
2.python資料分析與展示------Numpy資料存取與函式
1.資料的csv檔案存取
CSV (Comma‐Separated Value,逗號分隔值) ,CSV是一種常見的檔案格式,用來儲存批量資料
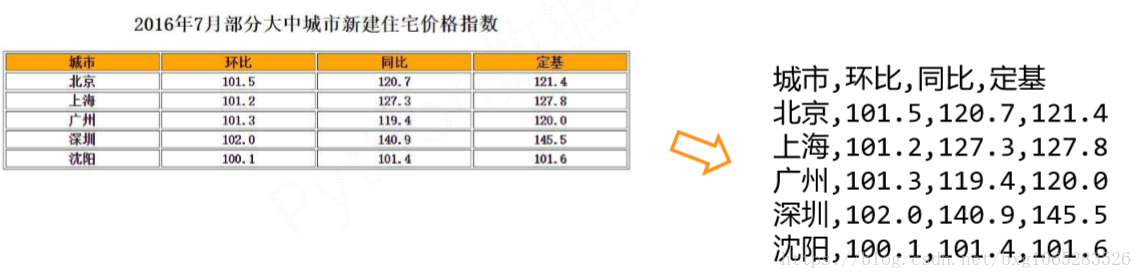
csv檔案:
np.savetxt(frame, array, fmt='%.18e', delimiter=None)
•frame : 檔案、字串或產生器,可以是.gz或.bz2的壓縮檔案
•array : 存入檔案的陣列
•fmt: 寫入檔案的格式,例如:%d %.2f %.18e
•delimiter : 分割字串,預設是任何空格
import numpy as np a=np.arange(100).reshape(5,20) np.savetxt('a.csv'np.loadtxt(frame, dtype=np.float, delimiter=None,unpack=False),a,fmt='%d',delimiter=',') 0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19 20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39 40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59 60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79 80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99 np.savetxt('b.csv',a,fmt='%.1f',delimiter=',') 0.0,1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0,11.0,12.0,13.0,14.0,15.0,16.0,17.0,18.0,19.0 20.0,21.0,22.0,23.0,24.0,25.0,26.0,27.0,28.0,29.0,30.0,31.0,32.0,33.0,34.0,35.0,36.0,37.0,38.0,39.0 40.0,41.0,42.0,43.0,44.0,45.0,46.0,47.0,48.0,49.0,50.0,51.0,52.0,53.0,54.0,55.0,56.0,57.0,58.0,59.0 60.0,61.0,62.0,63.0,64.0,65.0,66.0,67.0,68.0,69.0,70.0,71.0,72.0,73.0,74.0,75.0,76.0,77.0,78.0,79.0 80.0,81.0,82.0,83.0,84.0,85.0,86.0,87.0,88.0,89.0,90.0,91.0,92.0,93.0,94.0,95.0,96.0,97.0,98.0,99.0
•frame : 檔案、字串或產生器,可以是.gz或.bz2的壓縮檔案
•dtype: 資料型別,可選
•delimiter : 分割字串,預設是任何空格
•unpack : 如果True,讀入屬性將分別寫入不同變數
b=np.loadtxt('b.csv',delimiter=',') print(b) # [[ 0. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. # 18. 19.] # [20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36. 37. # 38. 39.] # [40. 41. 42. 43. 44. 45. 46. 47. 48. 49. 50. 51. 52. 53. 54. 55. 56. 57. # 58. 59.] # [60. 61. 62. 63. 64. 65. 66. 67. 68. 69. 70. 71. 72. 73. 74. 75. 76. 77. # 78. 79.] # [80. 81. 82. 83. 84. 85. 86. 87. 88. 89. 90. 91. 92. 93. 94. 95. 96. 97. # 98. 99.]] b=np.loadtxt('b.csv',dtype=np.int32,delimiter=',') print(b) # [[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19] # [20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39] # [40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59] # [60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79] # [80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99]]
CSV的侷限性
CSV只能有效儲存一維和二維陣列
