
使用 paddle來進行文字生成
paddle 簡單介紹
paddle 是百度在2016年9月份開源的深度學習框架。
就我最近體驗的感受來說的它具有幾大優點:
1. 本身內嵌了許多和實際業務非常貼近的模型比如個性化推薦,情感分析,詞向量,語義角色標註等模型還有更多實際已經內嵌了但是目前還沒有出現在官方文件上的模型比如物體檢測,文字生成,影象分類,ctr預估等等,可以快速應用到專案中去
2. 就實際體驗來看,訓練的速度相比於呼叫keras,在同等資料集上和相同網路架構上要快上不少。當然也是因為keras本身也是基於在tensorflow或者theano上面的,二次呼叫的速度不如paddle直接呼叫底層迅速。
缺點也有很多:
1. 一開始的安裝對新手極其的不友好,使用docker安裝感覺這個開源框架走不長久,所幸這個問題已經解決。
2. 目前很多的文件並不完善,也許百度系的工程師目前對這方面其實並不是很重視,新手教程看起來並非那麼易懂。
3. 層的封裝並不到位,很多神經網路層得自己去寫,感覺非常的不方便。
最後希望藉由本文,可以讓你快速上手paddle。
一分鐘安裝paddle
docker 安裝
之前paddle的安裝方式是使用docker安裝,感覺非常的反人類。
安裝命令:
docker pull paddlepaddle/paddle:latest
pip 安裝
現在已經支援pip 安裝了。對(OS: centos 7, ubuntu 16.04, macos 10.12, python: python 2.7.x) 可以直接使用
pip install paddlepaddle 安裝cpu 版本。
pip install paddlepaddle-gpu 安裝gpu 版本。
安裝完以後,測試的程式碼
import paddle.v2 as paddle x = paddle.layer.data(name='x', type=paddle.data_type.dense_vector(13)) y = paddle.layer.fc(input=x, size=1, param_attr=paddle.attr.Param(name="fc.w")) params = paddle.parameters.create(y) print params["fc.w"].shape
當輸出 [13,1],那麼恭喜你,已經成功安裝了paddle.
遇到的問題
當我在使用pip 安裝方式安裝了gpu版本的paddle以後,遇到了numpy 版本不相容的問題。解決的辦法是:在把本地的numpy解除安裝以後,我首先把安裝的paddle解除安裝了,然後重新再安裝了一遍paddle。這樣在安裝的過程當中,可以藉由paddle的安裝過程來檢測你係統的其他python包是否符合paddle需要的環境。其他類似的python包的問題,都可以藉由這個辦法幫忙解決。
使用paddle中的迴圈神經網路來生成文字
背景簡介
首先paddle實際上已經內嵌了這個專案:
https://github.com/PaddlePaddle/models/tree/develop/generate_sequence_by_rnn_lm
文字生成有很多的應用,比如根據上文生成下一個詞,遞迴下去可以生成整個句子,段落,篇章。目前主流生成文字的方式是使用rnn來生成文字。
主要有兩個原因:
1. 因為RNN 是將一個結構反覆使用,即使輸入的文字很長,所需的network的引數都是一樣的。
2. 因為RNN 是共用一個結構的,共用引數的。可以用比較少的引數來訓練模型。這樣會比較難訓練,但是一旦訓練好以後,模型會比較難overfitting,效果也會比較好。
對於RNN使用的這個結構,由於原生的RNN的這個結構本身無法解決長程依賴的問題,目前主要使用Lstm 和GRU來進行代替。但是具體到LSTM 和GRU,因為LSTM需要使用三個門結構也就是通常所說的遺忘門,更新門,輸出門。而GRU的表現和LSTM類似,卻只需要兩個門結構。訓練速度更快,對記憶體的佔用更小,目前看起來使用GRU是更好的選擇。
專案實戰
- 首先
git clone https://github.com/PaddlePaddle/models/tree/develop/generate_sequence_by_rnn_lm
到本地model 目錄下 - 程式碼結構如下
. ├── data │ └── train_data_examples.txt # 示例資料,可參考示例資料的格式,提供自己的資料 ├── config.py # 配置檔案,包括data、train、infer相關配置 ├── generate.py # 預測任務指令碼,即生成文字 ├── beam_search.py # beam search 演算法實現 ├── network_conf.py # 本例中涉及的各種網路結構均定義在此檔案中,希望進一步修改模型結構,請修改此檔案 ├── reader.py # 讀取資料介面 ├── README.md ├── train.py # 訓練任務指令碼 └── utils.py # 定義通用的函式,例如:構建字典、載入字典等
執行說明
- 首先執行python train.py 開始訓練模型,待模型訓練完畢以後。
- 執行python generate.py 開始執行文字生成程式碼。(預設的文字輸入為data/train_data_example.txt,生成文字儲存為data/gen_result.txt)
程式碼解析
- paddle 的使用有幾個固定需要遵守的流程。
