
hadoop完全分散式搭建HA(高可用)
首先建立5臺虛擬機器(最少三臺),並且做好部署規劃
ip地址 | 主機名 | 安裝軟體 | 程序 |
192.168.xx.120 | master | jdk,hadoop,zookeeper | namenode,ZKFC,Resourcemanager |
192.168.xx.121 | master2 | jdk,hadoop,zookeeper | namenode,ZKFC,Resourcemanager |
192.168.xx.122 | slave1 | jdk,hadoop,zookeeper | natanode,nodemanager,zookeeper,Journalnode, |
192.168.xx.123 | slave2 | jdk,hadoop,zookeeper | natanode,nodemanager,zookeeper,Journalnode, |
192.168.xx.124 | slave3 | jdk,hadoop,zookeeper | natanode,nodemanager,zookeeper,Journalnode, |
一、首先設定防火牆防火牆
立即關閉防火牆service iptables stop

設定防火牆開機不啟動 chkconfig iptables off

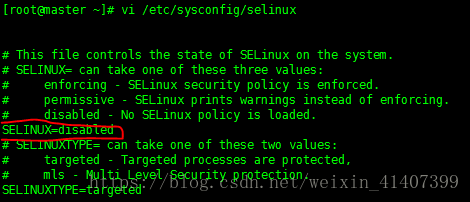
設定 selinux 將SELINUX 改為disabled
二、編輯主機名對映
vi/etc/hosts

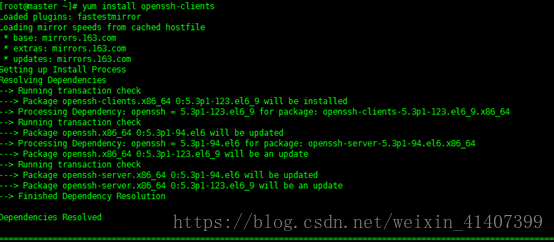
下載 ssh包獲取scp命令
yuminstall openssh-clients
將hosts遠端拷貝至後面四臺機器
scp /etc/hostsmaster2:/etc/hosts

三、設定五臺機器時間同步
最小化安裝沒有ntpdate這個軟體,首先用yum命令下載
yum –y installntp
設定master 與指定時間伺服器同步
ntpdate cn.pool.ntp.org
設定後面4臺機器與master同步
修改master ntp配置檔案
vi /etc/ntp.conf
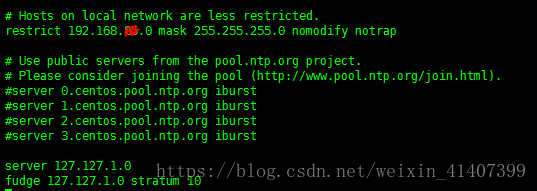
講restrict 上的網段改為自己的網段
註釋server 伺服器
在最下面新增兩行server 和fudge內容
啟動ntpd ,並設定為開機啟動

關閉後面幾臺ntpd,並設定為開機不啟動

同步master時間伺服器
ntpdate master

四、建立普通使用者
adduser hadoop
passwd hadoop 設定密碼
五、SSH免密登入
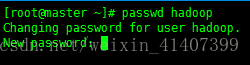
切換到普通使用者

在五臺機器上都輸入ssh-keygen –t rsa,然後一直按回車
將祕鑰拷貝到五臺機器上
ssh-copy-id master
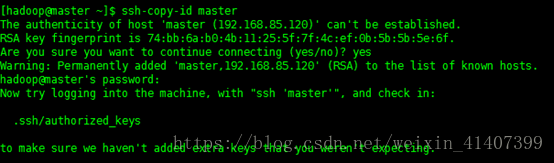
ssh-copy-id master2
ssh-copy-id slave1
ssh-copy-id slave2
ssh-copy-id slave3
測試能否免密登入,設定成功!

在其他四臺機器上重複以上操作
六、安裝jdk
我這裡是最小化安裝不需要檢查系統自己看裝的jdk,如果不是需要解除安裝
通過下面兩行命令查詢解除安裝
rpm –qa |grep jdk
rpm –e –nodep
修改/opt/資料夾使用者
chown –R hadoop:hadoop /opt/
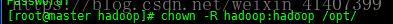
建立 /opt/software資料夾,這個資料夾用來存放壓縮包, 建立/opt/modules這個檔案用來存放解壓的軟體

