
java用多執行緒批次查詢大量資料(Callable返回資料)方式
阿新 • • 發佈:2018-12-24
我看到有的資料庫是一萬條資料和八萬條資料還有十幾萬條,幾百萬的資料,然後我就想拿這些資料測試一下,發現如果用java和資料庫查詢就連一萬多條的資料查詢出來就要10s左右,感覺太慢了。然後網上都說各種加索引,加索引貌似是有查詢條件時在某個欄位加索引比較快一些,但是畢竟是人家的庫不能瞎動,再者說了,資料量偏大一點的,條件加上也還有好多資料怎麼辦,我想到了多執行緒的方式,話不多說,開始弄
多執行緒有好幾種方式,今天說的方式比較好,實現Callable<> 這種方式能返回查詢的資料,加上Future非同步獲取方式,查詢效率大大加快
執行緒類:
package com.ThreadPoolHadel; import com.sqlSource.SqlHadle; import java.util.List; import java.util.concurrent.Callable; /** * Created by df on 2018/9/20. */ public class ThredQuery implements Callable<List> { SqlHadle sqlHadle=new SqlHadle(); private String search;//查詢條件 根據條件來定義該類的屬性 private int bindex;//當前頁數 private int num;//每頁查詢多少條 private String table;//要查詢的表名,也可以寫死,也可以從前面傳 private List page;//每次分頁查出來的資料 public ThredQuery(int bindex,int num,String table) { this.bindex=bindex; this.num=num; this.table=table; //分頁查詢資料庫資料 page=sqlHadle.queryTest11(bindex,num,table); } @Override public List call() throws Exception { //返回資料給Future return page; } }
呼叫類:package com.service; import com.ThreadPoolHadel.ThredQuery; import com.sqlSource.SqlHadle; import org.springframework.stereotype.Service; import java.util.ArrayList; import java.util.List; import java.util.concurrent.*; /** * Created by df on 2018/9/20. */ @Service public class TheardQueryService { SqlHadle sqlHadle=new SqlHadle(); public List<List> getMaxResult(String table) throws InterruptedException, ExecutionException { long start = System.currentTimeMillis();//開始時間 List<List> result = new ArrayList<>();//返回結果 //查詢資料庫總數量 int count = sqlHadle.count(table); int num = 8000;//一次查詢多少條 //需要查詢的次數 int times = count / num; if (count % num != 0) { times = times + 1; } //開始頁數 連線的是orcle的資料庫 封裝的分頁方式 我的是從1開始 int bindex = 1; //Callable用於產生結果 List<Callable<List>> tasks = new ArrayList<>(); for (int i = 0; i < times; i++) { Callable<List> qfe = new ThredQuery(bindex, num, table); tasks.add(qfe); bindex += bindex; } //定義固定長度的執行緒池 防止執行緒過多 ExecutorService executorService = Executors.newFixedThreadPool(15); //Future用於獲取結果 List<Future<List>> futures=executorService.invokeAll(tasks); //處理執行緒返回結果 if(futures!=null&&futures.size()>0){ for (Future<List> future:futures){ result.addAll(future.get()); } } executorService.shutdown();//關閉執行緒池 long end = System.currentTimeMillis(); System.out.println("執行緒查詢資料用時:"+(end-start)+"ms"); return result; } }
19600多條資料3秒內查詢完,對於之前10m查詢完畢,已經提高很多的效率了
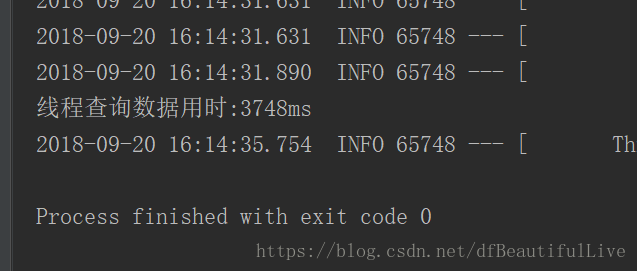
80000多條資料7m就完成了
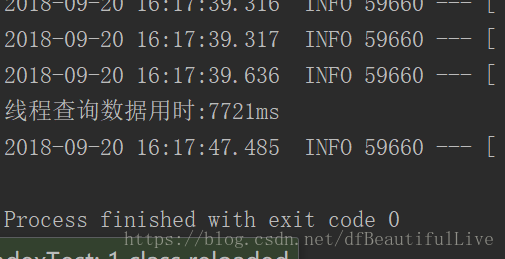
830305萬的資料需要40m ,哈哈哈,也算差不多一百萬的資料了,最主要的是沒有卡死,好像不經過處理很容易卡死
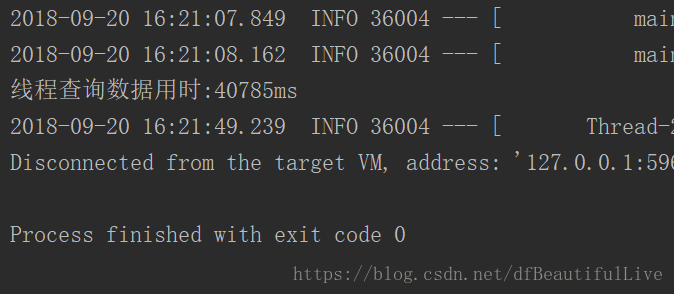
5184121萬的資料報GC了,那就演示到這吧,五百萬的資料實在不適合這樣查
最主要的是,你的資料量大的話要相應的更改呼叫方法裡的 num,一次性多查點,效率會高很多