
Flink 基本工作原理
Flink是新的stream計算引擎,用java實現。既可以處理stream data也可以處理batch data,可以同時兼顧Spark以及Spark streaming的功能,與Spark不同的是,Flink本質上只有stream的概念,batch被認為是special stream。Flink在執行中主要有三個元件組成,JobClient,JobManager 和 TaskManager。主要工作原理如下圖
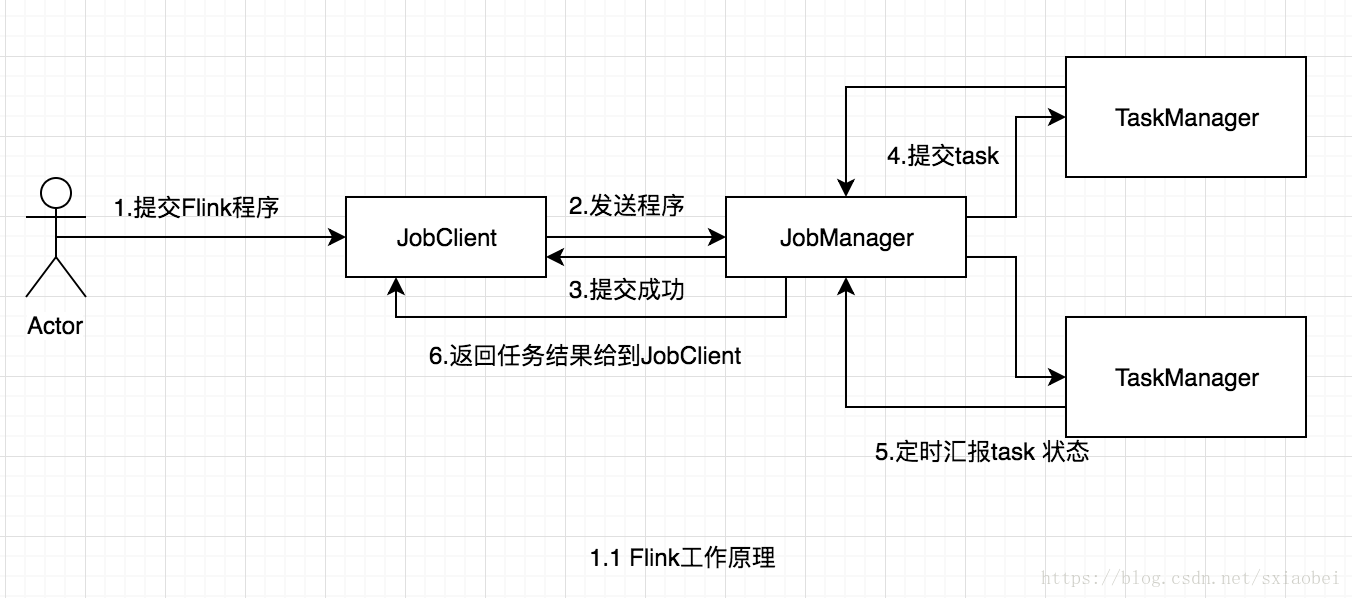
使用者首先提交Flink程式到JobClient,經過JobClient的處理、解析、優化提交到JobManager,最後由TaskManager執行task。
JobClient
JobClient是Flink程式和JobManager互動的橋樑,主要負責接收程式、解析程式的執行計劃、優化程式的執行計劃,然後提交執行計劃到JobManager。為了瞭解Flink的解析過程,需要簡單介紹一下Flink的Operator,在Flink主要有三類Operator,
- Source Operator ,顧名思義這類操作一般是資料來源操作,比如檔案、socket、kafka等,一般存在於程式的最開始
- Transformation Operator 這類操作主要負責資料轉換,map,flatMap,reduce等運算元都屬於Transformation Operator,
- Sink Operator,意思是下沉操作,這類操作一般是資料落地,資料儲存的過程,放在Job最後,比如資料落地到Hdfs、Mysql、Kafka等等。
DataStream<String> data = env.addSource(...);
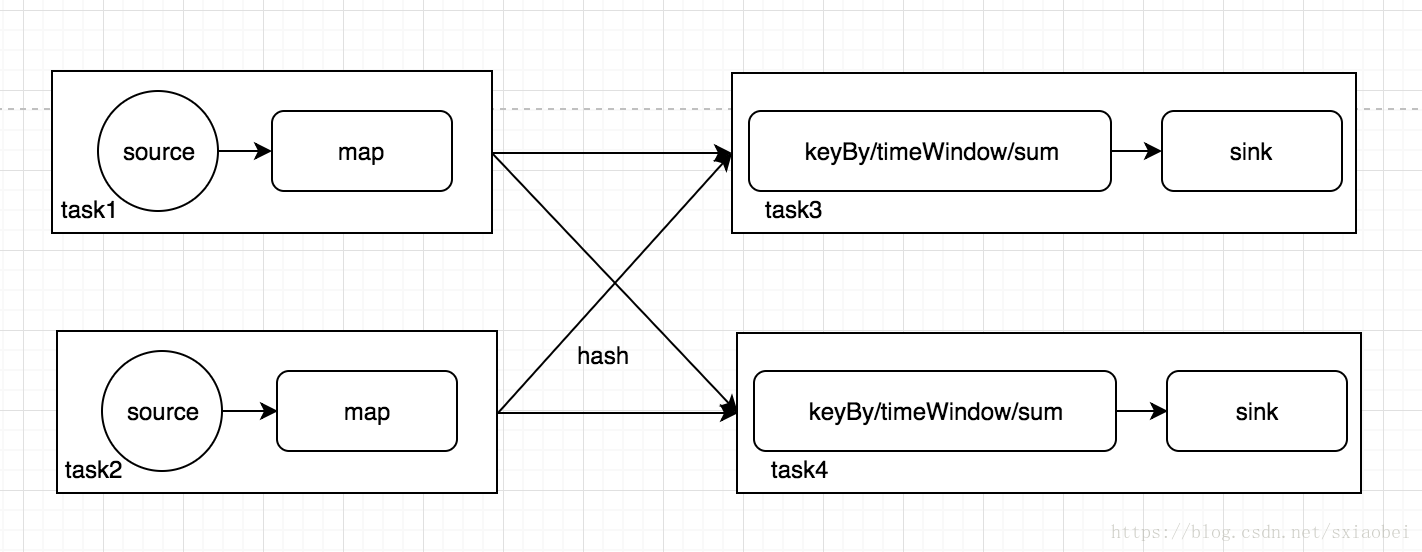
