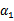SVM中的對偶問題、KKT條件以及對拉格朗日乘子求值得SMO演算法
考慮以下優化問題
![clip_image001[9]](http://images.cnblogs.com/cnblogs_com/jerrylead/201103/201103131234477453.png "clip_image001[9]")
目標函式是f(w),下面是等式約束。通常解法是引入拉格朗日運算元,這裡使用![]() 來表示運算元,得到拉格朗日公式為
來表示運算元,得到拉格朗日公式為
![clip_image004[6]](http://images.cnblogs.com/cnblogs_com/jerrylead/201103/201103131234483700.png "clip_image004[6]")
L是等式約束的個數。
然後分別對w和![]() 求偏導,使得偏導數等於0,然後解出w和
求偏導,使得偏導數等於0,然後解出w和![]() 。至於為什麼引入拉格朗日運算元可以求出極值,原因是f(w)的dw變化方向受其他不等式的約束,dw的變化方向與f(w)的梯度垂直時才能獲得極值,而且在極值處,f(w)的梯度與其他等式梯度的線性組合平行,因此他們之間存線上性關係。(參考《最優化與KKT條件》)
。至於為什麼引入拉格朗日運算元可以求出極值,原因是f(w)的dw變化方向受其他不等式的約束,dw的變化方向與f(w)的梯度垂直時才能獲得極值,而且在極值處,f(w)的梯度與其他等式梯度的線性組合平行,因此他們之間存線上性關係。(參考《最優化與KKT條件》)
然後我們探討有不等式約束的極值問題求法,問題如下:
![clip_image007[6]](http://images.cnblogs.com/cnblogs_com/jerrylead/201103/201103131234511451.png "clip_image007[6]")
我們定義一般化的拉格朗日公式
![clip_image008[6]](http://images.cnblogs.com/cnblogs_com/jerrylead/201103/201103131234515322.png "clip_image008[6]")
這裡的![]() 和
和![]() 都是拉格朗日運算元。如果按這個公式求解,會出現問題,因為我們求解的是最小值,而這裡的
都是拉格朗日運算元。如果按這個公式求解,會出現問題,因為我們求解的是最小值,而這裡的![]() 已經不是0了,我們可以將
已經不是0了,我們可以將![]() 調整成很大的正值,來使最後的函式結果是負無窮。因此我們需要排除這種情況,我們定義下面的函式:
調整成很大的正值,來使最後的函式結果是負無窮。因此我們需要排除這種情況,我們定義下面的函式:
![]()
這裡的P代表primal。假設![]() 或者
或者![]() ,那麼我們總是可以調整
,那麼我們總是可以調整![]() 和
和![]() 來使得
來使得![]() 有最大值為正無窮。而只有g和h滿足約束時,
有最大值為正無窮。而只有g和h滿足約束時,![]() 為f(w)。這個函式的精妙之處在於
為f(w)。這個函式的精妙之處在於![]() ,而且求極大值。
,而且求極大值。
因此我們可以寫作
![]()
這樣我們原來要求的min f(w)可以轉換成求![]() 了。
了。
![]()
我們使用![]() 來表示
來表示![]() 。如果直接求解,首先面對的是兩個引數,而
。如果直接求解,首先面對的是兩個引數,而![]() 也是不等式約束,然後再在w上求最小值。這個過程不容易做,那麼怎麼辦呢?
也是不等式約束,然後再在w上求最小值。這個過程不容易做,那麼怎麼辦呢?
