
centos6.9安裝Hadoop2.7.6
1.官網下載Hadoop2.7.6
2.遠端登入到centos傳送Hadoop安裝檔案。(目錄自己決定,本文以放到/home目錄下來講解//不推薦!!所以我換到了/usr/local/hadoop/下)
3.解壓
tar -xzvf hadoop-2.7.6.tar.gz (解壓後為配置方便,修改了Hadoop-2.7.6資料夾名稱為hadoop)
4.進入hadoop資料夾
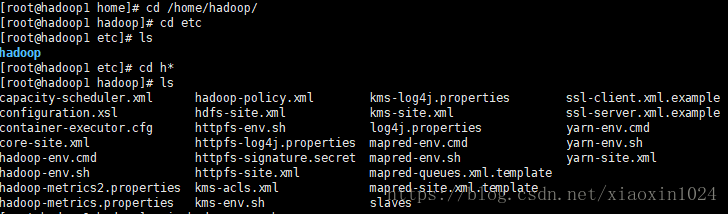
5.修改hadoop環境變數
修改JAVA_HOME的位置(就是裝jdk配置的那個)例如:export JAVA_HOME=/home/java/jdk1.8.0_142
6.把hadoop執行命令的路徑加到PATH環境變數裡面
vim /etc/profile

在最後一行加入 export PATH=$PATH:/home/hadoop/bin://home/hadoop/sbin
(根據hadoop的安裝目錄而定)
----------------------------------------------------------------------------------------------------------------------------------------------------------------------->注意,上面的操作.目錄是在/home目錄下安裝的,9/23更新為/usr/local資料夾下
7.執行profile檔案
source /etc/profile
8.進入hadoop資料夾
cd /usr/local/hadoop/etc/hadoop
修改環境變數: vi hadoop-env.sh ---->修改JAVA-HOME 為/usr/local/java/jdk1.8.0_171
修改core-site.xml
vi /usr/local/hadoop/etc/hadoop/core-site.xml
改成以下內容:
<configuration>
<!-- 指定hdfs的nameservice為ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- Size of read/write buffer used in SequenceFiles. -->
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!-- 指定hadoop臨時目錄,自行建立 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/var/hadoop/tmp</value>
</property>
</configuration>
9.修改hdfs-site.xml vi /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<!--指定hdfs儲存資料的副本數量-->
<property>
<name>dfs.replication</name>
<value>3</value>
<description>副本個數,配置預設是3,應小於datanode機器數量</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/var/hadoop/dfs/name</value>
<description>namenode上儲存hdfs名字空間元資料 </description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/var/hadoop/dfs/data</value>
<description>datanode上資料塊的物理儲存位置</description>
</property>
</configuration>
10.修改mapred-site.xml (可能是.tmp之類的字尾,拷貝一份在改)cd /usr/local/hadoop/etc/hadoop/
<configuration>
<!--告訴hadoop以後MR執行在YARN上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
11.修改vi yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce.shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
12.修改slaves
vi /usr/local/hadoop/etc/hadoop/slaves
刪除localhost 新增節點主機名稱
14.scp命令拷貝過去或者重新克隆 (記得該ip hostname ssh)
格式化namenode hadoop namenode -format
格式化後報錯cd /var/hadoop/dfs/data/current/ 修改VERSON裡的clusterid 全改了不要慌,刪了重啟節點就會自動生成
15.單一節點啟動
hadoop-daemon.sh start datanode hadoop-daemon.sh start namenode
end.驗證
輸入hadoop,有提示資訊則成功。
start-all.sh
start-yarn.sh
jps檢視