
python 爬取資訊文章並儲存html及pdf格式
阿新 • • 發佈:2018-12-26
一、需求
研究生學長讓我把一個植物表型資訊系列文章的一系列文章爬下來儲存為pdf或者html格式。
首頁網址:
https://mp.weixin.qq.com/s?__biz=MzI0Mjg5ODI1Ng==&mid=2247486022&idx=1&sn=5f7c9aff1e3f1847812ce92304a3affc&chksm=e9740e79de03876fffc5ca39f70c105298acf5d2329d632e69cb997f8a07ba1234f97c91464c&scene=21#wechat_redirect

二、思路分析
列表的每一篇文章都應該是一個連結,因此先將首頁儲存下來分析其元素結構

找到各連結所在主體<div>元素<div class="rich_media_content " id="js_content">記錄

確認每一個文章連結都在都是<a>元素
因此思路就是 先獲得主體塊中的連結標籤,根據文章名和連結儲存每一篇文章。
三 、難點
難點在於儲存pdf時,圖片是要儲存在pdf之中的,因此如果文章介面圖片如果是是懶載入的時候,爬取的文章儲存位html和pdf 圖片都將會是空白的。
因此先去分析文章中圖片的載入形式
選一篇文章分析:

可以看到圖片載入採用的是
data-src載入的,因此需要將每一個<img>的標籤t圖片連結改成src形式。
四、採用工具
import requests//用來請求獲得頁面
import pdfkit// 用來儲存成pdf格式
from bs4 import BeautifulSoup//用來將html劃分成各標籤進行處理五、原始碼
# -*- coding:UTF-8 -*-
import time
import requests
import pdfkit
import re
from bs4 import BeautifulSoup
# 模版
html_template = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
</head>
<body>
{content}
</body>
</html>
""" 六、效果展示
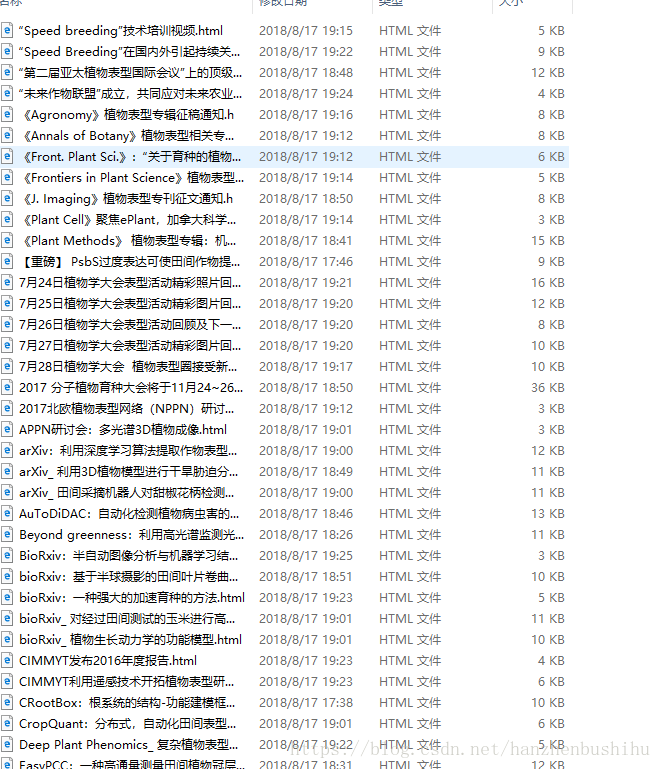
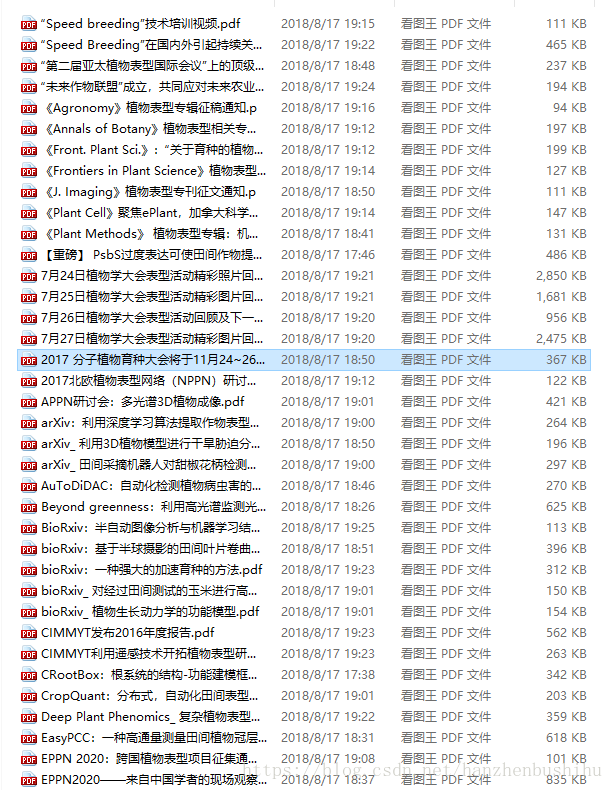
其中一篇pdf,可以看到是帶有圖片的。
