
【面試題之演算法部分】二叉樹的遍歷
本篇文章主要目的是詳細討論二叉樹的前序、中序和後序遍歷演算法,包括遞迴版和迭代版。首先給出遞迴版的一般思想:
- 前序遍歷:先訪問根節點,前序遍歷左子樹,前序遍歷右子樹。
- 中序遍歷:中序遍歷左子樹,訪問根節點,中序遍歷右子樹。
- 後序遍歷:後序遍歷左子樹,後序遍歷右子樹,訪問根結點。
我們首先定義節點的結構
typedef struct node{
int val;
node *lChild;
node *rChild;
}BiTree;一. 前序遍歷
遞迴版本:
void PreOrder(BiTree* T)
{
if(!T) return 遞迴版本的時間複雜度為O(n),但是由於空間複雜度的常係數較迭代版本更高,我們可以改用等效迭代版本。
迭代版本1:
#define HasRChild(x) ((x).rChild)
#define HasLChild(x) ((x).lChild) 迭代版本2:
我們先沿最左側通路自頂向下訪問訪問沿途節點,再自底而上一次遍歷這些節點的右子樹。其實遍歷過程和迭代版本1大同小異。
void visitAlongLeftBranch(BiTree *x, stack<BiTree *> &s)
{
while(x)
{
visit(x);
if(x->rChild) s.push(x->rChild);
x = x->lChild;
}
}
void PreOrder(BiTree *x)
{
stack<BiTree *> s;
while(true)
{
visitAlongLeftBranch(x, s);
if(s.empty()) break;
x = s.top();
s.pop();
}
}二. 中序遍歷
注意二叉查詢樹的中序遍歷是資料的升序過程。
遞迴版本:
void InOrder(BiTree *T)
{
if(!T) return;
Inorder(T->lChild);
visit(T);
InOrder(T->rChild);
}將中序遍歷遞迴版本改成迭代版本的難度在於:儘管右子樹的遞迴是屬於嚴格尾遞迴的,但是右子樹的遞歸併不是,我們可以參看前序遍歷迭代版本2的思想。
迭代版本1:
void visitAlongLeftBranch(BiTree *x, stack<BiTree *> s)
{
while(x)
{
s.push(x);
x = x->lChild;
}
}
void InOrder(BiTree *x)
{
stack<BiTree *> s;
while(true)
{
visitLongLeftBranch(x, s); //不斷將左側節點入棧
if(s.empty()) break;
x = s.top();
s.pop();
visit(x); //自底向上訪問左側節點
x = x->rChild; //進入右子樹
}
}進一步優化,可將上面的兩個while迴圈改成一個迴圈
迭代版本2
void InOrder(Bitree *x)
{
stack<Bitree *> s;
while(true)
{
if(x)
{
s.push(x);
x = x->lChild;
}
else
{
if(!empty())
{
x = s.top();
s.pop();
visit(x);
x = x->rChild;
}
else break;
}
}
}以上版本都需要輔助棧,儘管時間複雜度沒有什麼實質影響,但所需的空間複雜度正比於二叉樹的高度,最壞情況下將達到O(n)(退化成單鏈)。為此,我們繼續優化,如果node節點內有parent指標,我們藉助parent指標來實現。基於一個事實:中序遍歷中前後元素關係滿足呼叫succ()函式(尋找其直接後繼的函式)前後兩元素的關係。
簡單來講,假設我現在遍歷到節點A,按中序遍歷下一個節點是B。那同樣,我對A呼叫succ()後返回的節點一定也是B。
void Inorder(BiTree *x)
{
bool backtrace = false;
while(true)
{
if(!backtrace && x->lchild) x = x->lChild;
else
{
visit(x);
if(x->rChild)
{
x = x->rChild;
backtrace = false;
}
else
{
if(!(x = succ(x))) break;
backtrace = true;
}
}
}
}
//直接後繼函式
BiTree* succ(BiTree* x)
{
if(x->rChild) //如果存在右子樹,則直接後繼是右子樹中的最左子孫
{
x = x->rChild->lChild;
while(x) x = x->lChild;
}
else //如果不存在右子樹,則直接後繼是“包含x節點於左子樹中的最低祖先”
{
while(x == x->parent->rChild) x = x->parent;
x = x->parent;
}
}三. 後序遍歷
遞迴版本:
void PostOrder(Bitree *T)
{
if(!T) return;
PostOrder(T->lChild);
PostOrder(T->rChild);
visit(T);
}迭代版本:
在後序遍歷演算法的遞迴版中,由於左、右子樹遞迴遍歷均嚴格的不屬於尾遞迴,因此實現對應的迭代式演算法難度更大,不過,仍可套用之前的思路。
我們思考的起點依然是,此時首先訪問哪個節點?如下圖所示,從左側水平向右看去,未被遮擋的最高葉節點v——稱作最高左側可見節點(HLVFL)——即為後序遍歷首先訪問的節點。注意,該節點有可能是左孩子,也有可能是右孩子。故圖中以垂直邊示意它與其父節點的聯邊。
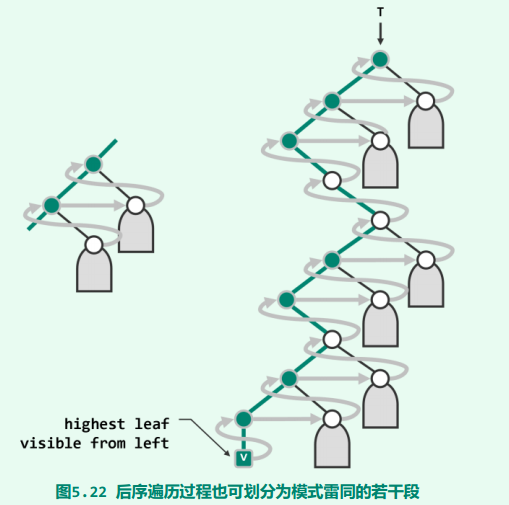
考察連線於v與樹根之間的唯一通路(粗線所示),與先序和中序遍歷類似,自底而上沿著該通路,整個後序遍歷也可以分解為若干個片段。每個片段,分別起始於通路的一個節點,幷包括三步: 訪問當前節點;遍歷其右兄弟(若存在)為根的子樹;以及向上回溯至父節點(若存在)並轉入下一片段。
基於以上理解,匯出迭代式後序遍歷演算法:
void gotoHLVFL(stack<BiTree *> &s) //以s棧節點為根的子樹中,尋找最高左側可見節點(HLVFL)
{
while(BiTree *x = s.top()) //自頂向下,反覆檢查當前節點(即棧頂)
{
if(HasLChild(*x)) //儘可能向左
{
if(HasRChild(*x)) s.push(x->rChild); //若有右孩子,優先入棧
s.push(x->lChild); //然後才轉至左孩子
}
else s.push(x->rChild); //實不得已才向右
}
s.pop(); //返回前彈出在棧頂的空節點
}
PostOrder(Bitree *x)
{
stack<Bitree *> s;
if(x) s.push(x);
while(!s.empty())
{
//如果棧頂元素非當前元素之父,則必為當前元素的右兄弟,所以需要遞迴以右兄弟為根的樹,繼續尋找最高左側可見節點(HLVFL)
if(s.top() != x->parent) gotoHLVFL(s);
x = s.top();
s.pop();
visit(x);
}
}參考文獻:
《資料結構c++語言版》,鄧俊輝