
LibSVM支援向量迴歸詳解
LibSVM是是臺灣林智仁(Chih-Jen Lin)教授2001年開發的一套支援向量機的庫,可以很方便的對資料做分類或迴歸。由於LibSVM程式小,運用靈活,輸入引數少,並且是開源的,易於擴充套件,因此成為目前國內應用最多的SVM的庫,同時sklearn.svm也是使用的該庫。
網路上對於LibSVM原始碼的講解有很多,但個人感覺絕大多數講解的不夠清晰,很多都是貼個理論公式圖片再粘段程式碼就一帶而過。並且網路上基本都是對SVC的講解,SVR部分幾乎沒有提及(雖然SVR只是SVC的擴充套件)。因此本篇博文將系統地講解LibSVM中SVR訓練與預測部分的原始碼(想學習SVC的同學同樣適用)。
LibSVM整體流程
train:
//根據svm_type的不同進行初始化
svm_train()
//根據svm_type的不同調用不同的分類迴歸訓練函式
svm_train_one()
//針對epsilon-SVR這一型別進行模型引數初始化
solve_epsilon_svr()
//使用SMO演算法求解對偶問題(二次優化問題)
Solver::Solve()
//每隔若干次迭代進行一次shrinking,對樣本集進行縮減降低計算成本
Solver:: predict
//根據svm_type的不同開闢dec_value空間
svm_predict()
//根據svm_type的不同調用k_function函式
svm_predict_values()
//根據kernel_type的不同計算k(i,j)
Kernel::k_function()
//得到k(x_train[i],x_test[j])
//得到預測值y_pre[j]
//得到預測值y_pre[j]
svm.h檔案解析
svm_node
//儲存一個樣本(假設為樣本i)的一個特徵
struct svm_node{
int index; //樣本i的特徵索引值,最後一個為-1
double value; //樣本i第index個特徵的值,最後一個為NULL
};
如:x[i]={0.23,1.2,3.5,1.5}
則需使用五個svm_node來表示x[i],具體對映如下:
| index | 0 | 1 | 2 | 3 | -1 |
|---|---|---|---|---|---|
| value | 0.23 | 1.2 | 3.5 | 1.5 | NULL |
svm_problem
//儲存參加運算的所有樣本資料(訓練集)
struct svm_problem{
int l; //樣本總數
double *y; //樣本輸出值(所屬類別)
struct svm_node **x; //樣本輸入值
};
下圖中最右邊的長條格同上表,儲存了三維資料。
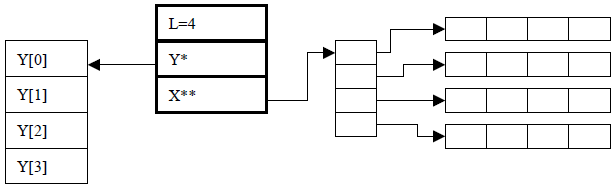
**svm_problem中的y與類Solver中的y並不完全一樣!!!**對於一般SVC而言可以看出一樣的,其值為-1與+1,對於多分類而言svm_problem.y[i]可以是1、2、3等,而多類計算其實是二分類的組合,因此在二分類中y[i]依然等於+1與-1.更特殊的,在SVR中,svm_problem的y[i]等於其目標值,如:11.234、56.24、5.23等,在計算時svm_problem.y[i]整合到了Solver.p[i]與Solver.p[i+svm_problem.l]中(具體的問題後續章節再詳細解釋),而在Solver.y[i]依然為+1和-1.
