
資料探勘中的模式發現(五)挖掘多樣頻繁模式
挖掘多層次的關聯規則(Mining Multi-Level Associations)
定義
項經常形成層次。
如圖所示
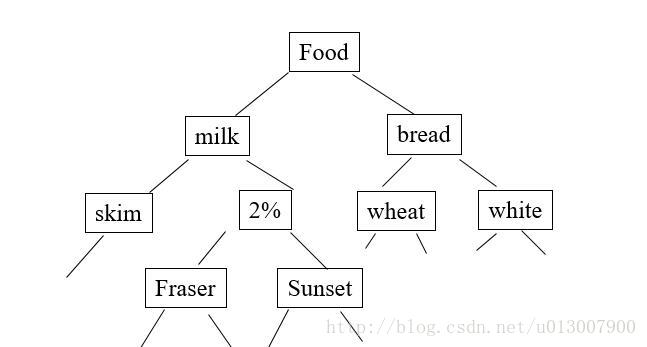
那麼我們可以根據項的細化分類得到更多有趣的模式,發現更多細節的特性。
Level-reduced min-support
使用的是Level-reduced min-support方法來設定最低支援度,即,越低的層有著越低的支援度。
假設我們使用的是統一的最低支援度,那麼如果支援度過低,低層的頻繁項集就會較少,導致很多特性顯示不出來;如果支援度過高,高層的頻繁項集就過多,導致過多無用的特性被展示出來。
group-based “individualized” min-support
不同種類的物品對應的最低支援度應該是不同的,比如鑽石等貴重物品出現的頻率肯定是低於牛奶麵包等日常用品的。
所以應該分組設定最低支援度。
Shared multi-level mining
使用最低層次的支援度來計算和傳遞候選集。也就是使用的是所有層中支援度最小的。
因為這樣可以保證挖掘出的關聯規則不會減少。
冗餘規則(redundant rules)
挖掘多層關聯規則時,由於項之間的“父子”關係,有些發現的規則是冗餘的。
例如
已知,
我們可以發現,第一個規則是第二個規則的祖先。而我們可以根據第一個規則的值以及比例放縮,計算出第二個規則的期望。而如果一個規則的支援度和置信度都接近“期望值”,那麼我們稱之為冗餘規則。
挖掘多維度的關聯規則(Mining Multi-Dimensional Associations)
- 單維規則:
buys(X,"milk")→buys(X,"bread") - 可寫成形如
milk→bread 的boolean關聯規則
- 多維規則:2維 或者 斷言
- 維間關聯規則 (no repeated predicates)
a ge(X,"19−25")∧occupation(X,"student")→buys(X,"coke")
- 混合維關聯規則 (repeated predicates)
age(X,"19−25")∧buys(X,"popcorn")→buys(X,"coke")
- 維間關聯規則 (no repeated predicates)
- 分類屬性
- 具有有限個不同值,沒有排序
- 定量屬性
- 數值的, 並在數值間具有隱含的序
挖掘量化關聯規則(Mining Quantitative Associations)
定義
量化關聯指的是具有數字資料的屬性,例如,年齡、工資等。
靜態離散化(static discretization)
簡單來說就是使用取值範圍替代數值。
這裡使用取值範圍的原因和ID3和C4.5對於離散數字的處理有關,如果你要考慮每一個年齡,或者每一個薪酬,那麼項的種類就會過於豐富,從而導致我們不能敏感地發現有價值的關聯規則。
但是,如果我們使用十年,或者五年作為一次年齡的分割,我們就可以將項的種類縮小,而每個項出現的頻率增加。
資料立方(data cube)
使用一些預定義的層次結構概念,再加上靜態的離散化,我們可以得到類似下圖的資料立方體。從而更好地實現挖掘功能。
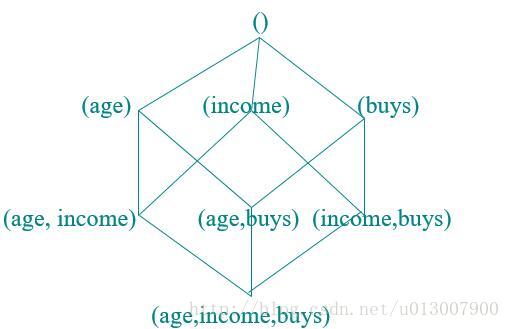
當然,這是固定的分類或者量化方法,也可以通過聚類將某一具體的資料進行分類,從而動態地決定量化方法。
偏差分析(deviation analysis)
用的是統計學的方法進行分析,一般是使用平均值或者中位數等等,然後根據規則和平均值的偏差來挖掘的。
當然,我們也要通過一些統計學的測試來證明這個規則有著較高的可信度,而不僅僅一個例外。
挖掘負相關(Mining Negative Correlations)
罕見模式(Rare Pattern)
它們很少發生,有著較低的支援度,但是它們還是很有趣的。
比如,我們買了周大生的珠寶,雖然很少發生,但是我們需要這方面的規則。
那麼,之前說過需要使用分組的方式來設定個性化的最低支援度。
負模式(Negative Pattern)
基於支援度的定義(support-based definition)
負相關項集 項集X是負相關的,如果
s(x)是給出了X的所有項統計獨立的概率估計。如果它的支援度小於使用統計獨立性假設計算出的期望支援度。s(X)越小,模式就越負相關。簡單來說,就是這兩個事件不太會同時發生。
基於Kulczynski測量的定義
如果兩個項集A和B,有如下關係
則稱其為負相關。(其中
負相關關聯規則
規則
其中
其中
是負相關的,但是其中項集內的項之間是負相關的,眼鏡盒鏡頭清潔劑是負相關的,如果使用完全條件,可能就不能發現該規則了。
負相關條件也可以用正項集和負項集的支援度表示