《深度學習——Andrew Ng》第五課第一週程式設計作業_2_dinosaurus island
阿新 • • 發佈:2018-12-29
第二課的作業是給恐龍起名,訓練集是一系列恐龍的名字,經過訓練後,RNN網路可以生成新的恐龍的名字,隨著訓練次數的迭代,可以發現得到的名字越來越像是正常的恐龍名字。
這裡有兩點需要注意一下:
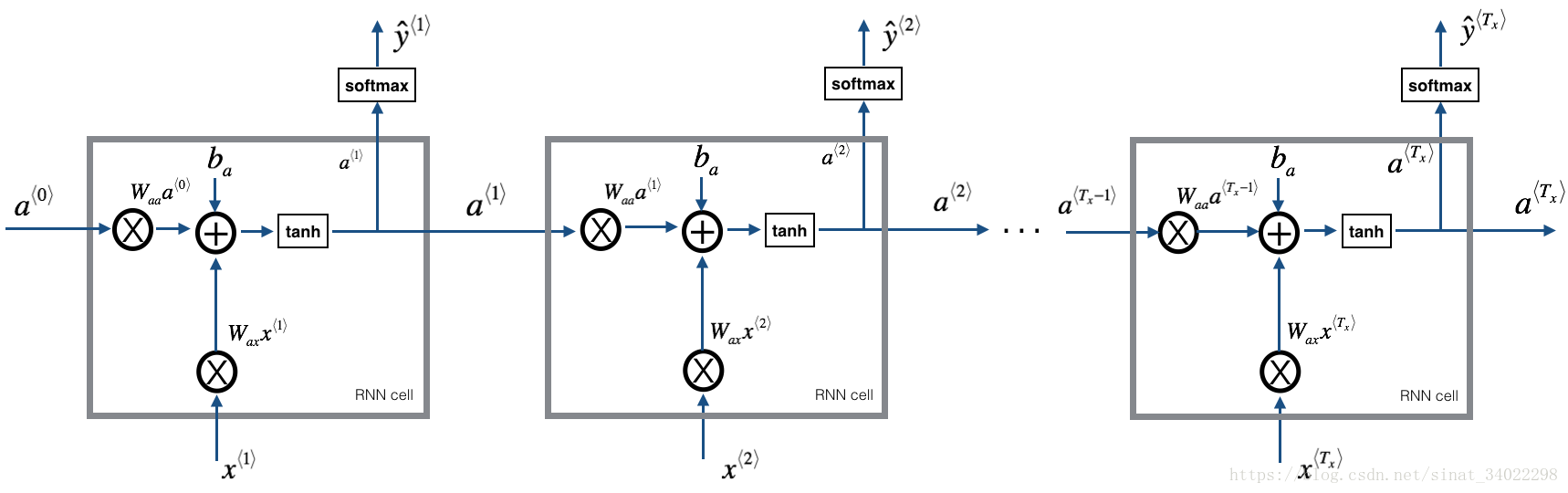
使用的模型RNN
圖中的每個cell都把計算流程標清楚了
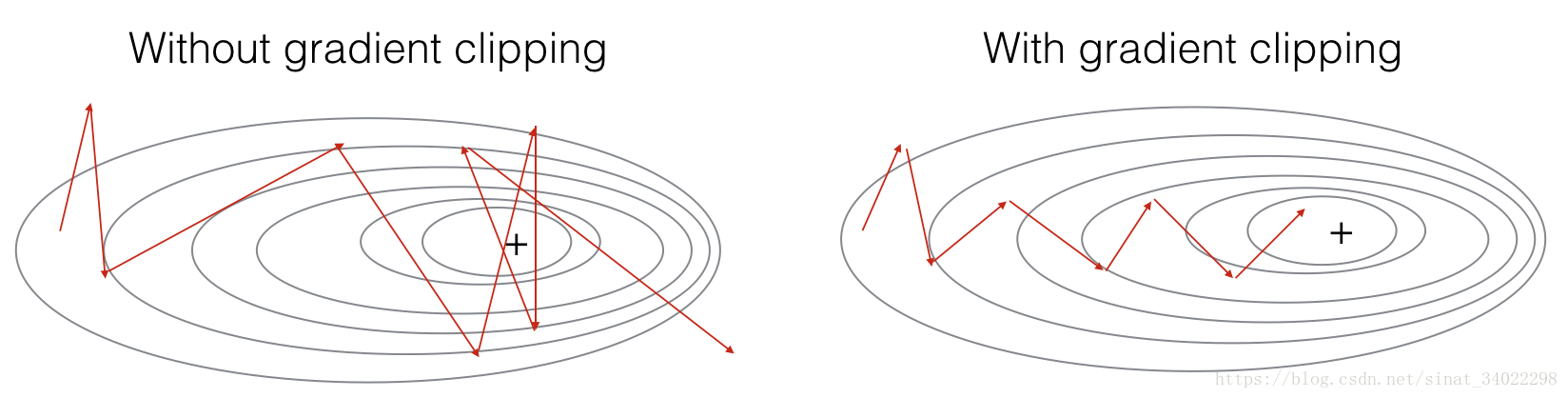
clip剪枝函式
使用梯度下降進行後向傳播,所以存在單次迭代梯度過大的情況,這裡使用函式進行梯度數值的約束,讓每次的梯度值在一個閾值內。(剪枝可能不太準確,叫梯度正則化可能會好一點。。。)
程式Pycharm版
# dinosaurus island
import numpy as np
from utils import 結果
下面是RNN在訓練的不同階段,輸出的名字: