
批量計算和流計算簡單比對
剛剛說的:收集資料 - 放到DB中 - 取出來分析 的傳統的流程,叫做批量計算,顧名思義,將資料存起來,批量進行計算。
而流式計算,也跟名字一樣,是對資料流進行實時計算,它不是更快的批計算,可以說,是完全不同的處理思路。
通過與批量計算進行對比的方式,介紹下其原理:
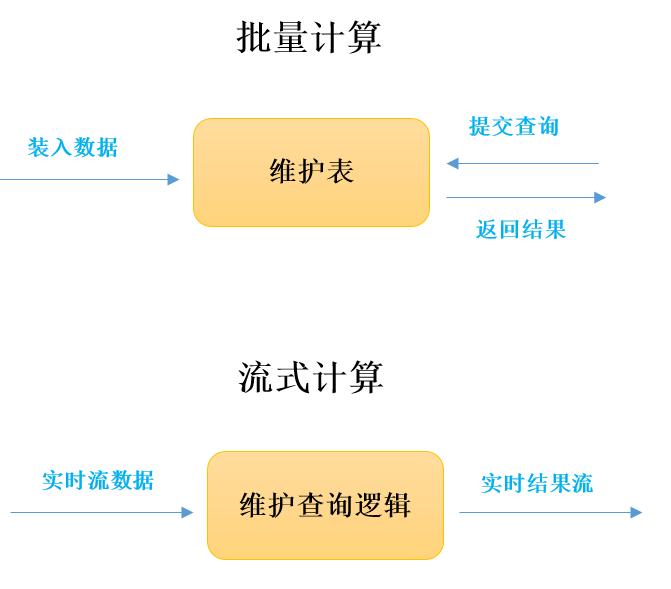
(1) 與批量計算那樣慢慢積累資料不同,流式計算將大量資料平攤到每個時間點上,連續地進行小批量的進行傳輸,資料持續流動,計算完之後就丟棄。
(2) 批量計算是維護一張表,對錶進行實施各種計算邏輯。流式計算相反,是必須先定義好計算邏輯,提交到流失計算系統,這個計算作業邏輯在整個執行期間是不可更改的。
(3) 計算結果上,批量計算對全部資料進行計算後傳輸結果,流式計算是每次小批量計算後,結果可以立刻投遞到線上系統,做到實時化展現。
相關推薦
批量計算和流計算簡單比對
剛剛說的:收集資料 - 放到DB中 - 取出來分析 的傳統的流程,叫做批量計算,顧名思義,將資料存起來,批量進行計算。 而流式計算,也跟名字一樣,是對資料流進行實時計算,它不是更快的批計算,可以說,是完全不同的處理思路。 通過與批量計算進行對比的方式,介紹下其原理: (1) 與批量計算那樣慢慢積累資
大資料開發:實時資料平臺和流計算
大資料開發 1、實時資料平臺整體架構 實時資料平臺的支撐技術主要包含四個方面:實時資料採集(如Flume),訊息中介軟體(如Kafka), 流計算框架(如Storm, Spark, Flink和Beam),以及資料實時儲存(如列
更適合物聯網的邊緣計算,可能只是投機者的一塊雞肋 (雲端計算和邊緣計算對比分析)
摘要: 物聯網又迎來了新風口,但這個風口咬下去可能沒多少肉。 圖片來源 © 視覺中國 前沿科技產業的一個特點,就是總會給大家制造出各種各樣的風口。這些風口往往有著特別酷炫的名字,有強大的學術論證和巨頭背書,但真正落實到應用性和商業行為當中,結果怎麼樣又不好說了。 比
Linux 桌面玩家指南:14. 數值計算和符號計算
特別說明:要在我的隨筆後寫評論的小夥伴們請注意了,我的部落格開啟了 MathJax 數學公式支援,MathJax 使用$標記數學公式的開始和結束。如果某條評論中出現了兩個$,MathJax 會將兩個$之間的內容按照數學公式進行排版,從而導致評論區格式混亂。如果大家的評論中用到了$,但是又不是為了使用數學
科普:平行計算、分散式計算、叢集計算和雲端計算
1. 平行計算(Parallel Computing) 平行計算或稱平行計算是相對於序列計算來說的。平行計算(Parallel Computing)是指同時使用多種計算資源解決計算問題的過程。為執行平行計算,計算資源應包括一臺配有多處理機(並行處理)的計算機、一個與網路相連的計算機專有編
分散式計算和平行計算差異
Mapreduce是分散式計算的典型技術,MPI則是平行計算的典型技術。總結下來主要兩點區別: 1、分散式計算(如MapReduce)的計算節點任務往往是獨立的,鬆散的。不涉及大規模的資料互動,因此節點之間執行幾乎互不影響。體現到技術架構上就使得可以做到計算和儲存在同一個節點上,不存在計算節
邊緣快取:實現雲端計算和邊緣計算協同作用的關鍵
邊緣快取:實現雲端計算和邊緣計算協同作用的關鍵 資料是新的黃金,而“邊緣到雲”使組織可以從任何地方獲取所有資料。企業需要一種結合邊緣計算和雲端儲存優勢的混合解決方案,實現雲端計算和邊緣計算協同作用所需的關鍵技術是邊緣快取。 在分散式企業中,“邊緣儲存”是指端點裝置中的資料儲存,例如
平行計算、分散式計算、叢集計算和雲端計算
科普:平行計算、分散式計算、叢集計算和雲端計算 1. 平行計算(Parallel Computing) 平行計算或稱平行計算是相對於序列計算來說的。平行計算(Parallel Computing)是指同時使用多種計算資源解決計算問題的過程。為執行平行計算,計算資源應
細說雲端計算之外的霧計算與流計算
自從有了雲端計算,人們就想著如何讓資料中心和雲端計算更好地結合起來,於是“雲資料中心”的概念出現,簡單地說就是部署了雲端計算的資料中心。 但偏偏事與願違,雲端計算和資料中心結合的例子並不多,更多的雲資料中心只是將原來的資料中心換個名字,根本談不上和雲端計算有什麼關聯。這也不能全怪雲端計算,怪只能怪資