- 大致需要4步。1:初始化,2:定義網路結構,3:訓練,4:預測。
- 其中定義網路結構具體需要定義 1:定義具體的網路結構,2:定義所需要的引數,3:定義優化的方法,4:定義event_handler 列印訓練資訊。
- 總體來說,paddle 的程式碼上手難度其實對新手挺大的,但思路非常的清晰,耐心閱讀應該可以明白。下面我們具體介紹:
1.首先需要載入paddle 進行初始化:
import paddle.v2 as paddle import numpy as np paddle.init(use_gpu=False)
2.定義網路結構
# 變數說明 # vocab_dim: 輸入變數的維度數. # type vocab_dim: int # emb_dim: embedding vector的維度數 # type emb_dim: int # rnn_type: RNN cell的型別. # type rnn_type: int # hidden_size: hidden unit的個數. # type hidden_size: int # stacked_rnn_num: 堆疊的rnn cell的個數. # type stacked_rnn_num: int
# 定義輸入層
input = paddle.layer.data(
name="input", type=paddle.data_type.integer_value_sequence(vocab_dim))
if not is_infer:
target = paddle.layer.data(
name="target",
type=paddle.data_type.integer_value_sequence(vocab_dim))
# 定義embedding層
# 該層將上層的輸出變數input 做為本層的輸入灌入embedding層,將輸入input 向量化,方便後續處理
input_emb = paddle.layer.embedding(input=input, size=emb_dim)
# 定義rnn層
# 如果 rnn_type 是lstm,則堆疊lstm層
# 如果rnn_type 是gru,則堆疊gru層
# 如果 i = 0的話,先將 input_emb做為輸入,其餘時刻則將上一時刻的rnn_cell作為輸入進行堆疊
# stack_rnn_num 等於多少就堆疊多少個 rnn層
if rnn_type == "lstm":
for i in range(stacked_rnn_num):
rnn_cell = paddle.networks.simple_lstm(
input=rnn_cell if i else input_emb, size=hidden_size)
elif rnn_type == "gru":
for i in range(stacked_rnn_num):
rnn_cell = paddle.networks.simple_gru(
input=rnn_cell if i else input_emb, size=hidden_size)
else:
raise Exception("rnn_type error!")
# 定義全聯接層
# 將上層最終定義得到的輸出rnn_cell 做為輸入灌入該全聯接層
output = paddle.layer.fc(
input=[rnn_cell], size=vocab_dim, act=paddle.activation.Softmax())
# 最後一層cost中記錄了神經網路的所有拓撲結構,通過組合不同的layer,我們即可完成神經網路的搭建。
cost = paddle.layer.classification_cost(input=output, label=target)
paddle的網路結構從這裡可以看出其實定義起來需要自己寫非常多的程式碼,感覺非常的冗餘,雖然同樣也是搭建積木自上而下一層層來寫,程式碼開發的工作量其實蠻大的。
3.訓練模型
在完成神經網路的搭建之後,我們首先需要根據神經網路結構來建立所需要優化的parameters(也就是網路結構的引數),並建立optimizer(求解網路結構引數的優化方法比如Sgd,Adam,Rmstrop)之後,我們可以建立trainer來對網路進行訓練。在這裡我們使用adam演算法來作為我們優化的演算法,L2正則項來作為正則項。並根據cost 中記錄的網路拓撲結構來建立神經網路所需要的引數。
# create optimizer
adam_optimizer = paddle.optimizer.Adam(
learning_rate=1e-3,
regularization=paddle.optimizer.L2Regularization(rate=1e-3),
model_average=paddle.optimizer.ModelAverage(
average_window=0.5, max_average_window=10000))
# create parameters
parameters = paddle.parameters.create(cost)
# create trainer
trainer = paddle.trainer.SGD(
cost=cost, parameters=parameters, update_equation=adam_optimizer)
