
基於 Netty 如何實現高效能的 HTTP Client 的連線池
使用netty作為http的客戶端,pool又該如何進行設計。本文將會進行詳細的描述。
1. 複用型別的選型
1.1 channel 複用
多個請求可以共用一個channel
模型如下:
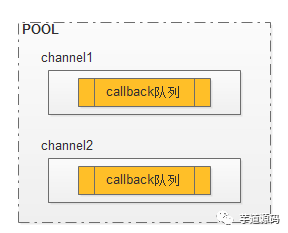
特點:
-
1:callback佇列為回撥佇列。 不同的callback通過一個全域性的id進行標識。傳送的時候會把該id發到服務端,服務端在回覆的時候必須把該id再返回到客戶端。
-
2:獲取連線只需要隨機獲取一個channel即可,將callback新增到佇列裡面。
-
3: 獲取連線時消除了鎖的競爭,效能高效。
-
4:結構簡單。
示例:
-
osp(唯品會的SOA框架) client pool實現(thrift協議)
-
spray 的 akka client pool
約束:
需要服務端配合支援channel複用。需要有一個全域性唯一的id用於識別請求。 通常id先發給服務端,服務端還要把id會給客戶端。
1.2 channel 獨享
每個請求獨立使用一個channel。
模型如下:
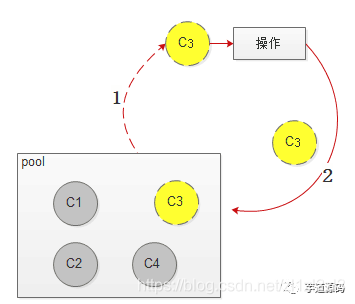
特點:
-
1:同一個channel同時只給一個request使用。
-
2:連線池的設計較為複雜。
示例:
-
1:資料庫連線池[druid,c3p0,dbcp,hikaricp,caelus(唯品會內部連線池)]
-
2:netty的http pool ; apache的httpclient pool, httpasyncclient pool ; nginx的pool。
1.3 選擇
由於http1.1協議原生不支援channel複用(http2是支援的),如果需要支援,則需要在header裡面加入一個唯一id,所有的應用伺服器均需要進行改動。為了和nginx的連線池保持一致,確定使用channel的獨享方式。
2. 元件選型
| 元件 | 優點 | 缺點 |
|---|---|---|
| common-pool | 功能完整 | 不支援非同步連線 |
| rxnetty pool | 功能完整,支援netty | 使用的為rxjava機制 |
| netty pool | netty原生實現 | 功能較為簡單 |
選擇netty pool作為連線池的實現。4.0.33版本有該功能,可能老版本沒有pool的功能。
3. pool的設計
3.1 模型
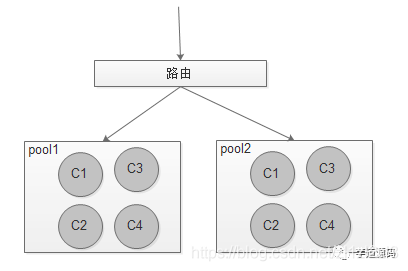
通過ip,port路由到對應的pool,每個pool之間完全獨立。
3.2 主要功能點

3.3 獲取連線
-
1:通過控制最大連線數,來避免無限的建立連線。
-
2:當超過最大連線數時,則需要等待。由於整個流程是全非同步的,需要將當前資訊進行任務封裝註冊回撥。
-
3:需要設定等待連線的個數及超時時間,避免把記憶體給撐爆。
-
4:需要對獲取的連線進行有效性檢查。一般只需校驗channel.isactive()即可。如果檢驗失敗,需要重新獲取有效連線。
3.4 資源池
-
1:使用無鎖的ConcurrentLinkedDeque 雙向佇列來存放所有idle的連線(jdk1.7才有該類)。
-
2:該佇列通過cas的操作來避免同步。 由於拿到連線後業務執行的速度較慢,所以這裡的cas衝突應該很小。
3.5 歸還連線
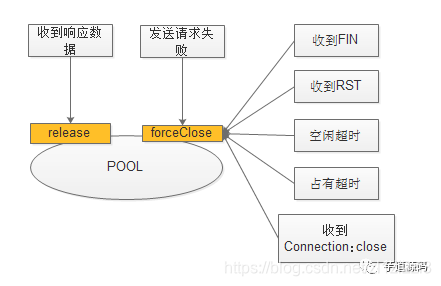
歸還連線主要包含兩部分:正常release和異常的forceClose
-
1:在netty中,如果收到FIN(服務端傳送的正常close請求),則會通知到netty的channelInactive介面,需要在該介面處進行forceClose.