上傳jdk到software

解壓jdk到modules

配置環境變變數,切換到root使用者vi /etc/profile 也可以在普通使用者下修改vi ~/.bash_profile,在最後新增

儲存退出,輸入 source /etc/profile ,然後輸入java -version驗證版本

將java scp至其他幾臺機器

將配置檔案scp至其他幾臺機器

七、進入slave1主機,安裝配置zookeeper
上傳zookeeper到software資料夾,並解壓到modules

修改zookeeper配置檔案


修改dataDir 路徑,增加server配置資訊
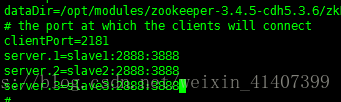
建立zkData資料夾並建立myid檔案,在slave1輸入1

scp zookeeper資料夾到slave2和slave3下

修改slave2和slave3 的myid檔案

啟動zookeeper,並驗證狀態
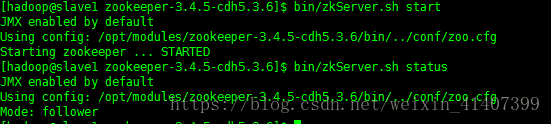
啟動 bin/zkCli.sh,配置完成!
八、安裝配置hadoop
上傳hadoop到software資料夾,並解壓到modules

配置hadoop環境變數
root vi /etc/profile, 記得source /etc/profile

修改hadoop 配置檔案
修改 etc/hadoop 下的環境變數檔案增加java環境變數
hadoop-env.sh mapred-env.sh yarn-env.sh
export JAVA_HOME=/opt/modules/jdk1.7.0_79
修改core-site.xml檔案
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/App/hadoop-2.5.0/data/tmp</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>slave1:2181,slave2:2181,slave3:2181</value>
</property>
</configuration>
修改hdfs-site.xml檔案
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通訊地址,nn1所在地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>master:8020</value>
</property>
<!-- nn1的http通訊地址,外部訪問地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>master:50070</value>
</property>
<!-- nn2的RPC通訊地址,nn2所在地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>master2:8020</value>
</property>
<!-- nn2的http通訊地址,外部訪問地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>master2:50070</value>
</property>
<!-- 指定NameNode的元資料在JournalNode日誌上的存放位置(一般和zookeeper部署在一起) -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://slave1:8485;slave2:8485;slave3:8485/ns1</value>
</property>
<!-- 指定JournalNode在本地磁碟存放資料的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/modules/hadoop-2.5.0-cdh5.3.6/data/journal</value>
</property>
<!--客戶端通過代理訪問namenode,訪問檔案系統,HDFS 客戶端與Active 節點通訊的Java 類,使用其確定Active 節點是否活躍 -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--這是配置自動切換的方法,有多種使用方法,具體可以看官網,在文末會給地址,這裡是遠端登入殺死的方法 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 這個是使用sshfence隔離機制時才需要配置ssh免登陸 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔離機制超時時間,這個屬性同上,如果你是用指令碼的方法切換,這個應該是可以不配置的 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<!-- 這個是開啟自動故障轉移,如果你沒有自動故障轉移,這個可以先不配 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>修改mapred-site.xml.template名稱為mapred-site.xml並修改
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
配置 yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- Site specific YARN configuration properties -->
<!--啟用resourcemanager ha-->
<!--是否開啟RM ha,預設是開啟的-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--宣告兩臺resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>rmcluster</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>master2</value>
</property>
<!--指定zookeeper叢集的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>slave1:2181,slave2:2181,slave3:2181</value>
</property>
<!--啟用自動恢復,當任務進行一半,rm壞掉,就要啟動自動恢復,預設是false-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--指定resourcemanager的狀態資訊儲存在zookeeper叢集,預設是存放在FileSystem裡面。-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
配置slaves
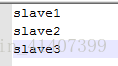
scp hadoop到其他四臺機器,拷貝之前刪除share/doc檔案


分別在master和master2的yarn-site.xml上新增
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm2</value>
</property>

啟動zookeeper

啟動journalnode sbin/hadoop-deamon.sh startjournalnode

格式化master namenode bin/hdfs namenode –format

啟動 master namenode sbin/hadoop-deamon.sh startnamenode

在master2上同步master namenode元資料 bin/hdfs namenode -bootstrapStandby

啟動master2 namenode sbin/hadoop-deamon.sh startnamenode

此時進入 50070 web頁面,兩個namenode都是standby狀態,這是可以先強制手動是其中一個節點變為active bin/hdfs haadmin –transitionToActive–forcemanual
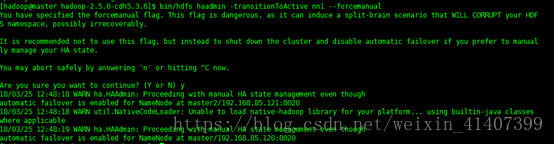
此時master變為active
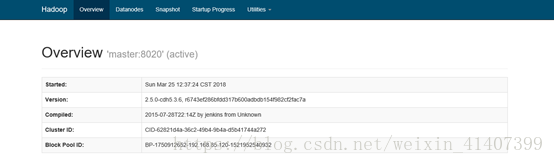
手動故障轉移已經完成,接下來配置自動故障轉移
先把整個叢集關閉,zookeeper不關,輸入bin/hdfs zkfc –formatZK,格式化ZKFC