我們先考慮另外一個問題![]()
D的意思是對偶,![]() 將問題轉化為先求拉格朗日關於w的最小值,將
將問題轉化為先求拉格朗日關於w的最小值,將![]() 和
和![]() 看作是固定值。之後在
看作是固定值。之後在![]() 求最大值的話:
求最大值的話:
![]()
這個問題是原問題的對偶問題,相對於原問題只是更換了min和max的順序,而一般更換順序的結果是Max Min(X) <= MinMax(X)。然而在這裡兩者相等。用![]() 來表示對偶問題如下:
來表示對偶問題如下:
![]()
下面解釋在什麼條件下兩者會等價。假設f和g都是凸函式,h是仿射的(affine,![]() )。並且存在w使得對於所有的i,
)。並且存在w使得對於所有的i,![]() 。在這種假設下,一定存在
。在這種假設下,一定存在![]() 使得
使得![]() 是原問題的解,
是原問題的解,![]() 是對偶問題的解。還有
是對偶問題的解。還有![]() 另外,
另外,![]() 滿足庫恩-塔克條件(Karush-Kuhn-Tucker,
KKT condition),該條件如下:
滿足庫恩-塔克條件(Karush-Kuhn-Tucker,
KKT condition),該條件如下:
![clip_image048[6]](http://images.cnblogs.com/cnblogs_com/jerrylead/201103/201103131235189201.png "clip_image048[6]")
所以如果![]() 滿足了庫恩-塔克條件,那麼他們就是原問題和對偶問題的解。讓我們再次審視公式(5),這個條件稱作是KKT
dual complementarity條件。這個條件隱含了如果
滿足了庫恩-塔克條件,那麼他們就是原問題和對偶問題的解。讓我們再次審視公式(5),這個條件稱作是KKT
dual complementarity條件。這個條件隱含了如果![]() ,那麼
,那麼![]() 。也就是說,
。也就是說,![]() 時,w處於可行域的邊界上,這時才是起作用的約束。而其他位於可行域內部(
時,w處於可行域的邊界上,這時才是起作用的約束。而其他位於可行域內部(![]() 的)點都是不起作用的約束,其
的)點都是不起作用的約束,其![]() 。這個KKT雙重補足條件會用來解釋支援向量和SMO的收斂測試。
。這個KKT雙重補足條件會用來解釋支援向量和SMO的收斂測試。
這部分內容思路比較凌亂,還需要先研究下《非線性規劃》中的約束極值問題,再回頭看看。KKT的總體思想是將極值會在可行域邊界上取得,也就是不等式為0或等式約束裡取得,而最優下降方向一般是這些等式的線性組合,其中每個元素要麼是不等式為0的約束,要麼是等式約束。對於在可行域邊界內的點,對最優解不起作用,因此前面的係數為0。
7 最優間隔分類器(optimal margin classifier)
重新回到SVM的優化問題:
![clip_image057[6]](http://images.cnblogs.com/cnblogs_com/jerrylead/201103/201103131235229818.png "clip_image057[6]")
我們將約束條件改寫為:
![]()
從KKT條件得知只有函式間隔是1(離超平面最近的點)的線性約束式前面的係數![]() ,也就是說這些約束式
,也就是說這些約束式![]() ,對於其他的不在線上的點(
,對於其他的不在線上的點(![]() ),極值不會在他們所在的範圍內取得,因此前面的係數
),極值不會在他們所在的範圍內取得,因此前面的係數![]() .注意每一個約束式實際就是一個訓練樣本。
.注意每一個約束式實際就是一個訓練樣本。
看下面的圖:
![clip_image067[6]](http://images.cnblogs.com/cnblogs_com/jerrylead/201103/201103131235267786.png "clip_image067[6]")
實線是最大間隔超平面,假設×號的是正例,圓圈的是負例。在虛線上的點就是函式間隔是1的點,那麼他們前面的係數![]() ,其他點都是
,其他點都是![]() 。這三個點稱作支援向量。構造拉格朗日函式如下:
。這三個點稱作支援向量。構造拉格朗日函式如下:
![clip_image068[6]](http://images.cnblogs.com/cnblogs_com/jerrylead/201103/201103131235281633.png "clip_image068[6]")
注意到這裡只有![]() 沒有
沒有![]() 是因為原問題中沒有等式約束,只有不等式約束。
是因為原問題中沒有等式約束,只有不等式約束。
下面我們按照對偶問題的求解步驟來一步步進行,
![]()
首先求解![]() 的最小值,對於固定的
的最小值,對於固定的![]() ,
,![]() 的最小值只與w和b有關。對w和b分別求偏導數。
的最小值只與w和b有關。對w和b分別求偏導數。
![clip_image071[6]](http://images.cnblogs.com/cnblogs_com/jerrylead/201103/201103131235339186.png "clip_image071[6]")
![clip_image072[6]](http://images.cnblogs.com/cnblogs_com/jerrylead/201103/201103131235346088.png "clip_image072[6]")