data.map(x->new Tuple2(x,1)).keyBy(0).timeWindow(Time.seconds(60)).sum(1).addSink(...)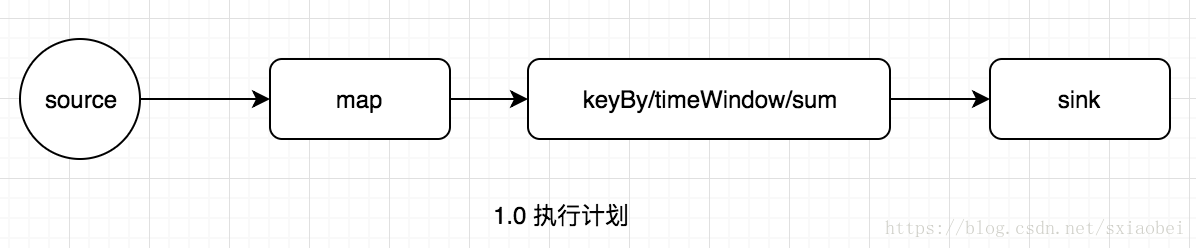 解析形成執行計劃之後,JobClient的任務還沒有完,還負責執行計劃的優化,這裡執行的主要優化是將相鄰的Operator融合,形成OperatorChain,因為Flink是分散式執行的,程式中每一個運算元,在實際執行中被分隔為多個SubTask,資料流在運算元之間的流動,就對應到SubTask之間的資料傳遞,SubTask之間進行資料傳遞模式有兩種一種是one-to-one的,資料不需要重新分佈,也就是資料不需要經過IO,節點本地就能完成,比如上圖中的source到map,一種是re-distributed,資料需要通過shuffle過程重新分割槽,需要經過IO,比如上圖中的map到keyBy。顯然re-distributed這種模式更加浪費時間,同時影響整個Job的效能。所以,Flink為了提高效能,將one-to-one關係的前後兩類subtask,融合形成一個task。而TaskManager中一個task執行一個獨立的執行緒中,同一個執行緒中的SubTask進行資料傳遞,不需要經過IO,不需要經過序列化,直接傳送資料物件到下一個SubTask,效能得到提升,除此之外,subTask的融合可以減少task的數量,提高taskManager的資源利用率。圖1.0中的執行計劃,優化結果如下圖,Flink的subTask融合規則可以參考官方文件。
解析形成執行計劃之後,JobClient的任務還沒有完,還負責執行計劃的優化,這裡執行的主要優化是將相鄰的Operator融合,形成OperatorChain,因為Flink是分散式執行的,程式中每一個運算元,在實際執行中被分隔為多個SubTask,資料流在運算元之間的流動,就對應到SubTask之間的資料傳遞,SubTask之間進行資料傳遞模式有兩種一種是one-to-one的,資料不需要重新分佈,也就是資料不需要經過IO,節點本地就能完成,比如上圖中的source到map,一種是re-distributed,資料需要通過shuffle過程重新分割槽,需要經過IO,比如上圖中的map到keyBy。