在slave1上登入zookeeper

輸入ls / ,發現多了一個hadoop-ha節點,這是配置應該沒有問題
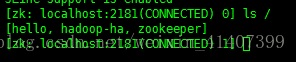
啟動叢集, 在master 輸入 sbin/start-dfs.sh
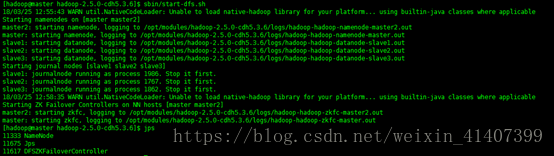
此時一個節點stanby 一個節點active
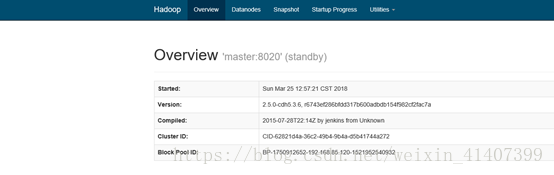
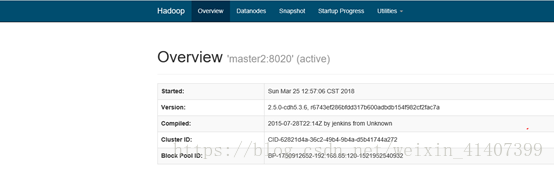
現在kill掉master namenode程序, 重新整理master頁面
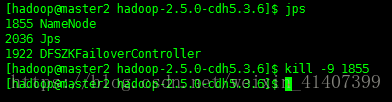
master自動切換為active,配置成功!
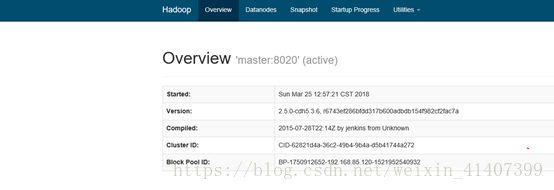
啟動yarn,測試resourcemanager ha ,master1輸入 sbin/start-yarn.sh

master2輸入 sbin/yarn-daemaon.sh start resourcemanager

在web 端輸入master2:8088自動跳轉

Kill master rm程序
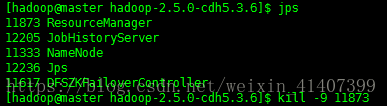
master2:8088 active

wordcount程式測試,在本地建立一個測試檔案,並上傳到hdfs上



檢視輸出檔案 hadoop fs –cat /output1/part*,執行成功

關閉active rm ,再次執行wordcount
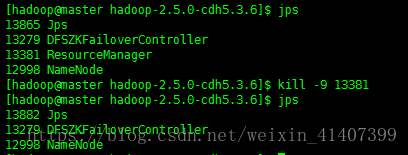

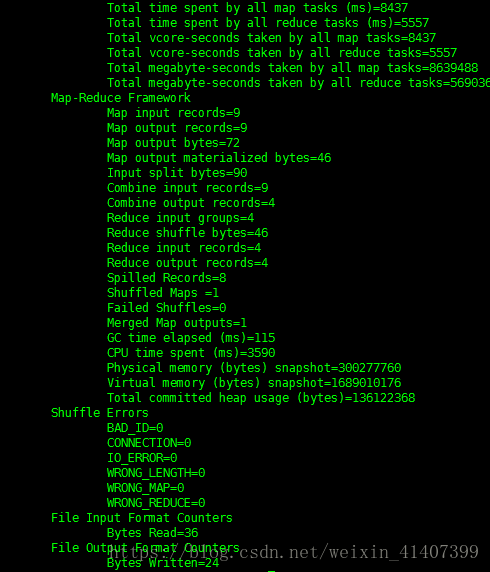
關閉active namenode,檢視檔案
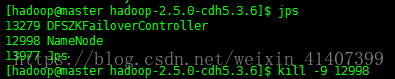
檢視成功,rm nn HA配置成功!