np.savetxt() np.loadtxt()只能有效存取一維和二維陣列
2.多維資料的存取
a.tofile(frame, sep='', format='%s')
•frame : 檔案、字串
•sep: 資料分割字串,如果是空串,寫入檔案為二進位制
•format : 寫入資料的格式
a =np.arange(100).reshape(5,10,2) a.tofile("b.dat",sep=",",format='%d') # 0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,\ # 26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,\ # 49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,\ # 73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99
np.fromfile(frame, dtype=float, count=‐1, sep='')
•frame : 檔案、字串
•dtype: 讀取的資料型別
•count : 讀入元素個數,‐1表示讀入整個檔案
•sep: 資料分割字串,如果是空串,寫入檔案為二進位制
a =np.arange(100).reshape(5,10,2) a.tofile("b.dat",sep=",",format='%d') c =np.fromfile('b.dat',dtype=np.int32,sep=',') print(c) # [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 # 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 # 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 # 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 # 96 97 98 99] c =np.fromfile('b.dat',dtype=np.int32,sep=',').reshape(5,10,2) print(c) # [[[ 0 1] # [ 2 3] # [ 4 5] # [ 6 7] # [ 8 9] # [10 11] # [12 13] # [14 15] # [16 17] # [18 19]] # # [[20 21] # [22 23] # [24 25] # [26 27] # [28 29] # [30 31] # [32 33] # [34 35] # [36 37] # [38 39]] # # [[40 41] # [42 43] # [44 45] # [46 47] # [48 49] # [50 51] # [52 53] # [54 55] # [56 57] # [58 59]] # # [[60 61] # [62 63] # [64 65] # [66 67] # [68 69] # [70 71] # [72 73] # [74 75] # [76 77] # [78 79]] # # [[80 81] # [82 83] # [84 85] # [86 87] # [88 89] # [90 91] # [92 93] # [94 95] # [96 97] # [98 99]]] a =np.arange(100).reshape(5,10,2) a.tofile("b.dat",format='%d') c=np.fromfile("b.dat",dtype=np.int32).reshape(5,10,2) print(c) # [[[ 0 1] # [ 2 3] # [ 4 5] # [ 6 7] # [ 8 9] # [10 11] # [12 13] # [14 15] # [16 17] # [18 19]] # ... # [[80 81] # [82 83] # [84 85] # [86 87] # [88 89] # [90 91] # [92 93] # [94 95] # [96 97] # [98 99]]]
注意:
該方法需要讀取時知道存入檔案時陣列的維度和元素型別,a.tofile()和np.fromfile()需要配合使用,可以通過元資料檔案來儲存額外資訊3.Numpy便捷檔案讀取
np.save(fname, array) 或np.savez(fname, array)
•fname: 檔名,以.npy為副檔名,壓縮副檔名為.npz
•array : 陣列變數
np.load(fname)
•fname: 檔名,以.npy為副檔名,壓縮副檔名為.npz
a=np.arange(100).reshape(5,10,2) np.save("a.npy",a) # 揘UMPY v # {'descr': '<i4', 'fortran_order': False, 'shape': (5, 10, 2), } # # ! " # $ % & ' ( ) * + , - . / 0 1 2" \ # " 3 4 5 6 7 8 9 : ; < = > ? @ A B C" \ # " D E F G H I J K L M N O P Q R S T" \ # " U V W X Y Z [ \ ] ^ _ ` a b c b=np.load("a.npy") print(b)