顯然re-distributed這種模式更加浪費時間,同時影響整個Job的效能。所以,Flink為了提高效能,將one-to-one關係的前後兩類subtask,融合形成一個task。而TaskManager中一個task執行一個獨立的執行緒中,同一個執行緒中的SubTask進行資料傳遞,不需要經過IO,不需要經過序列化,直接傳送資料物件到下一個SubTask,效能得到提升,除此之外,subTask的融合可以減少task的數量,提高taskManager的資源利用率。圖1.0中的執行計劃,優化結果如下圖,Flink的subTask融合規則可以參考官方文件。- 值得注意的是,並不是每一個SubTask都可以被融合,對於不能融合的SubTask會獨立形成一個Task執行在TaskManager中。
- 改變operator的並行度,可能會導致不同的優化結果,同時這也是效能調優的一個重要方式,例如不顯式設定operator的並行度的時候,預設所有運算元的並行度是一樣的,所以會有下圖中的優化結果。
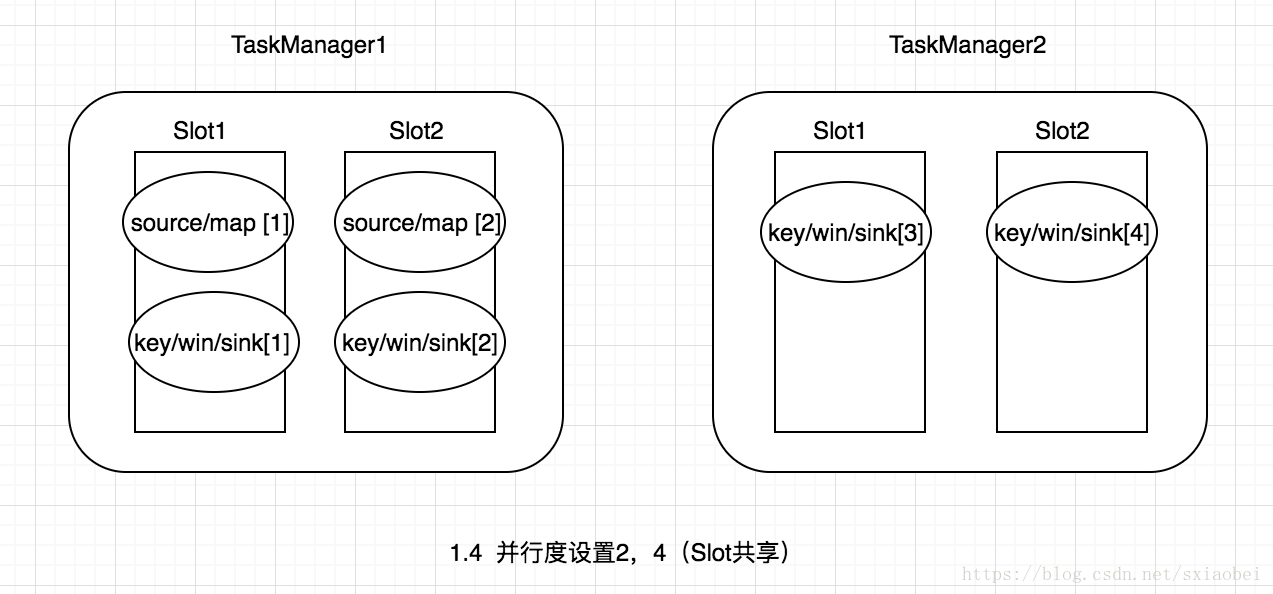
 我們來分析一下預設情況下可能發生的問題,假如設定作業的並行度為10,source明確為kafka,對應topic只有一個topic,因為source預設會根據topic的分割槽數,決定自己的分割槽數,那麼10個source subtask只有一個會工作,而且任務比較重。這樣會導致後面的map實際也是有一個subTask在工作,處理所有的資料,假如map中的任務比較重,那麼會導致資料傾斜,效能低下。在source不能改造的情況下,我們顯式減少source的並行度(為了節省資源,設定1),提高map的並行度(增加處理速度,設為20)。第一眼看上去,感覺效能提升了不少,但是在實際情況中卻不一定這樣。因為調整source和map的併發度,失去了原有one-to-one資料傳遞的優勢,導致subTask不能融合,資料需要reblance,產生大量的IO,所以修改並行度也不一定可以提升效能。修改並行度之後,執行計劃的優化結果如下圖。所以在實際優化的過程中,還是要注意結合資料分佈和執行計劃調優,理解Flink執行計劃的生成過程很有必要。
