
全量資料同步與資料校驗實踐——應對百億量級分庫分表異構庫遷移
在一家發展中的公司搬磚,正好遇到分庫分表,資料遷移的需求比較多,就入坑了。最近有個系統重構,一直做資料重構、遷移、校驗等工作,基本能覆蓋資料遷移的各個基本點,所以趁機整理一下。
- 資料同步的場景是:資料庫拆分、資料冗餘、資料表重構。
- 資料重構服務主要包括:全量遷移、全量資料校驗、增量資料同步和增量資料校驗四個功能。
本文主要講述DB-DB全量遷移的通用解決方案,主要是解決幾個問題:
NO.1 如何把一個億量級的單表遷移至一個目標表?
分頁查詢sql選型
使用 offset
SELECT … LIMIT row_count OFFSET offset顯然不行,查詢到千萬的時候執行一個 sql 要30s了,越到後面,sql執行速度越慢。
結合索引與limit
SELECT * FROM schemaAndTableWHERE{key} >= minIndexORDERBY{key} LIMIT ${row_count}就是對 key 欄位排序,取大於minIndex的row_count 行記錄,然後取這row_count行記錄的最大值,做下一頁查詢的minIndex。參考:分頁查詢的那些坑
批量 insert sql 選型
只討論 mysql 的情況,可以直接使用批量insert sql,也可以使用批量 insert …on duplicate key update sql。
insert ,但不支援重試,每次重試都要先清理表,才能執行批量 insert操作,否則就主鍵衝突或者重複了,而且清理大表時需要花費不少的等待時間。
insert …on duplicate key update, 可以做到在不存在主鍵或唯一鍵的情況下,執行insert 操作,否則執行 update 操作,支援多次重試。在生產環境先清空表,再做全量遷移,更為保險。Demo SQL:
INSERT INTO`test`(`value`,`value2`,`value3`) VALUES ('v','g', 9), ('w','g', 5) ON DUPLICATE KEY 注意:在 mysql RR 隔離級別的情況下,表結構中有主鍵和唯一鍵的情況下,併發執行insert …on duplicate key update 存在死鎖問題,可以設定 session 為 RC 隔離級別,初始化 sql:
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;NO.2 如何把一個億量級的單表遷移至由多個例項資料庫組成的分庫分表中?
使用類似tddl的分庫分表代理工具
前提是公司中有團隊專門維護,並且已應用於日常的分庫分表需求中,那麼在資料遷移的時候使用代理工具會變得非常簡單,你只需要關注源資料查詢與資料轉換,後面的活都可以交給代理工具來辦。但是,使用代理工具意味著需要先請求代理服務,代理服務進行 sql 解析,根據規則路由計算分片,最後才去執行。瓶頸往往會發生在 代理服務的sql 解析和規則計算。
自己計算分片與 insert
- 比較靈活,直接查詢目標分片資料庫。根據拆分欄位,表數量,表字首和分片演算法計算目標表名,然後從目標表池中找到該目標表所在庫。
- 譬如:拆分欄位是ACCOUNT_ID,表數量4096,均勻分佈在四個庫中,表字首是tb_account_detail, 分片演算法是:拆分欄位值對錶數量4096取模;
- 那麼,當ACCOUNT_ID = 88888888 時, 88888888 % 4096 = 1592,那麼記錄的分片目標表是tb_account_detail1592,在庫表池中找到tb_account_detail1592,知道目標表在第二個庫中;
- 把所有目標分片相同的記錄都合併成一個批量 insert sql中執行。
- 優勢:效率提高,由於使用固定的sql 格式,無需做sql 解析,可以對同一個目標分片的記錄構造批量insert。
No.3 如何設計工具的系統結構,以應對業務對行記錄進行轉換需求呢?
資料遷移過程中,業務對資料有各種各樣的轉換需求,譬如:
- 源資料的價格單位是元,同步到目標庫後價格單位要是分;
- 一行記錄,需要衍射出多行記錄
- 根據欄位 A,B 欄位內容,構造 C 欄位的值
- 本表字段值是 表2中 A欄位值
我使用外掛方式載入業務轉換邏輯程式碼,分離資料遷移&校驗主流程和業務邏輯轉換,框架向業務轉換邏輯提供分頁資料,業務轉換邏輯返回轉換後的分頁資料,框架執行後續遷移或校驗的操作。
簡單的,可以把業務轉換邏輯程式碼安置在專案程式碼中,通過Class.forName()獲取邏輯轉換類並建立一個例項,這種方式不靈活。
public EventProcessor getProcessor(String processorName) throws ClassNotFoundException, IllegalAccessException, InstantiationException {
Class<EventProcessor> processorClass = (Class<EventProcessor>) Class.forName("com.weidian.tech.baymax.processor.impl." + processorName);
return processorClass.newInstance();
}複雜點,可以把業務轉換邏輯程式碼,動態傳入,可以以檔案路徑方式傳入,也可以通過字串方式傳入,參考Java執行時動態生成class的方法
注意有坑:當更新部分欄位時,表中有
`update_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP欄位的需要特別注意,如果業務依賴該欄位,需要把原update_time 值設定到 update sql中。
No.4 如何加速遷移效率?
