
k-medoid(k中心點)聚類演算法Python實現
k-means演算法有個很大的缺點,就是對孤立點敏感性太高,孤立點即是脫離群眾的點,與眾不同的點,即在顯示中與其他點不是抱在一團的點。
為了體現兩者的不同,我特意溫習了一下知識,在構造初始點的時候,自己定義加入了幾個孤立點,使用k-means演算法跑的效果如下:
一開始的所有點:(可以看出其他點是混在一起有許多分類的)

使用k-means演算法執行,定義3箇中心點:

可以看到,此時的確是被分成了三類,只不過兩個孤立點算在了一類
那麼試一下k中心點演算法,初始:
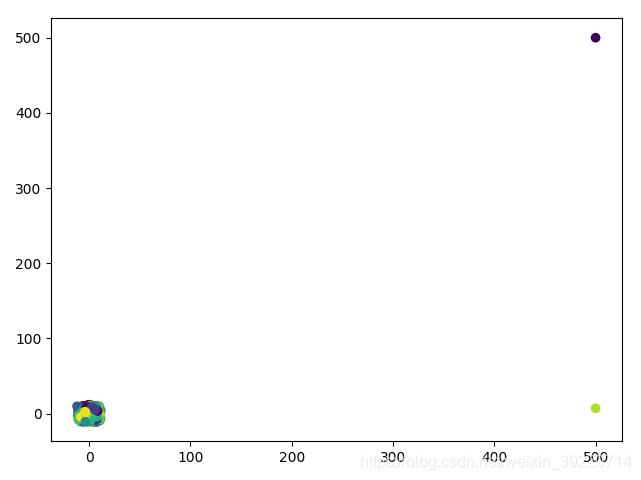
運算之後:

就這麼簡單,就驗證了k中心點演算法的優越之處
1.演算法理論
1.1 聚類
將物理或抽象物件的集合分成由類似的物件組成的多個類的過程被稱為聚類。由聚類所生成的簇是一組資料物件的集合,這些物件與同一個簇中的物件彼此相似,與其他簇中的物件相異。
簡單的說,就是對於一組不知道分類標籤的資料,可以通過聚類演算法自動的把相似的資料劃分到同一個分類中。即聚類與分類的區別主要在於,聚類可以不必知道源資料的標籤資訊。
1.2 演算法描述
在K-means演算法執行過程中,可以通過隨機的方式選擇初始質心,也只有初始時通過隨機方式產生的質心才是實際需要聚簇集合的中心點,而後面通過不斷迭代產生的新的質心很可能並不是在聚簇中的點。如果某些異常點距離質心相對較大時,很可能導致重新計算得到的質心偏離了聚簇的真實中心。
借用百度百科的演算法步驟:
(1)隨機選擇k個代表物件作為初始的中心點
(2)指派每個剩餘物件給離它最近的中心點所代表的簇
(3)隨機地選擇一個非中心點物件y
(4)計算用y代替中心點x的總代價s
(5)如果s為負,則用可用y代替x,形成新的中心點
(6) 重複(2)(3)(4)(5),直到k箇中心點不再發生變化.
在網上看到一個例子,感覺過程還是挺清晰的。
2.程式碼運算例項
我在報告一開始已經將兩種演算法對比了一下效果,這裡就再試一下,不存在孤立點時候的k中心點演算法的表現:
依然是一個類,只要傳入初始點的個數要定義的中心點個數,便可以畫出一開始雜亂無序的圖和經過k中心點演算法訓練後的圖。首先看一下一開始的圖,我定義了一千個點:

可以看出的確是十分雜亂,接下來看看執行演算法後的效果:

不存在孤立點的情況,分出的效果與k-means演算法還是大致差不多,如下為k-means執行的效果:

都是差不多的三等分。
3.演算法學習心得
這次的實驗還是比較簡單的,在k-means演算法的基礎上,修改核心的中心點的劃分部分即可。
還是那句話,python作為一個工具,實在是太方便了。
附錄:python程式碼
# -*- coding: utf-8 -*-
# @Time : 18-12-6
# @Author : lin
from sklearn.datasets import make_blobs
from matplotlib import pyplot
import numpy as np
import random
class KMeans():
"""
實現簡單的k-means演算法
"""
def __init__(self, n_points, k_num_center):
self.n_points = n_points
self.k_num_center = k_num_center
self.data = None
def get_test_data(self):
"""
產生測試資料, n_samples表示多少個點, n_features表示幾維, centers
得到的data是n個點各自座標
target是每個座標的分類比如說我規定好四個分類,target長度為n範圍為0-3,主要是畫圖顏色區別
:return: none
"""
self.data, target = make_blobs(n_samples=self.n_points, n_features=2, centers=self.n_points)
np.put(self.data, [self.n_points, 0], 500, mode='clip')
np.put(self.data, [self.n_points, 1], 500, mode='clip')
pyplot.scatter(self.data[:, 0], self.data[:, 1], c=target)
# 畫圖
pyplot.show()
def ou_distance(self, x, y):
# 定義歐式距離的計算
return np.sqrt(sum(np.square(x - y)))
def run_k_center(self, func_of_dis):
"""
選定好距離公式開始進行訓練
:param func_of_dis:
:return:
"""
print('初始化', self.k_num_center, '箇中心點')
indexs = list(range(len(self.data)))
random.shuffle(indexs) # 隨機選擇質心
init_centroids_index = indexs[:self.k_num_center]
centroids = self.data[init_centroids_index, :] # 初始中心點
# 確定種類編號
levels = list(range(self.k_num_center))
print('開始迭代')
sample_target = []
if_stop = False
while(not if_stop):
if_stop = True
classify_points = [[centroid] for centroid in centroids]
sample_target = []
# 遍歷資料
for sample in self.data:
# 計算距離,由距離該資料最近的核心,確定該點所屬類別
distances = [func_of_dis(sample, centroid) for centroid in centroids]
cur_level = np.argmin(distances)
sample_target.append(cur_level)
# 統計,方便迭代完成後重新計算中間點
classify_points[cur_level].append(sample)
# 重新劃分質心
for i in range(self.k_num_center): # 幾類中分別尋找一個最優點
distances = [func_of_dis(point_1, centroids[i]) for point_1 in classify_points[i]]
now_distances = sum(distances) # 首先計算出現在中心點和其他所有點的距離總和
for point in classify_points[i]:
distances = [func_of_dis(point_1, point) for point_1 in classify_points[i]]
new_distance = sum(distances)
# 計算出該聚簇中各個點與其他所有點的總和,若是有小於當前中心點的距離總和的,中心點去掉
if new_distance < now_distances:
now_distances = new_distance
centroids[i] = point # 換成該點
if_stop = False
print('結束')
return sample_target
def run(self):
"""
先獲得資料,由傳入引數得到雜亂的n個點,然後由這n個點,分為m個類
:return:
"""
self.get_test_data()
predict = self.run_k_center(self.ou_distance)
pyplot.scatter(self.data[:, 0], self.data[:, 1], c=predict)
pyplot.show()
test_one = KMeans(n_points=1000, k_num_center=3)
test_one.run()