
【深度學習】深度學習分類與模型評估
內容大綱
- 分類和迴歸之外的機器學習形式
- 評估機器學習模型的規範流程
- 為深度學習準備資料
- 特徵工程
- 解決過擬合問題
- 處理機器學習問題的通用流程
監督學習的主要種類及其變種
主要包括兩大類問題:
- 分類
- 迴歸
變種問題主要有:
- 序列生成:給定一張影象,輸出描述影象的文字;可以被重新表示為分類問題
- 語法樹預測:給定一個句子,輸出其分解生成的語法樹
- 目標檢測:給定一張影象,在圖中的目標周圍繪製一個邊界框;可以被表示為分類問題,或者分類與迴歸聯合問題
- 影象分割:給定影象,在特定的物體上畫一個畫素級別的mask
無監督學習
不給定目標值,模型需要從輸入資料中尋找到有價值的變換,常常用來做資料視覺化,資料壓縮,資料去噪或者輔助我們更好理解資料中的相關性等。
無監督學習是資料分析的必備技能。
為了更好的理解資料集,無監督學習是一個必要步驟。比如降維和聚類分析方法。
自監督學習
這個是監督學習的一個特例。它的特殊之處在於沒有人工標註的標籤,但是標籤仍然存在,而這些標籤是如何生成的呢?它們來自輸入資料,常常用啟發式演算法來生成。
強化學習
智慧體接收有關環境的資訊,並學會選擇使得獎勵函式最大化的動作。
部分術語解析
- 二分類:每個輸入樣本被劃分到兩個互斥的類別之一
- 多分類:每個輸入樣本被劃分到兩個以上的類別之一,如手寫體數字分類
- 多標籤分類:每個輸入樣本都可以被劃分到多個標籤,如影象標註任務
- 標量回歸:輸出一個標量,連續值
- 向量迴歸:輸出一組連續值的任務,比如輸出影象中物體的邊界框
- 小批量,批量:模型同時處理的一部分樣本,通常取2的冪,便於GPU分配記憶體
模型評估
訓練集,驗證集和測試集
三者的具體分工是:在訓練集上訓練模型,在驗證集上評估模型以及在測試集上最後測試。
在驗證集上可以調節超引數,比如前面訓練時,我們用驗證集上的效果來得出訓練多少輪次合適,這就是超引數選擇的過程。調節模型時,是萬萬不能用到測試集的,測試集就像最後的高考,驗證集則是月考,訓練集則是我們平時的作業。
三種經典的評估方法
- 留出驗證
- K折驗證
- 含打亂資料的重複驗證
留出驗證
即留出一定比例的資料作為測試集,為了調節模型我們還需要從訓練集中拿出一部分資料做驗證集。

這個圖只表達了劃分出兩部分資料,訓練集裡還要再細分出一部分資料做驗證,本質上,驗證集也是訓練調節模型,大類仍可歸於訓練集。
num_validation_samples = 10000
np.random.shuffle(data) # 打亂資料
validation_data = data[:num_validation_samples] # 驗證集
train_data = data[num_validation_samples:]
model = build_model()
model.fit(train_data, train_targets)
validation_score = model.evaluate(validation_data) # 驗證集上評估模型並得出最優超引數
# 找到最優超引數,重新訓練
model = build_model()
model.fit(np.concatenate([train_data, validation_data], train_targets)
test_score = model.evaluate(test_data)
在知曉超引數以後,重新訓練模型時,驗證集資料也作為訓練集資料,這樣可以更好的訓練模型。
這個驗證方法不適用於樣本資料量較少的情況。
K折驗證
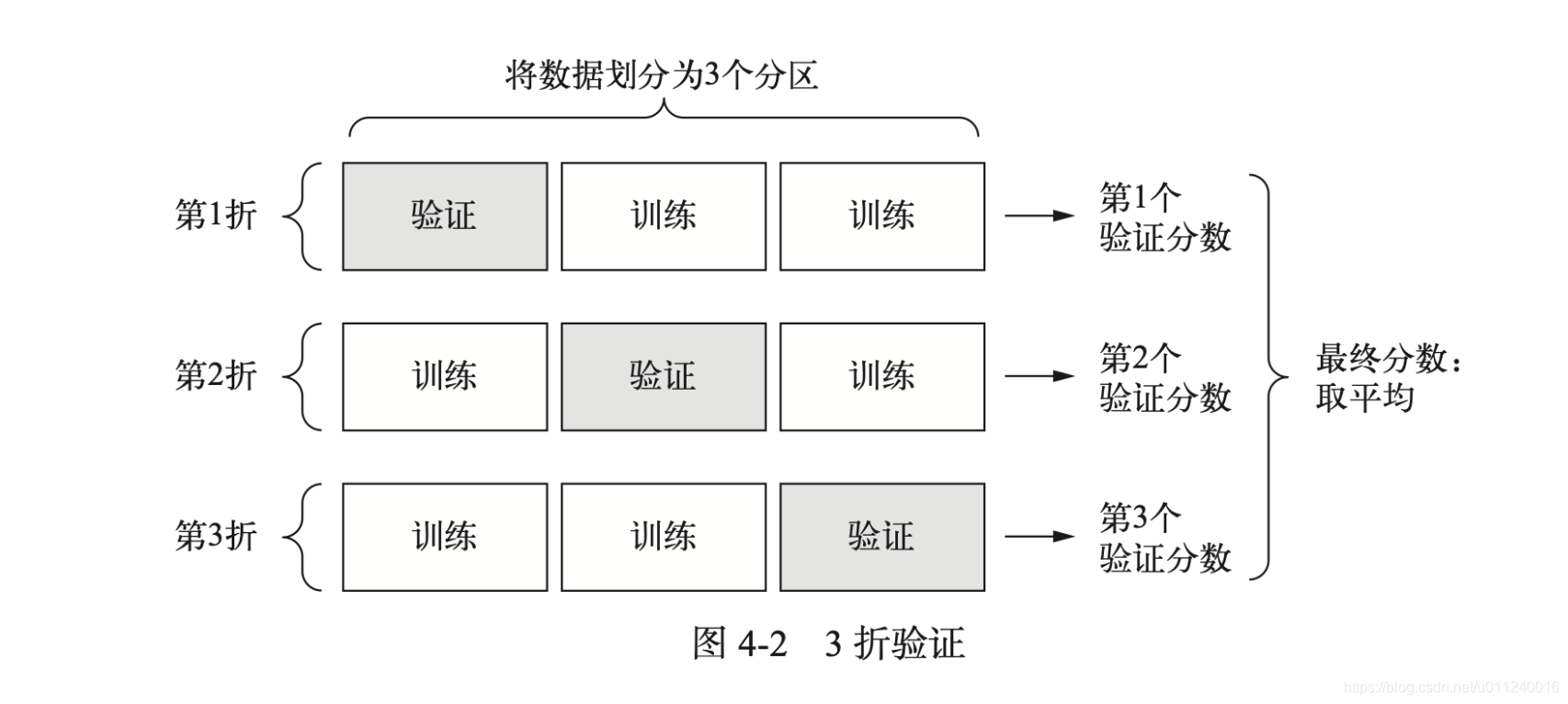
這個一圖就說明白了,但還是需要特別強調一下,這裡的資料確定後是個整體,當然之前可以先打亂使得分佈均勻。然後砍成一段一段的,拼在一起就是完整的資料集。之所以這麼強調,是為了和下面的打亂隨機K折驗證區分一下。
k = 3
num_validation_samples = len(data) // k
np.random.shuffle(data)
validation_scores = [] # 每一折得出一個驗證分數
for fold in range(k):
validation_data= data[num_validation_samples * fold: num_validation_samples * (fold + 1)]
