%,可重入鎖平均為6.0%。作為對比,為模擬一個長時間持有鎖的場景,測試中使每個執行緒在持有鎖的情況下計算了16K次隨機數。這時,總執行時間幾乎是相同的(公平鎖:9.79s,可重入鎖:9.72s)。公平模式下的差異依然很小,標準差平均為0.1%,而可重入鎖上升到了平均29.5%。
表格3 飽和時的單鎖開銷(單位:納秒)
| 機器 | 內建 | 互斥 | 可重入 | 公平可重入 |
|---|---|---|---|---|
| 1P | 521 | 46 | 67 | 8327 |
| 2P | 930 | 108 | 132 | 14967 |
| 2A | 748 | 79 | 84 | 33910 |
| 4P | 1146 | 188 | 247 | 15328 |
| 1U | 879 | 153 | 177 | 41394 |
| 4U | 2590 | 347 | 368 | 30004 |
| 8U | 1274 | 157 | 174 | 31084 |
| 24U | 1983 | 160 | 182 | 32291 |
5.2 吞吐量
大部分同步器都是用於無競爭和極大競爭之間的。這可以用實驗在兩個方面進行檢查,通過修改固定個執行緒的競爭概率,和/或通過往擁有固定競爭概率的執行緒集合裡增加更多的執行緒。為了說明這些影響,測試執行在不同的競爭概率和不同的執行緒數目下,都用的是可重入鎖。附圖使用了一個slowdown度量標準。
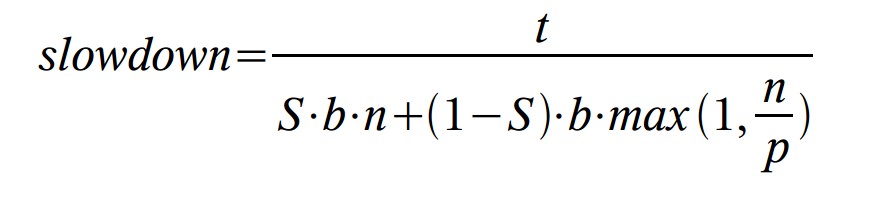
這裡,t是總執行時間,b是一個執行緒在沒有競爭或同步下的基線時間,n是執行緒數,p是處理器數,S是共享訪問的比例(譯者注:即前面的競爭概率S)。計算結果是實際執行時間與理想執行時間(通常是無法得到的)的比率,理想執行時間是通過使用Amdahl’s法則計算出來的。理想時間模擬了一次沒有同步開銷,沒有因鎖爭用而導致執行緒阻塞的執行過程。即使這樣,在很低的競爭下,相比理想時間,有一些測試結果卻表現出了很小的速度增長,大概是由於基線和測試之間的優化、流水線等方面有著輕微的差別。
圖中用以2為底的對數為比例進行了縮放。例如,值為1表示實際時間是理想時間的兩倍,4表示慢16倍。使用對數就不需要依賴一個隨意的基線時間(這裡指的是計算隨機數的時間),因此,基於不同底數計算的結果表現出的趨勢應該是類似的。這些測試使用的競爭概率從1/128(標識為“0.008”)到1,以2的冪為步長,執行緒的數量從1到1024,以2的冪的一半為步長。
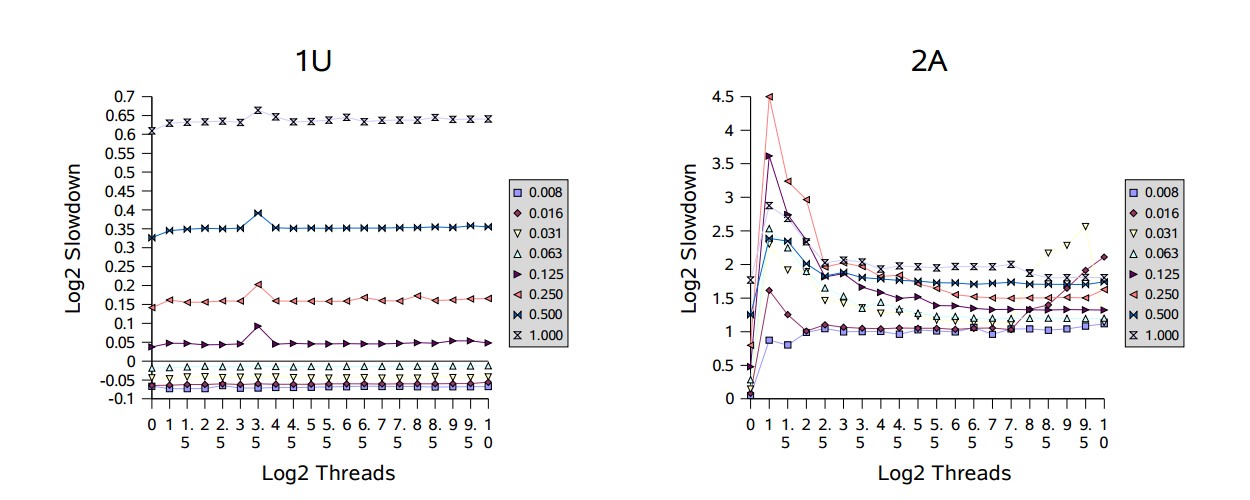
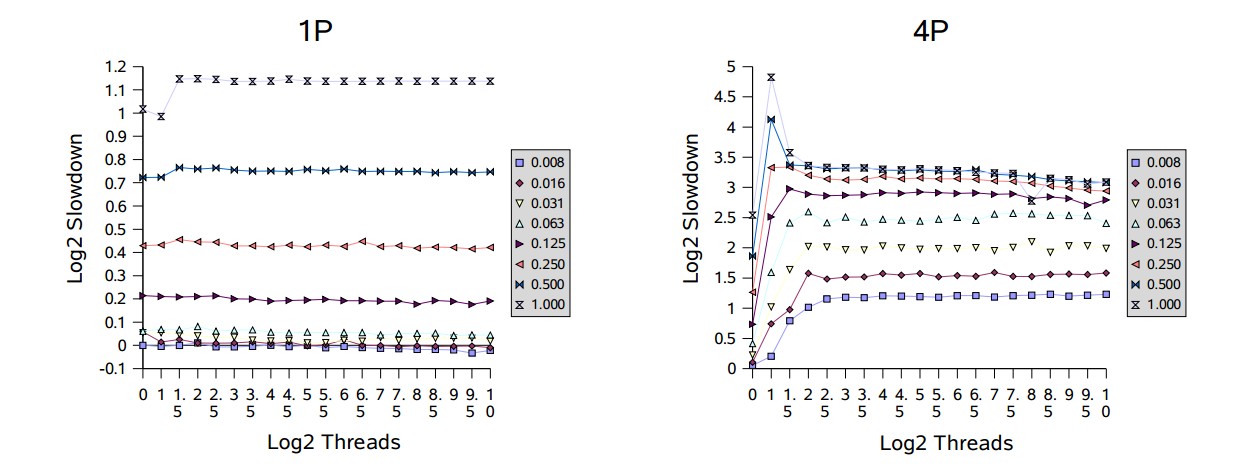
在單處理器(1P和1U)上,效能隨著競爭的上升而下降,但不會隨著執行緒數的增加而下降。多處理器在遭遇競爭時,效能下降的更快。根據多處理器相關的圖表顯示,開始出現的峰值處雖然只有幾個執行緒的競爭,但相對效能通常卻最差。這反映出了一個性能的過渡區域,在這裡闖入的執行緒和被喚醒的執行緒都準備獲取鎖,這會讓它們頻繁的迫使對方阻塞。在大部分時候,過渡區域後面會緊接著一個平滑區域,因為此時幾乎沒有空閒的鎖,所以會與單處理器上順序執行的模式差不多;在多處理器機器上會較早進入平滑區域。例如,請注意,在滿競爭(標識為“1.000”)下這些值表示,在處理器越少的機器上,會有更糟糕的相對速度下降。
根據這些結果,可以針對阻塞(park/unpark)做進一步調優以減少上下文切換和相關的開銷,這會給本框架帶來小但顯著的提升。此外,在多處理器上為短時間持有的但高競爭的鎖採用某種形式的適應性自旋,可以避免這裡看到的一些波動,這對同步器類大有裨益。雖然在跨不同上下文時適應性自旋很難很好的工作,但可以使用本框架為遇到這類使用配置的特定應用構建一個自定義形式的鎖。


6 總結
本文撰寫之時,java.util.concurrent包中的同步器框架還太新所以還不能在實踐中使用。因此在J2SE 1.5最終版本釋出之前都很難看到其大範圍的使用,並且,它的設計,API實現以及效能肯定還有無法預料的後果。但是,此時,這個框架明顯能勝任其基本的目標,即為建立新的同步器提供一個高效的基礎。
7 致謝