4.Numpy的隨機函式
NumPy的random子庫
np.random.rand()
np.random.randn()
np.random.randint()

import numpy as np a =np.random.rand(3,4,5) print(a) # [[[0.11923456 0.0080324 0.23576131 0.71490196 0.39313982] # [0.26944438 0.30595366 0.89433112 0.76073646 0.54988195] # [0.58136344 0.82684317 0.08892499 0.96461801 0.10869441] # [0.48035625 0.58082037 0.97235769 0.83626598 0.77352449]] # # [[0.05019939 0.69692701 0.5197847 0.14322148 0.80999927] # [0.09298827 0.49460859 0.9621793 0.38776821 0.37452434] # [0.13729232 0.50410236 0.68394837 0.87087505 0.33721868] # [0.32834593 0.7600151 0.8137906 0.03984698 0.81580278]] # # [[0.82580339 0.03564352 0.55698346 0.44198408 0.69197987] # [0.78329794 0.8449475 0.68260885 0.35188764 0.13075481] # [0.11841985 0.07254895 0.34286141 0.86560175 0.2005601 ] # [0.41852062 0.63877623 0.33749892 0.98977597 0.61811358]]] sn =np.random.randn(3,4,5) print(sn) # [[[-1.29145587 -0.02309264 1.02447127 0.51065452 -0.01289186] # [ 0.16930873 -0.80807135 -1.33109108 -0.29476181 3.0812429 ] # [ 0.26575456 -1.01242421 -2.10002667 -0.38129533 0.11584166] # [-1.5870124 1.2326421 -0.38786647 -1.26054727 1.38201501]] # # [[ 0.0727602 -0.50899469 0.21616575 -0.32233134 0.35653899] # [ 1.15315991 -0.08415659 -0.01346529 -1.6210397 -0.18992538] # [-0.06780673 0.20946401 -0.42592983 0.22779739 1.27193371] # [ 2.9091403 -0.55126307 -0.36063733 -0.32533772 -0.22111197]] # # [[ 0.14910911 0.27918515 2.09298654 0.1967028 -0.45330462] # [-0.56676479 -0.14943735 -0.17003379 -1.1706462 0.56048001] # [ 0.2485423 -1.02440498 -0.84386213 0.47372249 -0.33259582] # [ 1.16471167 -0.20821131 1.50395877 0.9741344 -0.27076424]]] b =np.random.randint(100,200,(3,4)) print(b) # [[122 102 149 133] # [168 185 139 162] # [163 143 173 122]] np.random.seed(10) print(np.random.randint(100,200,(3,4))) #執行兩次結果一樣 # [[109 115 164 128] # [189 193 129 108] # [173 100 140 136]]