svm_parameter
//svm_type和svm_type可能取值
enum { C\_SVC, NU\_SVC, ONE\_CLASS, EPSILON\_SVR, NU\_SVR };/* svm_type */
enum { LINEAR, POLY, RBF, SIGMOID }; /* kernel_type */
//svm模型訓練引數
struct svm_parameter
{
int svm_type;
int kernel_type;
int degree; /* for poly */
double gamma; /* for poly/rbf/sigmoid */
double coef0; /* for poly/sigmoid */
/* these are for training only */
double cache_size; /* in MB */
double eps; /* stopping criteria */
double C; /* for C_SVC, EPSILON_SVR and NU_SVR */
int nr_weight; /* for C_SVC */
int *weight_label; /* for C_SVC */
double* weight; /* for C_SVC */
double nu; /* for NU_SVC, ONE_CLASS, and NU_SVR */
double p; /* for EPSILON_SVR */
int shrinking; /* use the shrinking heuristics */
int probability; /* do probability estimates */
};
LibSVM中的核函式如下:
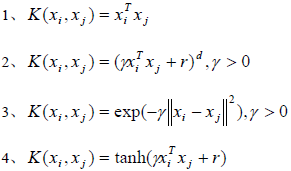
各引數解釋如下:
| Parameter | Interpretation |
|---|---|
| degree | 2式中的d |
| gamma | 2,3,4式中的gamma |
| coef0 | 2,4式中的r |
| cache_size | 單位MB,訓練所需記憶體,LibSVM2.5預設4M |
| eps | 停止條件需滿足的最大誤差值(文獻[2]中式3.9) |
| C | 懲罰因子,越大模型過擬合越嚴重 |
| nr_weight | 權重的數目,目前在例項程式碼中只有兩個值,一個是預設0,另外一個是svm_binary_svc_probability函式中使用數值2 |
| *weight_label | 權重,元素個數由nr_weight決定. |
| nu | NU_SVC,ONE_CLASS,NU_SVR中的nu |
| p | SVR中的間隔帶epsilon |
| shrinking | 指明訓練過程是否使用壓縮 |
| probability | 指明是否做概率估計 |
svm_model
//儲存訓練後的模型引數
struct svm_model{
struct svm_parameter param; /* parameter */
int nr_class; /* number of classes, = 2 in regression/one class svm */
int l; /* total #SV */
struct svm_node **SV; /* SVs (SV[l]) */
double **sv_coef; /* coefficients for SVs in decision functions (sv_coef[k-1][l]) */
double *rho; /* constants in decision functions (rho[k*(k-1)/2]) */
double *probA; /* pariwise probability information */
double *probB;
int *sv_indices; /* sv_indices[0,...,nSV-1] are values in [1,...,num_traning_data] to indicate SVs in the training set */
/* for classification only */
int *label; /* label of each class (label[k]) */
int *nSV; /* number of SVs for each class (nSV[k]) */
/* nSV[0] + nSV[1] + ... + nSV[k-1] = l */
/* XXX */
int free_sv; /* 1 if svm_model is created by svm_load_model*/
/* 0 if svm_model is created by svm_train */
};
各引數解釋如下:
| Parameter | Interpretation |
|---|---|
| param | 訓練引數 |
| nr_class | 類別數 |
| l | 支援向量數 |
| **SV | 作為支援向量的樣本集 |
| **sv_coef | 支援向量係數alpha |
| *rho | 判別函式中的b |
| *proA | 成對概率資訊 |
| *proB | 成對概率資訊 |
| *sv_indices | 記錄支援向量在訓練資料中的index |
| *label | 各類的標籤 |
| *nSV | 各類的支援向量數 |
| free_SV | 若model由svm_load_model函式生成則為1,若為svm_train生成則為0 |
svm.cpp檔案解析
下圖為svm.cpp中的類繼承和組合情況(實現表示繼承關係,虛線表示組合關係):
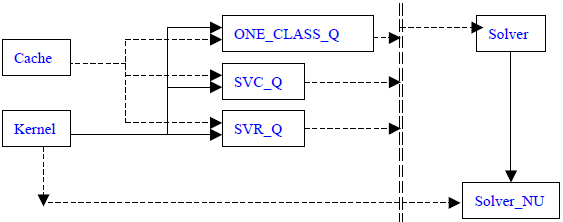
Cache類主要負責運算所涉及的記憶體的管理,包括申請、釋放等。本篇博文主要講解SVM求解過程,對於Cache類將不予解析。
Kernel類
class Kernel : public QMatrix {
public:
Kernel(int l, svm_node * const * x, const svm_parameter& param);
virtual ~Kernel();
static double k_function(const svm_node *x, const svm_node *y,
const svm_parameter& param);
virtual Qfloat *get_Q(int column, int len) const = 0;
virtual double *get_QD() const = 0;
virtual void swap_index(int i, int j) const // no so const...
