
一致性hash演算法和redis叢集動態資料儲存
記錄:對一致性Hash演算法,Java程式碼實現的深入研究連結地址:
http://www.cnblogs.com/xrq730/p/5186728.html
全部來自:
https://mp.weixin.qq.com/s/yimfkNYF_tIJJqUIzV7TFA
https://www.zhihu.com/question/53927336
未解決的疑問,如果有知道的歡迎討論:
1 什麼時候會出現同一個key會計算出不同的hash值呢?為什麼對於某些節點來說全域性節點不可見????
2 redis中的快取的slot和一致性hash演算法的環形儲存結構是如何對映的?
回答: 一致性hash計算的key的hash值對redis中的hash槽16384求餘,根據餘數確定key對應的hash槽,一個hash槽中會可能存放多個value值.??? 但是key貯存是根據順時針最近的節點儲存, 不知是否是 18384個槽對應2^32次方個數, redis中不同的槽位也代表了node節點覆蓋的位置,因此儲存在某個最近的節點其實是計算儲存的槽位??????
3 根據key值計算的hash值是否和節點個數相關?
回答:一致性hash演算法的計算key與節點的hash值與節點個數無關,其實下面的表述已經可以說明.
一致性hash演算法主要用於分散式快取中. 與傳統的簡單hash演算法相比,能有效解決分散式儲存結構下動態增加和刪除節點的問題.
比如:使用簡單hash%n (n表示分表的數量). 當資料量劇增,n張表已經無法儲存時,就需要增加分表.但是原先的hash規則會打亂.使用hash%(n+m) 無法查詢到原來儲存的資料,因此需要進行整體的資料遷移,代價較高.
一致性hash演算法:
1 我們把全量的快取空間當做一個環形儲存結構。環形空間總共分成2^32個快取區,在Redis中則是把快取key分配到16384個slot。

2 每一個快取key都可以通過Hash演算法轉化為一個32位的二進位制數,也就對應著環形空間的某一個快取區。我們把所有的快取key對映到環形空間的不同位置。
3 我們的每一個快取節點(Shard)也遵循同樣的Hash演算法,比如利用IP做Hash,對映到環形空間當中。
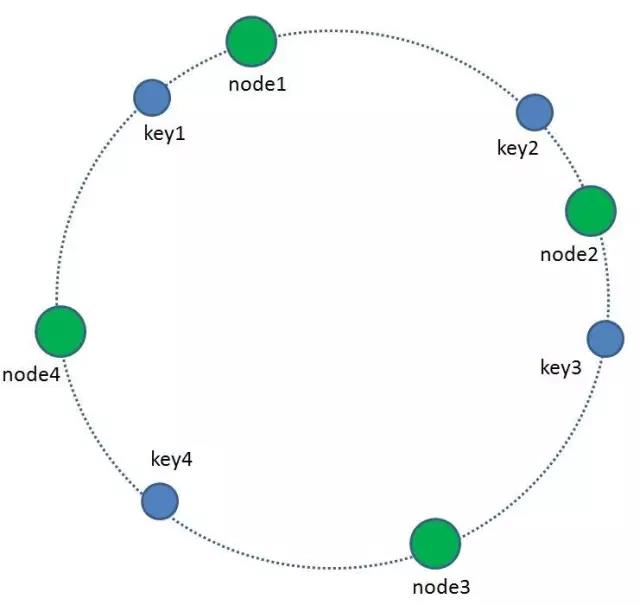
4 如何讓key和節點對應起來呢?很簡單,每一個key的順時針方向最近節點,就是key所歸屬的儲存節點。所以圖中key1儲存於node1,key2,key3儲存於node2,key4儲存於node3。
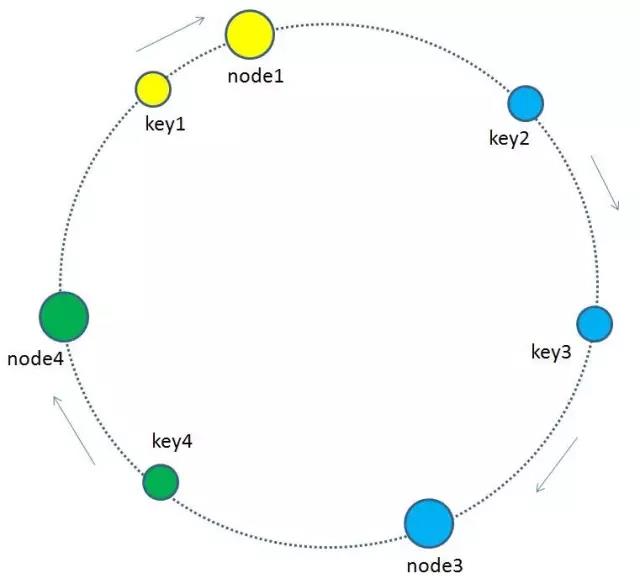
增加節點時:
當快取叢集的節點有所增加的時候,整個環形空間的對映仍然會保持一致性雜湊的順時針規則,所以有一小部分key的歸屬會受到影響。
有哪些key會受到影響呢?圖中加入了新節點node4,處於node1和node2之間,按照順時針規則,從node1到node4之間的快取不再歸屬於node2,而是歸屬於新節點node4。因此受影響的key只有key2。(我理解計算同一個key的hash值不變,但是掛載到不同的節點中,原節點的資料還存在,因此存在資料的冗餘, 但是實際在測試時這個想法是錯的. 因為在新增加節點的時候, 重新分配slot槽點時, 會將原來槽點中儲存的資料會移動到新的節點中, 原來槽點中的資料也已經不存在, 因此不存在資料的冗餘.)
