
關於索引的B tree B-tree B+tree B*tree 詳解結構圖( 二)
索引,是為了更快的查詢資料,查詢演算法有很多,對應的資料結構也不少,資料庫常用的索引資料結構一般為B+Tree。
1、B-Tree
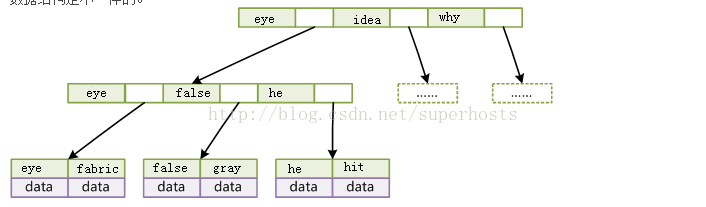
關於B-Tree的官方定義個人覺得比較難懂,通俗一點就是舉個例子。假如:一本英文字典,單詞+詳細解釋組成了一條記錄,現在需要索引單詞,那麼以單詞為key,單詞+詳細解釋為data,B-Tree就是以一個二元組{key,data}來定義一條記錄。如果一個節點有3條記錄,那麼會有對應的4個指標,用以指向下一個節點。B-Tree是有序且平衡的,所有葉子節點在同一層,即不會出現某個分支層級多,某個分支層級少的情況。

因為B-Tree是有序的,所以它的查詢就簡單了,先從根節點開始二分查詢,找到則返回節點;否則沿著區間指標查詢下一個節點。比如,查詢false這個單詞。
2、B+Tree
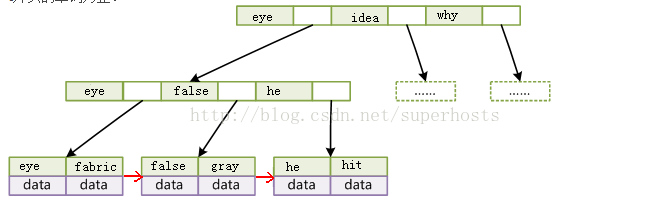
與B-Tree不同的是,B+Tree每個節點只有key,沒有data;而且葉子節點沒有指標。也就是說B+Tree的葉子節點和內節點的資料結構是不一樣的。
一般資料庫採用的是B+Tree,而且經過了一些優化,比如在葉子節點上增加了順序訪問指標,提高區間查詢效率。比如:查詢首字母為f~t的所有單詞。那麼只需查到f開頭的第一個單詞fabric,然後沿著葉子節點的開始遍歷,直到找到最後一個以t開頭的單詞為止。
簡單介紹了B-/+Tree,至於眾多資料結構中,為何資料庫索引選擇BTree,而且選擇B+Tree,下面從計算機儲存原理方面簡單說說。
3、讀記憶體和讀磁碟
記憶體讀取和磁碟讀取的效率是相差很大的。
簡單點說說記憶體讀取,記憶體是由一系列的儲存單元組成的,每個儲存單元儲存固定大小的資料,且有一個唯一地址。
當需要讀記憶體時,將地址訊號放到地址總線上傳給記憶體,記憶體解析訊號並定位到儲存單元,然後把該儲存單元上的資料放到資料匯流排上,回傳。
寫記憶體時,系統將要寫入的資料和單元地址分別放到資料匯流排和地址總線上,記憶體讀取兩個匯流排的內容,做相應的寫操作。
記憶體存取效率,跟次數有關,先讀取A資料還是後讀取A資料不會影響存取效率。而磁碟存取就不一樣了,磁碟I/O涉及機械操作。
磁碟是由大小相同且同軸的圓形碟片組成,磁碟可以轉動(各個磁碟須同時轉動)。磁碟的一側有磁頭支架,磁頭支架固定了一組磁頭,每個磁頭負責存取一個磁碟的內容。磁頭不動,磁碟轉動,但磁臂可以前後動,用於讀取不同磁軌上的資料。磁軌就是以碟片為中心劃分出來的一系列同心環(如圖示紅那圈)。磁軌又劃分為一個個小段,叫扇區,是磁碟的最小儲存單元。
磁碟讀取時,系統將資料邏輯地址傳給磁碟,磁碟的控制電路會解析出實體地址,即哪個磁軌哪個扇區。於是磁頭需要前後移動到對應的磁軌,消耗的時間叫尋道時間,然後磁碟旋轉將對應的扇區轉到磁頭下,消耗的時間叫旋轉時間。所以,適當的操作順序和資料存放可以減少尋道時間和旋轉時間。

為了儘量減少I/O操作,磁碟讀取每次都會預讀,大小通常為頁的整數倍。即使只需要讀取一個位元組,磁碟也會讀取一頁的資料(通常為4K)放入記憶體,記憶體與磁碟以頁為單位交換資料。因為區域性性原理認為,通常一個數據被用到,其附近的資料也會立馬被用到。
4、檢索效能分析
B-Tree:如果一次檢索需要訪問4個節點,資料庫系統設計者利用磁碟預讀原理,把節點的大小設計為一個頁,那讀取一個節點只需要一次I/O操作,完成這次檢索操作,最多需要3次I/O(根節點常駐記憶體)。資料記錄越小,每個節點存放的資料就越多,樹的高度也就越小,I/O操作就少了,檢索效率也就上去了。
B+Tree:內節點只存key,大大滴減少了內節點的大小,那麼每個節點就可以存放更多的記錄,樹的更矮了,I/O操作更少了。所以B+Tree擁有更好的效能。
5、其他索引方式
雜湊索引:通過HASH來定位的一種索引,這種索引用的較少,通過用於單值查詢。InnoDB的自適應索引就是HASH索引。
點陣圖索引:欄位值固定且少,比如性別、狀態。在同時對多個這樣的欄位and/or查詢時,效率極高,直接按位與/或就可以得到結果了。所以,應用範圍侷限。