-
2:收到RST(服務端非正常的關閉),則會通知到exceptionCaught介面,需要在該介面處進行foreclose。關於RST的問題可參考:http://blog.csdn.net/hetaohappy/article/details/51851880
-
3:在收到正常資料後(channel的channelRead介面),需要判斷header裡面是否有Connection:close,如果有,則進行forceClose,否則進行release
-
4:如果空閒超時,則關閉連線,來避免連線一直被無效的佔用。只需要增加IdleStateHandler ,判斷連線空閒超時,則fire一個event事件。只需要註冊對該事件的監聽,進行foreclose即可。
-
5:佔有超時:連線在規定的時間內未還,則進行forceClose。
6:傳送請求時,發現channel已經被close掉或者其他io異常,則進行forceClose。
7:forceclose接口裡面,需要通過一個狀態位來控制是否操作 acquiredChannelCount(已獲取連線數)。由於呼叫forceclose,連線可能在資源池中,如果操作該欄位,會導致該欄位統計不準確。
3.6 超時控制
獲取連線timeout
在規定的時間內沒有獲取到連線,則拋異常。
-
1:一般實現是通過ReentrantLock來設定lock的超時時間或者直接通過unsafe.park設定超時時間。該種機制會對當前執行緒進行block。
-
2:由於netty是純非同步機制,如果進行block,會嚴重影響效能。所以這裡是將當前資訊進行task封裝,然後schedule一個定時任務。如果在設定時間內該task沒有被消費,則會丟擲timeout的異常。
建立連線timeout
-
1:在BIO中,通過設定socket的connect(SocketAddress endpoint, int timeout) 時間即可。Tips:該值不要和setSoTimeout(int timeout)混淆,sotimeout是設定呼叫read的超時時間。
-
2:在NIO中,需要業務自己控制連線的超時時間。 一般是通過schedule一個定時任務來控制超時時間。(在netty中即使用的該機制)
連線空閒timeout
-
1: 通過設定一個handler(IdleStateHandler ),在新建連線的時候schedule一個任務(時間為空閒超時時間),在呼叫read或者write方法的時候,進行時間的更新。如果任務執行的時候發現空閒超時,則進行event的觸發。
-
2:業務handler捕獲該event,進行連線空閒超時的處理。
連線被佔有timeout
避免連線洩露
-
1:在獲取連線的時候 schedule一個任務(時間為連線被佔用的timeout),在歸還的時候會cancel該任務。如果該任務被執行,說明在規定的時間沒有歸還,則進行timeout的處理。
3.7 效能優化
-
1:資源池無鎖化:ConcurrentLinkedDeque (前面已有介紹)
-
2:acquiredChannelCount(已獲取連線數)的無鎖化(該欄位用來控制是否達到了最大連線數,正常情況為獲取連線後加1,歸還連線後減1)。
連線池均會通過acquiredChannelCount來控制當前已經獲取的連線個數。該引數會面臨著多執行緒的競爭,需要進行同步或者cas的設計。如何設計讓acquiredChannelCount完全不用考慮多執行緒競爭?
看能不能從akka的設計中找點思路: akka消除競爭的方式就是讓一個actor同一時刻只能在一個執行緒中執行,這樣actor裡面所有的全域性引數就不需要考慮多執行緒競爭,一個actor裡面所有的任務都是序列執行的,完全消除競爭。
那麼能不能序列操作acquiredChannelCount呢? 答案是可以的,並且在netty中實現非常簡單,只需要實現如下程式碼即可:
if (executor.inEventLoop()) {
acquiredChannelCount++;
} else{
executor.execute(newOneTimeTask() {
@Override
public void run() {
acquiredChannelCount++;
}
}
}
其中executor 就是一個固定的執行緒。判定當前執行的執行緒是否是executor這個執行緒,如果是則直接執行。如果不是,則放到executor執行緒的佇列裡達到序列操作的目的(類似於actor的mailbox) (netty的設計及抽象能力確實非常高)
3.8 配置引數
-
http_pool_aquire_timeout :獲取連線超時時間:預設為5000ms
-
http_pool_maxConnections:連線大小:預設為1000
-
http_connection_timeout :建立連線的超時時間:預設為5000ms
-
http_pool_idle_timeout:連線空閒多久關閉:預設為:30分鐘
-
http_pool_maxPending:連線池不夠用,最大允許有多少個pendingRequest:預設為無限大
-
http_pool_maxHolding:拿連線的使用時間。在規定時間未還,則強制close掉。預設為5000ms。
4. 面臨的問題
-
1:所有的操作都是純非同步,導致callback巢狀的特別深(netty通過promise機制,來方便callback的使用),如果控制不好,很容易出問題。
-
2:連線被require後,一定要保證歸還,由於非同步特性,很容易在某些異常下將連線漏還(筆者遇到在高併發下由於程式碼bug導致漏還的情況)
-
3:如何避免在拿到連線後,同時web伺服器(http的keepalive機制)將該連線給close掉了,導致執行的失敗。有兩種解決方案可以參考。
-
捕獲執行失敗的異常,如果是特定的異常,則forceClose當前的連線,重新拿一個連線進行訪問。如果超過重試次數,則丟擲異常。
-
如何確定該執行緒定時的時間。後端web伺服器對連線的超時時間可能不一致,該定時時間一定要小於web伺服器的連線超時時間。
-
心跳執行的介面問題。需要所有的web伺服器均需要實現固定的介面進行心跳檢測,可行性比較差。
-
3.1:可以參考common-pool的設計思想,在後端開啟一個執行緒定時對所有連線進行心跳檢測。問題:
-
如何確定該執行緒定時的時間。後端web伺服器對連線的超時時間可能不一致,該定時時間一定要小於web伺服器的連線超時時間。
-
心跳執行的介面問題。需要所有的web伺服器均需要實現固定的介面進行心跳檢測,可行性比較差。
-
-
3.2:重試機制:
-
捕獲執行失敗的異常,如果是特定的異常,則forceClose當前的連線,重新拿一個連線進行訪問。如果超過重試次數,則丟擲異常。
-
-