Thanks to Dave Dice for countless ideas and advice during the development of this framework, to Mark Moir and Michael Scott for urging consideration of CLH queues, to David Holmes for critiquing early versions of the code and API, to Victor Luchangco and Bill Scherer for reviewing previous incarnations of the source code, and to the other members of the JSR166 Expert Group (Joe Bowbeer, Josh Bloch, Brian Goetz, David Holmes, and Tim Peierls) as well as Bill Pugh, for helping with design and specifications and commenting on drafts of this paper. Portions of this work were made possible by a DARPA PCES grant, NSF grant EIA-0080206 (for access to the 24way Sparc) and a Sun Collaborative Research Grant.
參考文獻
- [1] Agesen, O., D. Detlefs, A. Garthwaite, R. Knippel, Y. S.Ramakrishna, and D. White. An Efficient Meta-lock for Implementing Ubiquitous Synchronization. ACM OOPSLA Proceedings, 1999.
- [2] Andrews, G. Concurrent Programming. Wiley, 1991.
- [3] Bacon, D. Thin Locks: Featherweight Synchronization for Java. ACM PLDI Proceedings, 1998.
- [4] Buhr, P. M. Fortier, and M. Coffin. Monitor Classification,ACM Computing Surveys, March 1995.
- [5] Craig, T. S. Building FIFO and priority-queueing spin locks from atomic swap. Technical Report TR 93-02-02,Department of Computer Science, University of Washington, Feb. 1993.
- [6] Gamma, E., R. Helm, R. Johnson, and J. Vlissides. Design Patterns, Addison Wesley, 1996.
- [7] Holmes, D. Synchronisation Rings, PhD Thesis, Macquarie University, 1999.
- [8] Magnussen, P., A. Landin, and E. Hagersten. Queue locks on cache coherent multiprocessors. 8th Intl. Parallel Processing Symposium, Cancun, Mexico, Apr. 1994.
- [9] Mellor-Crummey, J.M., and M. L. Scott. Algorithms for Scalable Synchronization on Shared-Memory Multiprocessors. ACM Trans. on Computer Systems,February 1991
- [10] M. L. Scott and W N. Scherer III. Scalable Queue-Based Spin Locks with Timeout. 8th ACM Symp. on Principles and Practice of Parallel Programming, Snowbird, UT, June 2001.
- [11] Sun Microsystems. Multithreading in the Solaris Operating Environment. White paper available at http://wwws.sun.com/software/solaris/whitepapers.html 2002.
- [12] Zhang, H., S. Liang, and L. Bak. Monitor Conversion in a Multithreaded Computer System. United States Patent 6,691,304. 2004.