我們來分析一下預設情況下可能發生的問題,假如設定作業的並行度為10,source明確為kafka,對應topic只有一個topic,因為source預設會根據topic的分割槽數,決定自己的分割槽數,那麼10個source subtask只有一個會工作,而且任務比較重。這樣會導致後面的map實際也是有一個subTask在工作,處理所有的資料,假如map中的任務比較重,那麼會導致資料傾斜,效能低下。在source不能改造的情況下,我們顯式減少source的並行度(為了節省資源,設定1),提高map的並行度(增加處理速度,設為20)。第一眼看上去,感覺效能提升了不少,但是在實際情況中卻不一定這樣。因為調整source和map的併發度,失去了原有one-to-one資料傳遞的優勢,導致subTask不能融合,資料需要reblance,產生大量的IO,所以修改並行度也不一定可以提升效能。修改並行度之後,執行計劃的優化結果如下圖。所以在實際優化的過程中,還是要注意結合資料分佈和執行計劃調優,理解Flink執行計劃的生成過程很有必要。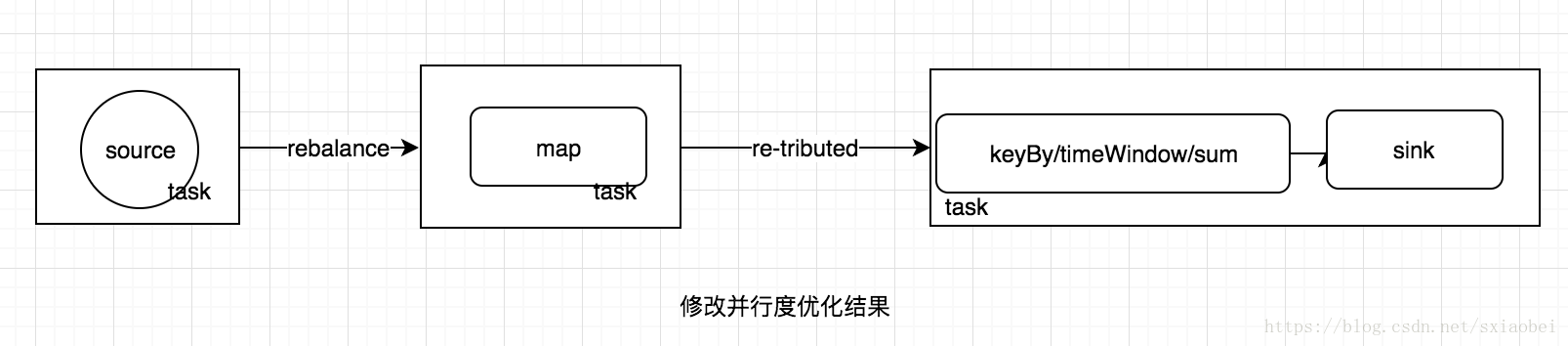
JobManager
JobManager是一個程序,主要負責申請資源,協調以及控制整個job的執行過程,具體包括,排程任務、處理checkpoint、容錯等等,在接收到JobClient提交的執行計劃之後,針對收到的執行計劃,繼續解析,因為JobClient只是形成一個operaor層面的執行計劃,所以JobManager繼續解析執行計劃(根據運算元的併發度,劃分task),形成一個可以被實際排程的由task組成的拓撲圖,如上圖被解析之後形成下圖的執行計劃,最後向叢集申請資源,一旦資源就緒,就排程task到TaskManager。