雲端計算、霧計算和邊緣計算
霧計算,是一種分散式的計算模型,作為雲資料中心和物聯網(IoT)裝置/感測器之間的中間層,它提供了計算、網路和儲存裝置,讓基於雲的服務可以離物聯網裝置和感測器更近。霧計算的概念的引入,也是為了應對傳統雲端計算在物聯網應用時所面臨的挑戰。邊緣計算是一種通過在資料來源附近的網路邊緣執行資料處理來優化雲端計算系統的
雲端計算和分散式計算,網格計算,平行計算對比分析
現在把早上看到的雲端計算和分散式計算,網格計算,平行計算的概念對比分析一下。 其實是要了解雲端計算,但是這幾個名字叫得容易把問題搞混。就先從關係最不大的說吧。 平行計算(Parallel Computing) 並 行計算或稱平行計算是相對於序列計算來說的;所謂平行計算可分為時
[C#] 計算大檔案的MD5的兩種方式(直接呼叫方法計算,流計算-適用於大檔案)
通過.NET中的預設類實現,但是採用不同類,針對不同的情況: 具體如下: 類: /// <summary> /// 檔案MD5操作類 /// </summary> public class MD5Checker {
分散式計算和平行計算的異同
轉載:http://www.equn.com/forum/thread-4876-1-1.html 解決物件上:都是大任務化為小任務,這是他們共同之處。但是分散式的任務包互相之間有獨立性,上一個任務包的結果未返回或者是結果處理錯誤,對下一個任務包的處理幾乎沒有什麼影響。因此
基於OGG和Datahub的阿里流計算Flink平臺簡介
平臺簡介 在傳統的資料處理流程中,總是先收集資料,然後再把資料放到DB中,等到需要的時候再進行相關處理,這種模式不適合某些需要實時資料的應用平臺,例如稅務的實時申報率,這種採用MR等離線處理並不能很好的解決問題,於是新的資料計算結構:Flink流計算應時而生,它可以對大規模流動資料在不斷變化
對分散式儲存和平行計算的一點思考
分散式儲存: 首先是檔案在HDFS上面以128M塊大小儲存(3份),這三塊是在不同節點的(機架感知),我覺的好處是容錯還有當計算是這個節點資源不夠可以去塊所在的另一節點執行,不用拉取資料。 可以通過fs.getfileblocklocation()獲取塊位置 平行計算: 1、MR使用預設的輸
基於Spark機器學習和實時流計算的智慧推薦系統
原文連結:http://blog.csdn.net/qq1010885678/article/details/46675501 概要: 隨著電子商務的高速發展和普及應用,個性化推薦的推薦系統已成為一個重要研究領域。 個性化推薦演算法是推薦系統中最核心的技術,在很大程
Flink流計算中SQL表的概念和原理
文章目錄 前言 動態表和動態查詢的概念 動態表的時間屬性 引用 前言 Fink在新發布的1.7版本中,不斷完善和加強了SQL&Table API方面的功能支援。這使得在流計算過程中,使用者同樣能夠運用熟悉的SQL
並行流計算--統計1-n的和,計算密集型
import java.util.function.Function; import java.util.stream.LongStream; import java.util.stream.Stream; public class ParalleStreamDemo {
java對Linux系統的CPU利用率的計算和記憶體資訊的獲取
程序檔案系統,procfs,是一個偽檔案系統,它允許對一些非傳統意義上的檔案通過標準檔案I/O介面進行訪問。procfs將Solaris核心程序架構進行了抽象,當前系統中所有執行著的程序會在/proc/目錄下有所體現。/proc/目錄下的物件不是真實磁碟檔案,這
7、Flink 流計算處理和批處理平臺
一、Flink 基本概念 Flink 是一個批處理和流處理結合的統一計算框架,其核心是一個提供了資料分發以及並行化計算的流資料處理引擎。它的最大亮點是流處理,是業界最頂級的開源流處理引擎。Flink 與 Storm 類似,屬於事件驅動型實時流系統。 所謂說事件驅動型指