train_data = data[:num_validation_samples * fold] + data[num_validation_samples * (fold + 1):]
model = build_model()
model.fit(train_data)
validation_score = model.evaluate(validation_data)
validation_scores.append(validation_score)
validation_score = np.average(validation_scores)
model = build_model()
model.fit(data)
test_score = model.evaluate(test_data)
包含打亂資料的重複K折驗證
一句話描述就是,多次使用上面的K折驗證,每次都打亂資料一下。假設重複P次,那麼需要訓練和評估的模型個數是PxK個,這種做法代價很大,但是效果很好,在Kaggle比賽裡很有用。
評估模型的注意事項
資料代表性
將資料隨機打亂,可以使得訓練集和測試集都能代表當前資料。
時間箭頭
如果是用過去資料來預測未來,則不能隨機打亂資料,否則會導致時間洩露問題。
資料冗餘
我們需要保證訓練集和驗證集之間不存在交集。
資料預處理,特徵工程,特徵學習
在具體使用模型之前,需要耗費很大精力來處理資料。
資料預處理
針對神經網路,我們將資料處理得更加適用於神經網路處理。主要包括如下幾種方法:
- 向量化
- 標準化
- 缺失值處理
- 特徵提取
特徵工程
通常機器學習模型無法從完全任意的資料中學習。所以我們需要利用先驗知識對資料進行編碼轉換,以改善模型的效果。
特徵工程的本質是:用更簡單的方式表述問題,使得問題更加容易解決。這需要我們深入理解問題。
現代深度學習,大部分特徵工程是不需要的。神經網路可以從原始資料中自動提取有用特徵。但是並不表示深度神經網路不需要特徵工程。使用特徵工程,一方面可以用更少的資源解決問題,另一方面,定義良好的特徵可以更少的資料解決問題。樣本很少時,恰當的特徵工程價值極大。
處理過擬合和欠擬合問題
欠擬合表示模型仍有改進的空間,還需要繼續訓練,所以這個問題不大,更需要特別設計解決的是過擬合問題。降低過擬合的方法叫作正則化。常用的正則化的方法有:
- 減小網路大小
- 新增權重正則化
- L1
- L2
- 新增dropout正則化
減小網路大小
這是防止過擬合的最簡單的方法,通過減少模型的學習引數個數。
**模型容量:**可學習引數的個數。
深度學習模型通常都很擅長擬合訓練資料,但是真正的挑戰在於泛化,而不是擬合。
更大的網路的訓練損失容易很快就接近0,即網路的容量越大,則擬合數據的速度就越快,也就容易過擬合。
新增權重正則化
from keras import regularizers
model = models.Sequential()
model.add(layers.Dense(16, kernel_regularizer=regularizers.l2(0.001), activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, kernel_regularizer=regularizers.l2(0.001), activation='relu'))
model.add(layers.Dense(1, kernel_regularizer=regularizers.l2(0.001), activation='relu'))
其中,l2(0.001)的意思是:該層權重矩陣的每個係數都會使網路總損失增加0.001 * weight_coefficient_calue,懲罰項只在訓練時新增,測試時不計算,所以訓練損失會大於測試損失。
新增dropout正則
這是訓練神經網路最有效也最常用的方法。對某一層使用dropout,會在訓練過程中隨機將該層的一些輸出特徵置為0。設定的dropout比率是元素被設定為0的比例。測試時沒有單元會被捨棄。
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation='sigmoid'))
深度學習流程
這部分再單獨寫一篇筆記,之前也寫過一次。
END.
參考:
《Deep Learning with Python》