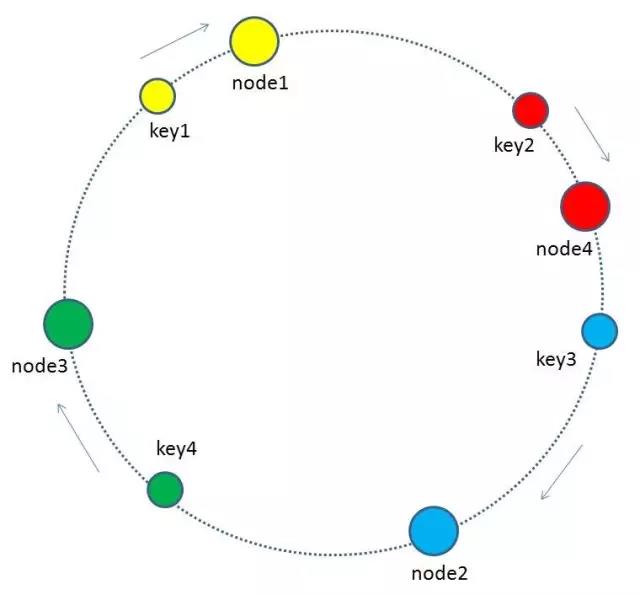
最終把key2的快取資料從node2遷移到node4,就形成了新的符合一致性雜湊規則的快取結構。
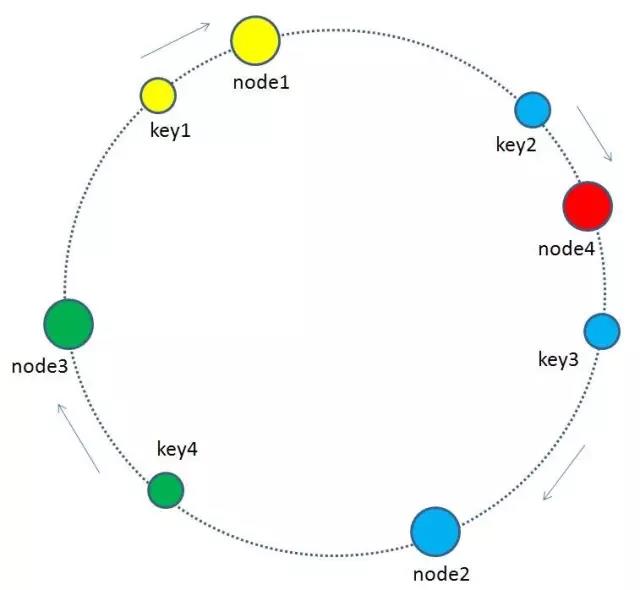
刪除節點
當快取叢集的節點需要刪除的時候(比如節點掛掉),整個環形空間的對映同樣會保持一致性雜湊的順時針規則,同樣有一小部分key的歸屬會受到影響。
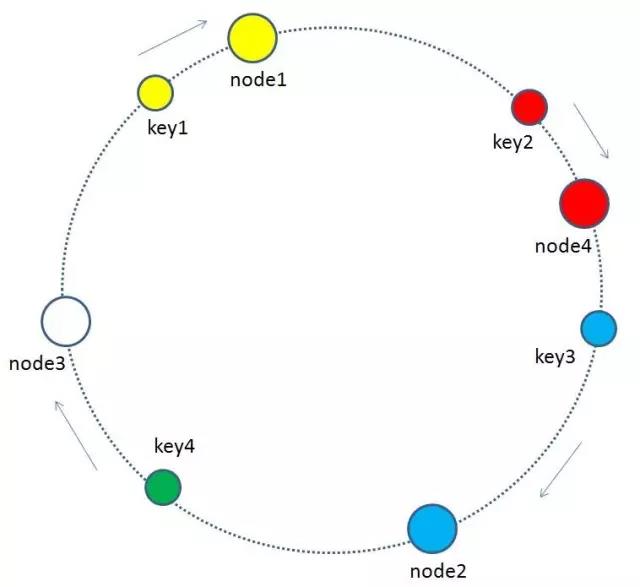
有哪些key會受到影響呢?圖中刪除了原節點node3,按照順時針規則,原本node3所擁有的快取資料就需要“託付”給node3的順時針後繼節點node1。因此受影響的key只有key4。
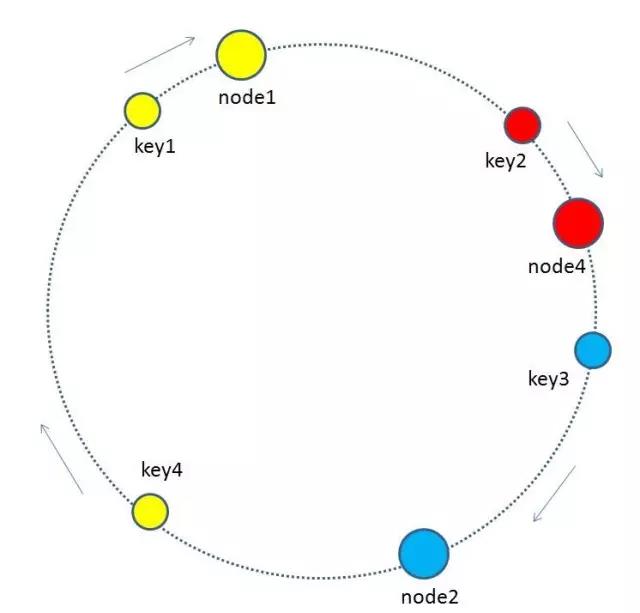
最終把key4的快取資料從node3遷移到node1,就形成了新的符合一致性雜湊規則的快取結構.
由於node3已經掛掉,原來在node3上的節點快取的資料不是直接從node3遷移過去,而是在再次查詢時去查詢順時針的後續的後繼節點,因快取沒有命中而重新整理快取,重新掛載到新的節點中.
4 每個快取節點都按照iphash到環形空間,可能出現分佈不均的情況,因此為了優化引入了虛擬節點.基於原來的物理節點映射出N個子節點,最後全部對映到環形空間.
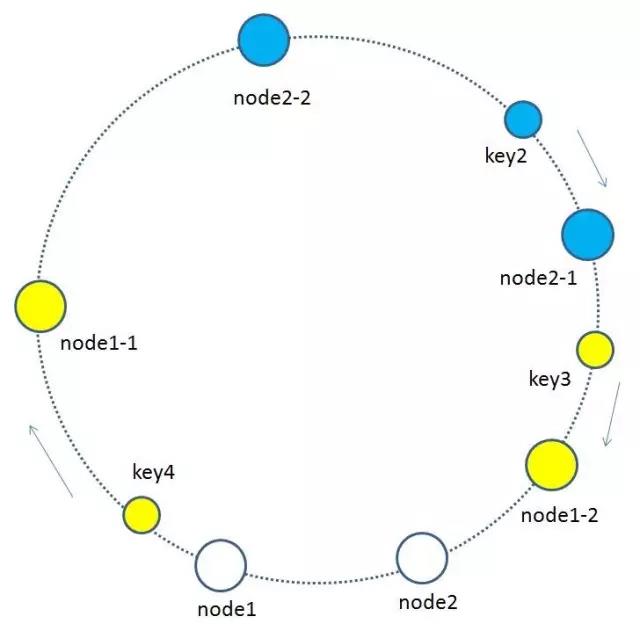