{
swap(x[i], x[j]);
if (x_square) swap(x_square[i], x_square[j]);
}
protected:
double (Kernel::*kernel_function)(int i, int j) const;
private:
const svm_node **x;
double *x_square;
// svm_parameter
const int kernel_type;
const int degree;
const double gamma;
const double coef0;
static double dot(const svm_node *px, const svm_node *py);
double kernel_linear(int i, int j) const
{
return dot(x[i], x[j]);
}
double kernel_poly(int i, int j) const
{
return powi(gamma*dot(x[i], x[j]) + coef0, degree);
}
double kernel_rbf(int i, int j) const
{
return exp(-gamma * (x_square[i] + x_square[j] - 2 * dot(x[i], x[j])));
}
double kernel_sigmoid(int i, int j) const
{
return tanh(gamma*dot(x[i], x[j]) + coef0);
}
double kernel_precomputed(int i, int j) const
{
return x[i][(int)(x[j][0].value)].value;
}
};
成員變數
| Parameter | Interpretation |
|---|---|
| svm_node **x | 訓練樣本資料 |
| *x_square | x[i]^T*x[i],使用RBF核會用到 |
| kernel_type | 核函式型別 |
| degree | svm_parameter |
| gamma | svm_parameter |
| coef0 | svm_parameter |
成員函式
Kernel(int l, svm_node * const * x, const svm_parameter& param);
建構函式。初始化類中的部分常量、指定核函式、克隆樣本資料。
Kernel::Kernel(int l, svm_node * const * x_, const svm_parameter& param)
:kernel_type(param.kernel_type), degree(param.degree),
gamma(param.gamma), coef0(param.coef0)
{
switch (kernel_type) //根據kernel_type的不同定義相應的函式kernel_function()
{
case LINEAR:
kernel_function = &Kernel::kernel_linear;
break;
case POLY:
kernel_function = &Kernel::kernel_poly;
break;
case RBF:
kernel_function = &Kernel::kernel_rbf;
break;
case SIGMOID:
kernel_function = &Kernel::kernel_sigmoid;
break;
case PRECOMPUTED:
kernel_function = &Kernel::kernel_precomputed;
break;
}
clone(x, x_, l);
if (kernel_type == RBF) //如果使用RBF 核函式,則計算x_sqare[i],即x[i]^T*x[i]
{
x_square = new double[l];
for (int i = 0; i<l; i++)
x_square[i] = dot(x[i], x[i]);
}
else
x_square = 0;
}
static double dot(const svm_node *px, const svm_node *py);
點乘函式,點乘兩個樣本資料,按svm_node 中index (一般為特徵)進行運算,一般來說,index為1,2,…直到-1。返回點乘總和。例如:x1={1,2,3} ,x2={4,5,6}總和為sum=1*4+2*5+3*6;在svm_node[3]中儲存index=-1時,停止計算。
double Kernel::dot(const svm_node *px, const svm_node *py)
{
double sum = 0;
while (px->index != -1 && py->index != -1)
{
if (px->index == py->index)
{
sum += px->value * py->value;
++px;
++py;
}
else
{
if (px->index > py->index)
++py;
else
++px;
}
}
return sum;
}
static double k_function(const svm_node *x, const svm_node *y, const svm_parameter& param);
功能類似kernel_function,不過kerel_function用於訓練,k_function用於預測。
double Kernel::k_function(const svm_node *x, const svm_node *y,
const svm_parameter& param) //輸入資料為兩個資料樣本,其中一個為訓練樣本一個為測試樣本
{
switch (param.kernel_type)
{
case LINEAR:
return dot(x, y);
case POLY:
return powi(param.gamma*dot(x, y) + param.coef0, param.degree);
case RBF:
{
double sum = 0;
while (x->index != -1 && y->index != -1)
{
if (x->index == y->index)
{
double d = x->value - y->value;
sum += d * d;
++x;
++y;
}
else
{
if (x->index > y->index)
{
sum += y->value * y->value;
++y;
}
else
{
sum += x->value * x->value;
++x;
}
}
}
while (x->index != -1)
{
sum += x->value * x->value;
++x;
}
while (y->index != -1)
{
sum += y->value * y->value;
++y;
}
return exp(-param.gamma*sum);
}
case SIGMOID:
return tanh(param.gamma*dot(x, y) + param.coef0);
case PRECOMPUTED: //x: test (validation), y: SV
return x[(int)(y->value)].value;
default:
return 0; // Unreachable
}
}
其中RBF部分很有講究。因為儲存時,0值不保留。如果所有0值都保留,第一個while就可以都做完了;如果第一個while做不完,在x,y中任意一個出現index=-1,第一個while就停止,剩下的程式碼中兩個while只會有一個工作,該迴圈直接把剩下的計算做完。
virtual Qfloat *get_Q(int column, int len);
純虛擬函式,將來在子類中實現(如class SVR_Q),計算Q值。相當重要的函式。
virtual Qfloat *get_Q(int column, int len) const = 0;
virtual void swap_index(int i, int j);
虛擬函式,x[i]和x[j]中所儲存指標的內容。如果x_square不為空,則交換相應的內容。
virtual void swap_index(int i, int j) const // no so const...