為了保證高可用,一般會有多個JobManager程序同時存在,它們之間也是採用主從模式,一個程序被選舉為Leader,其他程序為follower。Job執行期間,只有Leader在工作,follower在閒置,一旦Leader掛掉,隨即引發一次選舉,產生新的Leader繼續處理Job。JobManager除了排程任務,另外一個主要工作就是容錯,主要依靠checkpoint進行容錯,checkpoint其實是stream以及executor(TaskManager中的Slot)的快照,一般將checkpoint儲存在可靠的儲存中(比如hdfs),為了容錯Flink會持續建立這類快照。當Flink作業重新啟動的時候,會尋找最新可用的checkpoint來恢復執行狀態,已達到資料不丟失,不重複,準確被處理一次的語義。一般情況下,都不會用到checkpoint,只有在資料需要積累或處理歷史狀態的時候,才需要設定checkpoint,比如updateStateByKey這個運算元,預設會啟用checkpoint,如果沒有配置checkpoint目錄的話,程式會拋異常。
TaskManager
TaskManager是一個程序,及一個JVM(Flink用java實現)。主要作用是接收並執行JobManager傳送的task,並且與JobManager通訊,反饋任務狀態資訊,比如任務分執行中,執行完等狀態,上文提到的checkpoint的部分資訊也是TaskManager反饋給JobManager的。如果說JobManager是master的話,那麼TaskManager就是worker主要用來執行任務。在TaskManager內可以執行多個task。多個task執行在一個JVM內有幾個好處,首先task可以通過多路複用的方式TCP連線,其次task可以共享節點之間的心跳資訊,減少了網路傳輸。TaskManager並不是最細粒度的概念,每個TaskManager像一個容器一樣,包含一個多或多個Slot,如圖1.2。
Slot是TaskManager資源粒度的劃分,每個Slot都有自己獨立的記憶體。所有Slot平均分配TaskManger的記憶體,比如TaskManager分配給Solt的記憶體為8G,兩個Slot,每個Slot的記憶體為4G,四個Slot,每個Slot的記憶體為2G,值得注意的是,Slot僅劃分記憶體,不涉及cpu的劃分。同時Slot是Flink中的任務執行器(類似Storm中Executor),每個Slot可以執行多個task,而且一個task會以單獨的執行緒來執行。Slot主要的好處有以下幾點:
- 可以起到隔離記憶體的作用,防止多個不同job的task競爭記憶體。
- Slot的個數就代表了一個Flink程式的最高並行度,簡化了效能調優的過程
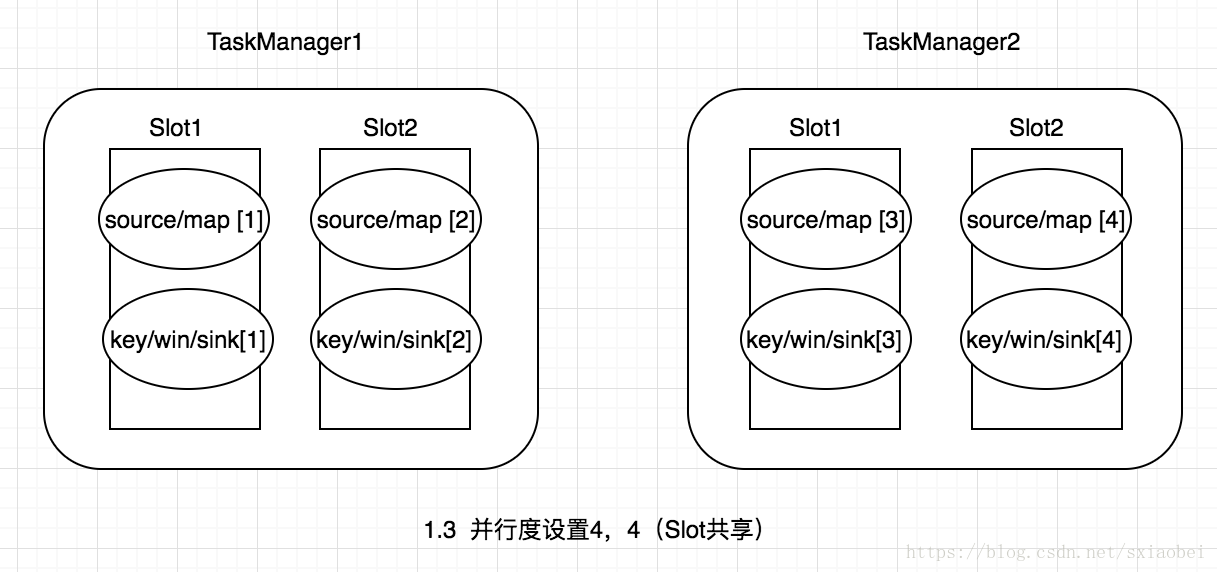
- 允許多個Task共享Slot,提升了資源利用率,舉一個實際的例子,kafka有3個partition,對應flink的source有3個task,而keyBy我們設定的並行度為20,這個時候如果Slot不能共享的話,需要佔用23個Slot,如果允許共享的話,那麼只需要20個Slot即可(Slot的預設共享規則計算為20個)。
- 同一個job中,同一個group中不同operator的task可以共享一個Slot
- Flink是按照拓撲順序從Source依次排程到Sink的
總結
上述內容,主要介紹了,Flink的基本架構以及Flink執行的基本原理,重點說明了Flink實現高效能的一些基本原理,因為寫的比較匆忙,如有錯誤之處,歡迎大家評論指正。
參考資料
- https://ci.apache.org/projects/flink/flink-docs-master/internals/job_scheduling.html?spm=a2c4e.11153940.blogcont64819.14.4cc928ce5F2w98
- https://ci.apache.org/projects/flink/flink-docs-master/concepts/programming-model.html
- https://yq.aliyun.com/articles/64819
- https://blog.csdn.net/lisi1129/article/details/54844919
- Learning Apache Flink