
從二項分佈到泊松分佈再到正態分佈
如果忽略分佈是離散還是連續的前提(二項分佈和泊松分佈一樣都是離散型概率分佈,正態分佈是連續型概率分佈),二項分佈與泊松分佈以及正態分佈至少在形狀上是十分接近的,也即兩邊低中部高。
由從 Poisson 分佈到伺服器的訪問 可知,當 n 足夠大,p 足夠小(還記得泊松分佈的事件間的三個條件嗎,彼此獨立,事件發生的概率不算太大,事件發生的概率是穩定的),二項分佈逼近泊松分佈,
至於正態分佈是一個連續分佈 當實驗次數 n 再變大,幾乎可以看成連續時二項分佈和泊松分佈都可以用正態分佈來代替。

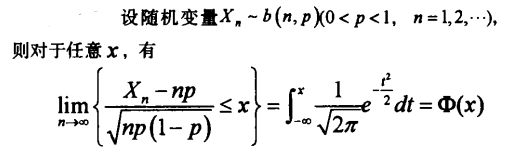
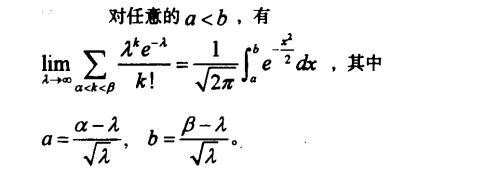
相關推薦
一點一點重學統計學(二)——二項、泊松和正態分佈
貝努裡大數定律:當試驗在不變的條件下,重複次數無限大,抽樣群體某一個概率與理論概率的差值,必定小於一個任意小的正數,所以這兩者可以基本相等,也可以用線性模型來解釋,隨著抽樣的總數增加誤差的平均會越來越
R語言實戰--隨機產生服從不同分佈函式的資料(正態分佈,泊松分佈等),並將資料寫入資料框儲存到硬碟
隨機產生服從不同分佈的資料 均勻分佈——runif() > x1=round(runif(100,min=80,max=100)) > x1 [1] 93 100 98 98 92 98 98 89 90 98 100 89
課堂練習--計算陣列的最大值,最小值,平均值,標準差,中位數;numpy.random模組提供了產生各種分佈隨機數的陣列;正態分佈;Matplotlib
#計算陣列的最大值,最小值,平均值,標準差,中位數 import numpy as np a=np.array([1, 4, 2, 5, 3, 7, 9, 0]) print(a) a1=np.max(a) #最大值 print(a1) a2=np.min(a) #最小值 print(a2) a3
從二項分佈到泊松分佈再到正態分佈
如果忽略分佈是離散還是連續的前提(二項分佈和泊松分佈一樣都是離散型概率分佈,正態分佈是連續型概率分佈),二項分佈與泊松分佈以及正態分佈至少在形狀上是十分接近的,也即兩邊低中部高。 由從 Poisson
數學(3) 各種數學分佈,高斯,伯努利,二項,多項,泊松,指數,Beta,Dirichlet
打算這裡記錄各種數學分佈,隨時更新 正態分佈 正態分佈又名高斯分佈。 若隨機變數X服從一個數學期望為μ,標準差為σ的正態分佈,則記為X~N(μ,σ2)。 其中期望μ決定了分佈位置,標準差σ決定了分佈幅度。 概率密度函式為: f(x)=1σ2π
泊松分佈 二項分佈 正態分佈之間的聯絡,與繪製高斯分佈圖
基礎知識 二項分佈有兩個引數,一個 n 表示試驗次數,一個 p 表示一次試驗成功概率。現在考慮一列二項分佈,其中試驗次數 n 無限增加,而 p 是 n 的函式。 1.如果 np 存在有限極限 λ,則這列二項分佈就趨於引數為 λ 的 泊松分佈。反之,如果 np 趨於
C#產生正態分佈、泊松分佈、指數分佈、負指數分佈隨機數(原創)
http://blog.sina.com.cn/s/blog_76c31b8e0100qskf.html 在程式設計過程中,由於資料模擬模擬的需要,我們經常需要產生一些隨機數,在C#中,產生一般隨機數用Random即可,但是,若要產生服從特定分佈的隨機數,就需要一定的演
Excel圖表—二項分佈和正態分佈的對應關係
問題:假定某二項分佈對應引數為n=500, p=0.4,試分析與該二項分佈具有相同均值和標準差的正態分佈於該二項分佈的漸進關係。 結論:在實驗次數較大時(n=500),二項分佈已經與正態分佈基本
統計2 泊松過程 大數定理 正態分佈