其中,trainer接收三個引數,包括神經網路拓撲結構 cost、神經網路引數 parameters以及迭代方程 adam_optimizer。在搭建神經網路的過程中,我們僅僅對神經網路的輸入進行了描述。而trainer需要讀取訓練資料進行訓練,PaddlePaddle中通過reader來載入資料。
# define reader
reader_args = {
"file_name": conf.train_file,
"word_dict": word_dict,
}
# 讀取訓練資料
train_reader = paddle.batch(
paddle.reader.shuffle(
reader.rnn_reader(**reader_args), buf_size=102400),
batch_size=conf.batch_size)
# 讀取測試資料
test_reader = None
if os.path.exists(conf.test_file) and os.path.getsize(conf.test_file):
test_reader = paddle.batch(
paddle.reader.shuffle(
reader.rnn_reader(**reader_args), buf_size=65536),
batch_size=conf.batch_size)
最終我們可以呼叫trainer的train方法啟動訓練:
# define the event_handler callback
# event_handler 主要負責列印訓練的進度資訊,訓練的損失值,這裡可以自己定製
def event_handler(event):
if isinstance(event, paddle.event.EndIteration):
if not event.batch_id % conf.log_period:
logger.info("Pass %d, Batch %d, Cost %f, %s" % (
event.pass_id, event.batch_id, event.cost, event.metrics))
if (not event.batch_id %
conf.save_period_by_batches) and event.batch_id:
save_name = os.path.join(model_save_dir,
"rnn_lm_pass_%05d_batch_%03d.tar.gz" %
(event.pass_id, event.batch_id))
with gzip.open(save_name, "w") as f:
parameters.to_tar(f)
if isinstance(event, paddle.event.EndPass):
if test_reader is not None:
result = trainer.test(reader=test_reader)
logger.info("Test with Pass %d, %s" %
(event.pass_id, result.metrics))
save_name = os.path.join(model_save_dir, "rnn_lm_pass_%05d.tar.gz" %
(event.pass_id))
with gzip.open(save_name, "w") as f:
parameters.to_tar(f)
# 開始訓練
trainer.train(
reader=train_reader, event_handler=event_handler, num_passes=num_passes)
至此,我們的訓練程式碼定義結束,開始進行訓練
python train.py
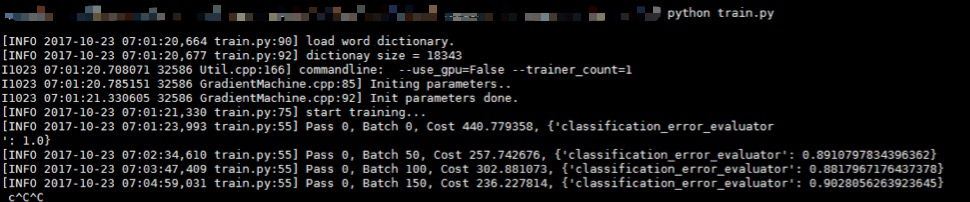
pass 相當於我們平常所使用的 epoch(即一次迭代), batch是我們每次訓練載入的輸入變數的個數,cost 是衡量我們的網路結構損失函式大小的具體值,越小越好,最後一項 classification_error_evaluator 是表明我們目前的分類誤差的損失率,也是越小越好。
4.生成文字
當等待若干時間以後,訓練完畢以後。開始進行文字生成。
python generate.py

生成文字展示
81 若隱若現 地像 幽靈 , 像 死神 -12.2542 一樣 。 他 是 個 怪物 <e> -12.6889 一樣 。 他 是 個 英雄 <e> -13.9877 一樣 。 他 是 我 的 敵人 <e> -14.2741 一樣 。 他 是 我 的 <e> -14.6250 一樣 。 他 是 我 的 朋友 <e>
其中:
- 第一行
81 若隱若現 地像 幽靈 , 像 死神以\t為分隔,共有兩列:- 第一列是輸入字首在訓練樣本集中的序號。
- 第二列是輸入的字首。
- 第二 ~
beam_size + 1行是生成結果,同樣以\t分隔為兩列:- 第一列是該生成序列的對數概率(log probability)。
- 第二列是生成的文字序列,正常的生成結果會以符號
<e>結尾,如果沒有以<e>結尾,意味著超過了最大序列長度,生成強制終止
總結:
我們這次說明了如何安裝paddle。如何使用paddle開始一段專案。總體來說paddle 的文件目前是非常的不規範,閱讀的體驗也不是很好,需要開發者耐心細緻的閱讀原始碼來掌握paddle的使用方法。第二很多層的封裝感覺寫法非常的冗餘,比如一定要用paddle作為字首,把python寫出了java的感覺。但是瑕不掩瑜,從使用的角度來看,一旦掌握了其使用方法以後,自己定義網路結構感覺非常的方便。訓練的速度也是挺快的。