{
swap(x[i], x[j]);
if (x_square) swap(x_square[i], x_square[j]);
}
virtual double *get_QD();
純虛擬函式,將來在子類中實現(如class SVR_Q),計算Q[i,i]值。
virtual Qfloat *get_Q(int column, int len) const = 0;
double (Kernel::*kernel_function)(int i, int j);
函式指標,根據相應的核函式型別,來決定所使用的函式。在計算矩陣Q時使用。
double (Kernel::*kernel_function)(int i, int j) const;
Solver類
class Solver {
public:
Solver() {};
virtual ~Solver() {};
struct SolutionInfo {
double obj;
double rho;
double upper_bound_p;
double upper_bound_n;
double r; // for Solver_NU
};
void Solve(int l, const QMatrix& Q, const double *p_, const schar *y_,
double *alpha_, double Cp, double Cn, double eps,
SolutionInfo* si, int shrinking);
protected:
int active_size;
schar *y;
double *G; // gradient of objective function
enum { LOWER_BOUND, UPPER_BOUND, FREE };
char *alpha_status; // LOWER_BOUND, UPPER_BOUND, FREE
double *alpha;
const QMatrix *Q;
const double *QD;
double eps;
double Cp, Cn;
double *p;
int *active_set;
double *G_bar; // gradient, if we treat free variables as 0
int l;
bool unshrink; // XXX
double get_C(int i)
{
return (y[i] > 0) ? Cp : Cn;
}
void update_alpha_status(int i)
{
if (alpha[i] >= get_C(i))
alpha_status[i] = UPPER_BOUND;
else if (alpha[i] <= 0)
alpha_status[i] = LOWER_BOUND;
else alpha_status[i] = FREE;
}
bool is_upper_bound(int i) { return alpha_status[i] == UPPER_BOUND; }
bool is_lower_bound(int i) { return alpha_status[i] == LOWER_BOUND; }
bool is_free(int i) { return alpha_status[i] == FREE; }
void swap_index(int i, int j);
void reconstruct_gradient();
virtual int select_working_set(int &i, int &j);
virtual double calculate_rho();
virtual void do_shrinking();
private:
bool be_shrunk(int i, double Gmax1, double Gmax2);
};
成員變數
結構體SolutionInfo為求解優化中的引數資訊。
各引數解釋如下:
| Parameter | Interpretation |
|---|---|
| SolutionInfo.obj | 求解優化過程中的目標函式值 |
| SolutionInfo.rho | 判別函式中的b |
| SolutionInfo.upper_bound_p | 對於不平衡資料集,該值對應懲罰因子Cp |
| SolutionInfo.upper_bound_n | 對於不平衡資料集,該值對應懲罰因子Cn |
| SolutionInfo.r | 用於Solver_NU |
| active_size | 計算時實際參加運算的樣本數目,經過shrink處理後,該數目會小於全部樣本總數。 |
| *y | 樣本所屬類別,該值只取+1/-1 。雖然可以處理多類,最終是用兩類SVM 完成的。 |
| *G | 梯度G=Qα+P |
| *alpha_status | α[i]的狀態,根據情況分為α[i]≤0,α[i]≥c和0<α[i]<\c,分別對應內部點(非SV),錯分點(BSV)和支援向量(SV)。 |
| *alpha | α[i] |
| *Q | 對應公式中Q的某一列 |
| *QD | 對應公式中的Q[i][i] |
| eps | 停止條件的誤差限 |
| Cp,Cn | 對應不平衡資料的 |