如上圖所示,假如node1的ip是192.168.1.109,那麼原node1節點在環形空間的位置就是hash(“192.168.1.109”)。
我們基於node1構建兩個虛擬節點,node1-1 和 node1-2,虛擬節點在環形空間的位置可以利用(IP+字尾)計算,例如:
hash(“192.168.1.109#1”),hash(“192.168.1.109#2”)
此時,環形空間中不再有物理節點node1,node2,只有虛擬節點node1-1,node1-2,node2-1,node2-2。由於虛擬節點數量較多,快取key與虛擬節點的對映關係也變得相對均衡了。
redis叢集hash演算法:
redis 3.0使用的是hash槽的概念,沒有使用一致性hash演算法.Redis的作者認為它的crc16(key) mod 16384的效果已經不錯了,雖然沒有一致性hash靈活,但實現很簡單,節點增刪時處理起來也很方便。
當往Redis Cluster中加入一個Key時,會根據crc16(key) mod 16384計算這個key應該分佈到哪個hash slot中,一個hash slot中會有很多key和value。可以理解成表的分割槽,使用單節點時的redis時只有一個表,所有的key都放在這個表裡;改用Redis Cluster以後會自動生成16384個分割槽表,你insert資料時會根據上面的簡單演算法來決定key應該存在哪個分割槽,每個分割槽裡有很多key。