
《機器學習實戰》AdaBoost方法的演算法原理與程式實現
一、引言
提升(boosting)方法是一種常用的統計學習方法,應用廣泛且有效,在分類問題中,它通過改變訓練樣本的權重,學習多個分類器,並將這些分類器進行線性組合,提高分類的效能。
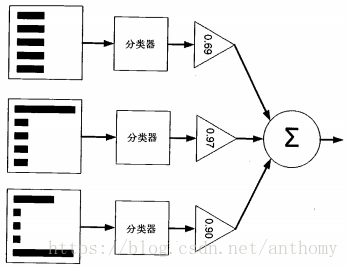
對於分類問題,給定一個訓練樣本集,比較粗糙的分類規則(弱分類器),要比精確分類規則(強分類器)容易,提升方法就是從弱學習演算法出發,反覆學習,得到一系列弱分類器,然後組合這些弱分類器,構成一個強分類器,大多數提升方法都是改變訓練資料的概率分佈(訓練資料的權值分佈),AdaBoost的做法是,提高那些被前一輪分類器錯誤分類的樣本的權值,而降低那些被正確分類樣本的權值,這樣那些沒有得到正確分類的資料,由於權值加大而受到後一輪弱分類器更大的關注。AdaBoost關於如何將弱分類器組合成一個強分類器,採用加權多數表決的方法,具體地,加大分類誤差率小的弱分類器的權值,使其在表決中起較大的作用,減小分類誤差率大的弱分類器的權值,使其在表決中起較小的作用。
二、AdaBoost演算法原理
假設給定一個二分類的訓練資料集:
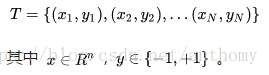
X是例項空間,y是標籤集合。
<1>初始化訓練資料的權值分佈
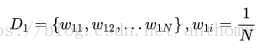
假設訓練資料具有均勻的權值分佈,即每個訓練樣本在基本分類器的學習中作用相同,這一假設保證第一步能夠保證這一步能夠在原始資料上學習基本分類器Gi(x)
<2>對m=1,2,...,M
AdaBoost反覆學習基本分類器,在每一輪m=1,2,...,M順次地執行下列操作:
a>使用具有權值分佈Dm的訓練資料集學習,得到基本(弱)分類器
Gm(x):X->{-1,1}
b>計算Gm(x)在訓練資料集上的分類誤差率
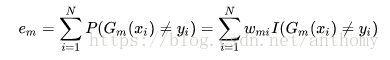
Wmi表示第m輪中第i個例項的權值,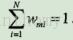
由此可以得到資料權值分佈Dm與基本分類器Gm(x)的分類誤差率的關係
c>計算Gm(x)的係數
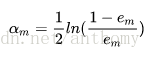
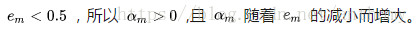
所以分類誤差越小的基本分類器在最終的分類器的作用越大。
d>更新訓練資料集的權值分佈
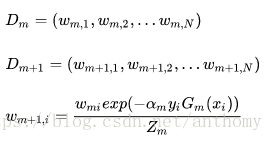
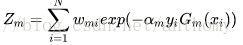
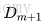
結果使得被基本分類器Gm(x)誤分類樣本的權值得以擴大,而被正確分類樣本的權值得以縮小,兩相比較,誤分類樣本的權值被放大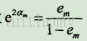
<3>構建基本分類器的線性組合
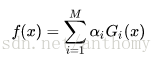
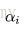
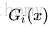
得到最終的分類器
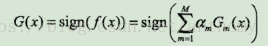
線性組合f(x)實現M個基本分類器的加權表決,係數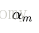
三、程式除錯
1.基於單層決策樹構建弱分類器的程式碼
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):#just classify the data
retArray = ones((shape(dataMatrix)[0],1))
if threshIneq == 'lt':
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0
return retArray
def buildStump(dataArr,classLabels,D):
dataMatrix = mat(dataArr); labelMat = mat(classLabels).T
m,n = shape(dataMatrix)
numSteps = 10.0; bestStump = {}; bestClasEst = mat(zeros((m,1)))
minError = inf #init error sum, to +infinity
for i in range(n):#loop over all dimensions
rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max();
stepSize = (rangeMax-rangeMin)/numSteps
for j in range(-1,int(numSteps)+1):#loop over all range in current dimension
for inequal in ['lt', 'gt']: #go over less than and greater than
threshVal = (rangeMin + float(j) * stepSize)
predictedVals = stumpClassify(dataMatrix,i,threshVal,inequal)#call stump classify with i, j, lessThan
errArr = mat(ones((m,1)))
errArr[predictedVals == labelMat] = 0
weightedError = D.T*errArr #calc total error multiplied by D
#print "split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError)
if weightedError < minError:
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump,minError,bestClasEst
2.完整Adaboost演算法的實現
過程:每次迭代中
利用buildStump函式找到最佳的單層決策樹
將最佳單層決策樹加入到單層決策樹組
計算alpha,新的權重向量D
更新累計類別估計值
如果錯誤率等0,則退出迴圈
2.1基於單層決策樹的adaboost訓練演算法
def adaBoostTrainDS(dataArr,classLabels,numIt=40):
weakClassArr = []
m = shape(dataArr)[0]
D = mat(ones((m,1))/m) #init D to all equal
aggClassEst = mat(zeros((m,1)))
for i in range(numIt):
bestStump,error,classEst = buildStump(dataArr,classLabels,D)#build Stump
#print "D:",D.T
alpha = float(0.5*log((1.0-error)/max(error,1e-16)))#calc alpha, throw in max(error,eps) to account for error=0
bestStump['alpha'] = alpha
weakClassArr.append(bestStump) #store Stump Params in Array
#print "classEst: ",classEst.T
expon = multiply(-1*alpha*mat(classLabels).T,classEst) #exponent for D calc, getting messy
D = multiply(D,exp(expon)) #Calc New D for next iteration
D = D/D.sum()
#calc training error of all classifiers, if this is 0 quit for loop early (use break)
aggClassEst += alpha*classEst
#print "aggClassEst: ",aggClassEst.T
aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T,ones((m,1)))
errorRate = aggErrors.sum()/m
print ('total error: ',errorRate)
if errorRate == 0.0: break
return weakClassArr,aggClassEst
2.2AdaBoost分類函式演算法
def adaClassify(datToClass,classifierArr):
dataMatrix = mat(datToClass)#do stuff similar to last aggClassEst in adaBoostTrainDS
m = shape(dataMatrix)[0]
aggClassEst = mat(zeros((m,1)))
for i in range(len(classifierArr)):
classEst = stumpClassify(dataMatrix,classifierArr[i]['dim'],\
classifierArr[i]['thresh'],\
classifierArr[i]['ineq'])#call stump classify
aggClassEst += classifierArr[i]['alpha']*classEst
print(aggClassEst)
return sign(aggClassEst)
2.3應用IRIS資料集進行測試
2.3.1資料預處理
選擇兩種花的資料,Iris-setosa 和Iris-versicolor ,並將標籤替換為1和-1;