a=np.random.randint(100,200,(3,4)) print(a) # [[176 178 105 120] # [178 176 155 130] # [111 110 168 198]] np.random.shuffle(a) print(a) np.random.shuffle(a) print(a) # [[148 155 198 115] # [150 115 117 147] # [146 117 198 114]] # [[150 115 117 147] # [148 155 198 115] # [146 117 198 114]] print(a) print(np.random.permutation(a)) print(a) # [[163 155 163 173] # [174 108 165 194] # [135 158 121 196]] # [[174 108 165 194] # [163 155 163 173] # [135 158 121 196]] # [[163 155 163 173] # [174 108 165 194] # [135 158 121 196]] b=np.random.randint(100,200,(8,)) print(b) # [102 128 152 157 176 137 145 172] print(np.random.choice(b,(3,2))) # [[116 116] # [168 137] # [162 116]] print(np.random.choice(b,(3,2),replace=False)) # [[141 194] # [130 119] # [116 134]] print(np.random.choice(b,(3,2),p=b/np.sum(b))) # [[113 162] # [113 149] # [151 113]]

u =np.random.uniform(0,10,(3,4)) print(u) # [[5.46036254 6.12551993 5.53542549 7.72189327] # [3.43793947 9.94257227 3.15125202 3.60695433] # [5.67253129 5.95136365 0.79214474 9.264223 ]] n =np.random.normal(10,5,(3,4)) print(n) # [[ 2.53432016 12.77204898 15.57069479 14.18012267] # [12.62327262 16.08612479 9.45541684 7.99660799] # [ 8.9902546 17.84417588 7.42343768 9.52946522]]
5. Numpy的統計函式
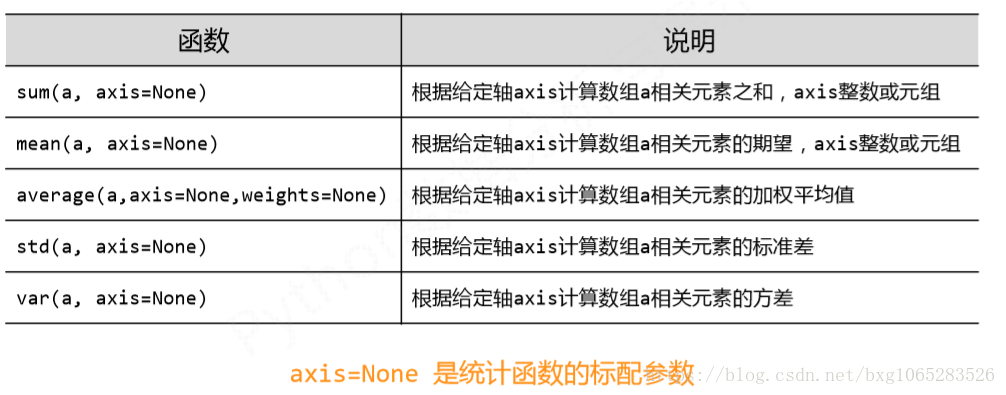
NumPy直接提供的統計類函式
np.std()
np.var()
np.average()
import numpy as np a =np.arange(15).reshape(3,5) print(a) # [[ 0 1 2 3 4] # [ 5 6 7 8 9] # [10 11 12 13 14]] print(np.sum(a)) # 105 print(np.mean(a,axis=1)) # [ 2. 7. 12.] print(np.mean(a,axis=0)) # [5. 6. 7. 8. 9.] print(np.average(a,axis=0,weights=[10,5,1])) # [2.1875 3.1875 4.1875 5.1875 6.1875] #4.1875=2*10+7*5+1*12/(10+5+1)=4.1875 print(np.std(a)) # 4.320493798938574 print(np.var(a)) # 18.666666666666668
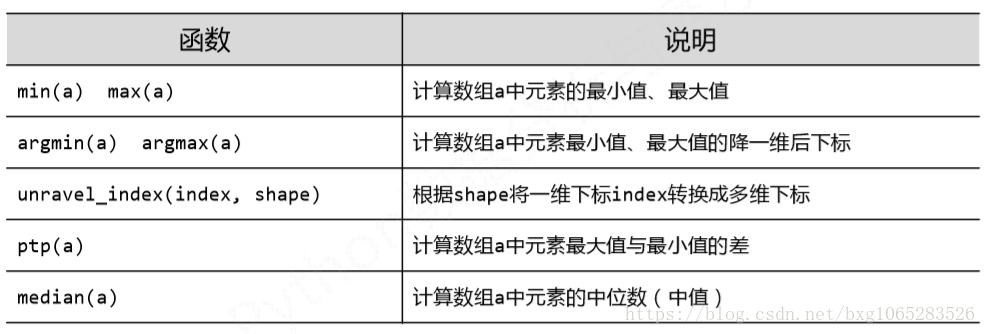
b=np.arange(15,0,-1).reshape(3,5) print(b) # [[15 14 13 12 11] # [10 9 8 7 6] # [ 5 4 3 2 1]] print(np.max(b)) #15 print(np.argmax(b)) #0 #扁平化後的下標 print(np.unravel_index(np.argmax(b),b.shape)) #重塑成多維下標 #(0, 0) print(np.ptp(b)) #14 print(np.median(b)) #8.0
6.Numpy的梯度函式

import numpy as np a =np.random.randint(0,20,(5)) print(a) #[ 9 18 1 3 12] print(np.gradient(a)) # [ 9. -4. -7.5 5.5 9. ] #-4=(1-9)/2 存在兩側值 #9=(12-3)/1 只有一側值 c=np.random.randint(0,50,(3,5)) print(c) print(np.gradient(c)) #[[22 11 18 0 15] # [19 23 16 30 24] # [24 36 20 24 40]] #最外層維度的梯度 # [array([[-3. , 12. , -2. , 30. , 9. ], # [ 1. , 12.5, 1. , 12. , 12.5], # [ 5. , 13. , 4. , -6. , 16. ]]), # 第二層維度的梯度 # array([[-11. , -2. , -5.5, -1.5, 15. ], # [ 4. , -1.5, 3.5, 4. , -6. ], # [ 12. , -2. , -6. , 10. , 16. ]])]

