
轉:大小端問題
By unanao
一、什麼是大小端問題
(From《Computer Systems,A Programer's Perspective》)在幾乎所有的機器上,多位元組物件被儲存為連續的位元組序列,物件的地址為所使用位元組序列中最低位元組地址。
小端:某些機器選擇在儲存器中按照從最低有效位元組到最高有效位元組的順序儲存物件,這種最低有效位元組在最前面的表示方式被稱為小端法(little endian) 。這樣的儲存模式有點兒類似於把資料當作字串順序處理:地址由小向大增加,而資料從高位往低位放;
大端:某些機器則按照從最高有效位元組到最低有效位元組的順序儲存,這種最高有效位元組在最前面的方式被稱為
舉個例子來說名大小端: 比如一個int x, 地址為0x100, 它的值為0x1234567. 則它所佔據的0x100, 0x101, 0x102, 0x103地址組織如下圖:
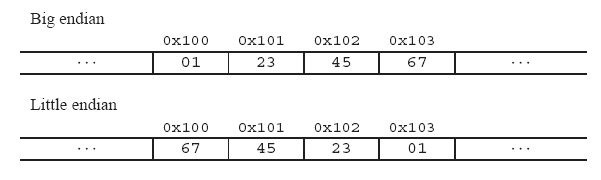
二、為什麼會有大小端模式之分呢?
這是因為在計算機系統中,我們是以位元組為單位的,每個地址單元都對應著一個位元組,一個位元組為 8bit。但是在C語言中除了8bit的char之外,還有16bit的short型,32bit的long型(要看具體的編譯器),另外,對於位數大於 8位的處理器,例如
三、如何區分大小端問題:
方法1:
#include <stdio.h>
int main(void)
{
int i = 1;
unsigned char *pointer;
pointer = (unsigned char *)&i;
if(*pointer)
{
printf("litttle_endian");
}
else
{
printf("big endian\n");
}
return 0;
}
C中的資料型別都是從記憶體的低地址向高地址擴充套件,取址運算"&"都是取低地址。小端方式中(i佔至少兩個位元組的長度)則i所分配的記憶體最小地址那個位元組中就存著1,其他位元組是0。大端的話則1在i的最高地址位元組處存放,char是一個位元組,所以強制將char型量p指向i,則p指向的一定是i的最低地址,那麼就可以判斷p中的值是不是1來確定是不是小端。
方法2:
#include <stdio.h>
int main(void)
{
union {
short a;
char ch;
} u;
u.a = 1;
if (u.ch == 1)
{
printf("Littel endian\n");
}
else
{
printf("Big endian\n");
}
}
利用聯合體的特點,資料成員共享記憶體空間,union中元素的起始地址都是相同的——位於聯合的開始。 用char來擷取感興趣的位元組。
四、需要考慮大小端(位元組順序)的情況
1、所寫的程式需要向不同的硬體平臺遷移,說不定哪一個平臺是大端還是小端,為了保證可移植性,一定提前考慮好。
2. 在不同型別的機器之間通過網路傳送二進位制資料時。 一個常見的問題是當小端法機器產生的資料被髮送到大端法機器或者反之時,接受程式會發現,字(word)裡的位元組(byte)成了反序的。為了避免這類問 題,網路應用程式的程式碼編寫必須遵守已建立的關於位元組順序的規則,以確保傳送方機器將它的內部表示轉換成網路標準,而接受方機器則將網路標準轉換為它的內部標準。
3. 當閱讀表示整數的位元組序列時。這通常發生在檢查機器級程式時,e.g.:反彙編得到的一條指令:
80483bd: 01 05 64 94 04 08 add %eax, 0x8049464
3. 當編寫強轉的型別系統的程式時。如寫入的資料為u32型,但是讀取的時候卻是char型的。如:0x1234, 大端讀取為12時,小端獨到的是34。
六、提高程式的可移植性
使用巨集編譯
#ifdef LITTLE_ENDIAN
//小端的程式碼
#else
//大端的程式碼
#endif
七、大、小端之間的轉換
1、小端轉換為大端
#include <stdio.h>
void show_byte(char *addr, int len)
{
int i;
for (i = 0; i < len; i++)
{
printf("%.2x \t", addr[i]);
}
printf("\n");
}
int endian_convert(int t)
{
int result;
int i;
result = 0;
for (i = 0; i < sizeof(t); i++)
{
result <<= 8;
result |= (t & 0xFF);
t >>= 8;
}
return result;
}
int main(void)
{
int i;
int ret;
i = 0x1234567;
show_byte((char *)&i, sizeof(int));
ret = endian_convert(i);
show_byte((char *)&ret, sizeof(int));
return 0;
}
posted on 2012-12-26 16:06 胡滿超 閱讀(631) 評論(0) 編輯 收藏 引用 所屬分類: 演算法 、轉載