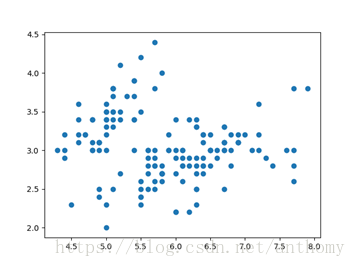
2.3.2資料視覺化
花萼長度、花萼寬度資料構建的散點圖
2.3.3 訓練資料測試

因為訓練使用的資料量相對較少(50條),錯誤率為0。
2.3.4測試資料測試和ROC曲線

2.4應用Titanic資料集進行測試
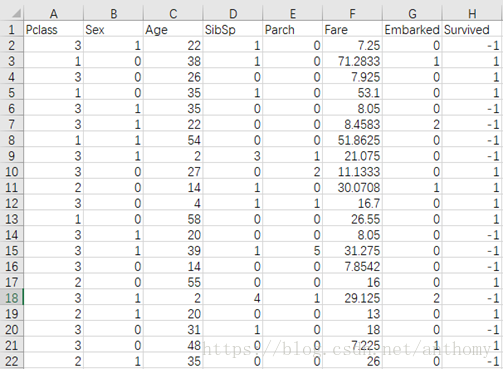
2.4.1 資料預處理
刪除Passenger屬性、Name屬性、Ticket屬性,因為對分類結果並不具有直接的關係。
對性別屬性,male替換為1,female替換為0;
年齡屬性中有很多缺失值,用最大值和最小值中的隨機值進行填充;
Embark屬性中的S、C、Q對應用0、1、2進行替換;
Survive屬性(標籤)1/0 按照演算法要求處理為1/-1;
處理結果如下圖
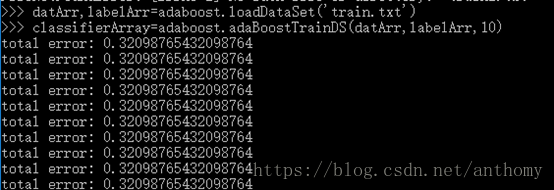
2.4.2 訓練資料測試
10個基本分類器(單層決策樹)
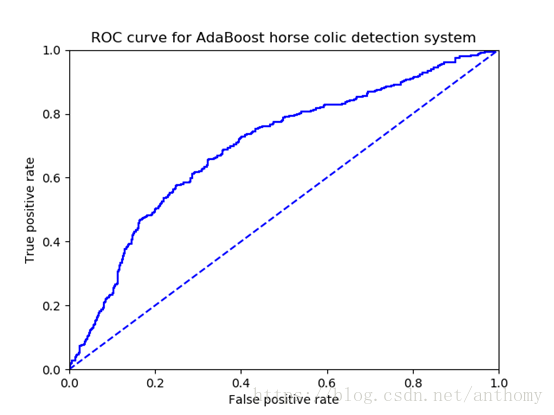
2.4.3 ROC曲線
四、總結與體會
Adaboost方法是個非常強大學習方法,通過各個基本分類器的線性組合來達到更好的分類效果,而在每次迭代中只改變錯誤樣本所佔的權值,是個非常高效且使用的演算法。
時間有限,並沒有找到一些有趣的、更實用的資料集,IRIS資料相對來說比較成熟,簡單,錯誤率低也是可以理解,過段時間會繼續尋找一些資料集來進行測試,本片文章也會一直更新。
五、參考文獻
【1】Python的替換函式——strip(),replace()和re.sub()
https://blog.csdn.net/zcmlimi/article/details/47709049
【2】《機器學習實戰》
【3】《統計學習方法》
非常感謝閱讀!如有不足之處,請留下您的評價和問題。