遷移效率主要受查詢資料來源、資料處理、網路傳輸、插入目標記錄、建立索引等步驟影響,
- 網路傳輸主要受機房內部的傳輸頻寬影響,可以暫時不考慮對硬體資源提升和底層傳輸協議優化;
- 插入目標記錄和建立索引主要受表結構影響,記錄的插入和建立索引都需要消費時間,通用工具不能改變表結構,因此插入目標記錄和建立索引的效率優化在此也不考慮;
- 查詢資料來源方面,採用分頁查詢,為了避免使用 offset 導致查詢效率越來越低,採用結合索引與limit 方案,可以使每一頁查詢都走索引查詢,提高查詢效率
- 資料處理步驟,包括資料包裝、資料業務邏輯轉換,計算目標分片等,主要是cpu 密集型。如果想簡單粗暴些,cpu資源又充足的話,可以通過併發處理進行優化;但是個人不推薦效率優化都使用併發改造,治標不治本,我更喜歡是使用jprofile通過效能監控找到可優化的高 cpu 佔用函式,再做函式優化。
- 目標資料同步部分優化,主要從批量資料插入和併發執行兩個方面進行優化
- 全量資料遷移過程中,查詢源資料步驟和插入目標資料步驟職責鮮明,插入目標資料步驟的處理速度一般情況下相比查詢源資料慢,可以通過使用生產者消費者模型解耦這兩個步驟。
解決方案
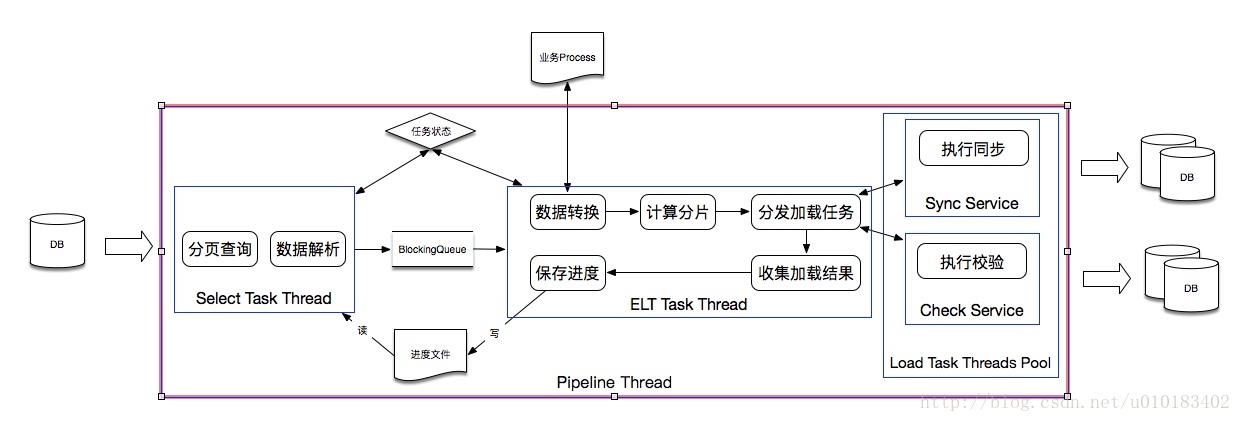
原理描述:
- 生產者執行緒從源資料庫分頁查詢並組裝資料後,推進 Blocking Queue
- 消費者執行緒從 Blocking Queue拉取分頁資料後,依次執行資料業務邏輯轉換,計算分片,分發併發任務執行插入,收集結果和儲存處理進度
- 生產者與消費者共同監視一個volatile 關鍵字修飾的訊號量,當任意一方發生失敗,通過關閉訊號量通知另一方終止任務。
該方案能解決什麼?
- 業務定製化資料轉換
- 同構/異構表資料表遷移
- 資料分庫分表遷移與校驗
單機房效能指標
據生產環境遷移情況,記憶體佔用小於2G,遷移14億資料花費24小時,平均遷移效率約為40w行/分鐘