並得到
![clip_image073[6]](http://images.cnblogs.com/cnblogs_com/jerrylead/201103/201103131235346579.png "clip_image073[6]")
將上式帶回到拉格朗日函式中得到,此時得到的是該函式的最小值(目標函式是凸函式)
代入後,化簡過程如下:


最後得到
![clip_image074[6]](http://images.cnblogs.com/cnblogs_com/jerrylead/201103/201103131235354876.png "clip_image074[6]")
由於最後一項是0,因此簡化為
![clip_image075[6]](http://images.cnblogs.com/cnblogs_com/jerrylead/201103/201103131235352302.png "clip_image075[6]")
這裡我們將向量內積![]() 表示為
表示為![]()
此時的拉格朗日函式只包含了變數![]() 。然而我們求出了
。然而我們求出了![]() 才能得到w和b。
才能得到w和b。
接著是極大化的過程![]() ,
,
![clip_image078[6]](http://images.cnblogs.com/cnblogs_com/jerrylead/201103/201103131235392986.png "clip_image078[6]")
前面提到過對偶問題和原問題滿足的幾個條件,首先由於目標函式和線性約束都是凸函式,而且這裡不存在等式約束h。存在w使得對於所有的i,![]() 。因此,一定存在
。因此,一定存在![]() 使得
使得![]() 是原問題的解,
是原問題的解,![]() 是對偶問題的解。在這裡,求
是對偶問題的解。在這裡,求![]() 就是求
就是求![]() 了。
了。
如果求出了![]() ,根據
,根據![clip_image083[6]](http://images.cnblogs.com/cnblogs_com/jerrylead/201103/201103131235468704.jpg "clip_image083[6]") 即可求出w(也是
即可求出w(也是![]() ,原問題的解)。然後
,原問題的解)。然後
![]()
即可求出b。即離超平面最近的正的函式間隔要等於離超平面最近的負的函式間隔。
關於上面的對偶問題如何求解,將留給下一篇中的SMO演算法來闡明。
這裡考慮另外一個問題,由於前面求解中得到
![clip_image086[6]](http://images.cnblogs.com/cnblogs_com/jerrylead/201103/20110313123548981.png "clip_image086[6]")
我們通篇考慮問題的出發點是![]() ,根據求解得到的
,根據求解得到的![]() ,我們代入前式得到
,我們代入前式得到
![clip_image089[6]](http://images.cnblogs.com/cnblogs_com/jerrylead/201103/201103131235502419.png "clip_image089[6]")
也就是說,以前新來的要分類的樣本首先根據w和b做一次線性運算,然後看求的結果是大於0還是小於0,來判斷正例還是負例。現在有了![]() ,我們不需要求出w,只需將新來的樣本和訓練資料中的所有樣本做內積和即可。那有人會說,與前面所有的樣本都做運算是不是太耗時了?其實不然,我們從KKT條件中得到,只有支援向量的
,我們不需要求出w,只需將新來的樣本和訓練資料中的所有樣本做內積和即可。那有人會說,與前面所有的樣本都做運算是不是太耗時了?其實不然,我們從KKT條件中得到,只有支援向量的![]() ,其他情況
,其他情況![]() 。因此,我們只需求新來的樣本和支援向量的內積,然後運算即可。這種寫法為下面要提到的核函式(kernel)做了很好的鋪墊。這是上篇,先寫這麼多了。
。因此,我們只需求新來的樣本和支援向量的內積,然後運算即可。這種寫法為下面要提到的核函式(kernel)做了很好的鋪墊。這是上篇,先寫這麼多了。
SMO演算法由Microsoft Research的John C. Platt在1998年提出,併成為最快的二次規劃優化演算法,特別針對線性SVM和資料稀疏時效能更優。關於SMO最好的資料就是他本人寫的《Sequential Minimal Optimization A Fast Algorithm for Training Support Vector Machines》了。
我拜讀了一下,下面先說講義上對此方法的總結。
首先回到我們前面一直懸而未解的問題,對偶函式最後的優化問題:

要解決的是在引數![]() 上求最大值W的問題,至於
上求最大值W的問題,至於![]() 和
和![]() 都是已知數。C由我們預先設定,也是已知數。
都是已知數。C由我們預先設定,也是已知數。
按照座標上升的思路,我們首先固定除![]() 以外的所有引數,然後在
以外的所有引數,然後在![]() 上求極值。等一下,這個思路有問題,因為如果固定
上求極值。等一下,這個思路有問題,因為如果固定![]() 以外的所有引數,那麼
以外的所有引數,那麼