二項分佈的方差:variance = np(1-p) 泊松過程 假設1.各個時間車流量沒有差異 2.一段時的車流量對另一段時間沒有影響:隨機變數X=每小時某路口通過的車輛 E(X)=lambda = n*p (建模為二項分佈) = 60(min/ho
從np.random.normal()到正態分佈的擬合
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
20.方差/標準差/數學期望/正態分佈/高斯函式(數學篇)--- OpenCV從零開始到影象(人臉 + 物體)識別系列
本文作者:小嗷 微信公眾號:aoxiaoji 吹比QQ群:736854977 本文你會找到以下問題的答案: 方差 標準差 數學期望 正態分佈 高斯函式 2.1 方差 方差描述隨機變數對於數學期望的偏離程度。(隨機變數可以
漫步數理統計二十六——多元正態分佈
本片博文介紹多元正態分佈,我們以n維隨機變數為主,但給出n=2時二元情況的一些例項。與上篇文章一樣,我們首先介紹標準情況然後擴充套件到一般情況,當然這裡會用到向量與矩陣符號。 考慮隨機向量Z=(Z1,…,Zn)′,其中Z1,…,Zn是獨立同分布的N(0,1)隨
從 高斯 到 正態分佈 到 Z分佈 到 t分佈
正態分佈是如何被高斯推匯出來的, 我感覺高斯更像是猜出了正態分佈。 詳見這篇文章:《正態分佈的前世今生》 http://songshuhui.net/archives/76501 說一說理解高斯推導過
tf從截斷的正態分佈中生成隨機值
在word2vec中計算初始權重的時候,生成正態分佈隨機權重,正態分佈隨機權重的函式tf.truncated_normal() #-*-coding:utf8-*- import tensorflow as tf a = tf.Variable(tf.random_norm
二維高斯正態分佈函式(轉)
二維高斯正態分佈函式(原創) 二維高斯正態分佈函式在很多地方都用的到,比如說在濾波中,自己編了個,但感覺IDL中應該有現成的函式??(我沒找到)。如有,請高手指點。 ;------------
二維正態分佈的引數與概率密度圖形
用Microsoft Mathematics繪製二維正態分佈的概率密度圖形,引數可以互動地調整。 N(μ1, μ2; σ1, σ2, ρ) μ1 = 1, μ2 = 1, σ1 = 0.49, σ2 = 0.49, ρ = 0 μ1
Matlab從多維正態分佈中隨機抽取樣本:mvnrnd
原帖地址:http://blog.sina.com.cn/s/blog_955cedd8010130m8.html R = mvnrnd(MU,SIGMA)——從均值為MU,協方差為SIGMA的正態分佈中抽取n*d的矩陣R(n代表抽取的個數,d代表分佈的維數)。
一維正態分佈、二維正態分佈的matlab實現
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %本程式用於產生一維正態分佈、二維正態分佈 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %繪製一維正態分佈 x=linspace(-3,3); y
Matlab 從多維正態分佈中隨機抽取樣本:mvnrnd
R = mvnrnd(MU,SIGMA)——從均值為MU,協方差為SIGMA的正態分佈中抽取n*d的矩陣R(n代表抽取的個數,d代表分佈的維數)。MU為n*d的矩陣,R中的每一行為以MU中對應的行為均值的正態分佈中抽取的一個樣本。SIGMA為d*d的對稱半正定矩陣,或者為d*d*n的array。若SIGMA為
機器視覺學習之--貝葉斯學習 MATLAB二維正態分佈二維圖
1、貝葉斯介紹 我個人一直很喜歡演算法一類的東西,在我看來演算法是人類智慧的精華,其中蘊含著無與倫比的美感。而每次將學過的演算法應用到實際中,並解決了實際問題後,那種快感更是我在其它地方體會不到的。 一直想寫關於演算法的博文,也曾寫過零散的兩篇,但也許是相