
[Big Data]菜鳥的Hadoop (Before YARN) 學習筆記 (一) WordCount
菜鳥的Hadoop (Before YARN)學習筆記(一) WordCount
配置之後再補。先行略過。之前花了挺多時間在配置,但是手一抖沒Mark Down,實在後悔。
1. New a project
OK. Finish.
2. Project Structure and Coding
可以看到,其實Mapreduce已經很自動地把要用的JAR等等必要的資原始檔放一起了。
那這裡會有一個示例的WordCount.
來自Hadoop Source Examples,,可能有不同版本,不過實現原理一致。
- package com.wordCount;
- import java.io.IOException;
- import java.util.StringTokenizer;
- importorg.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- importorg.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- importorg.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- importorg.apache.hadoop.util.GenericOptionsParser;
- public class WordCount {
- public static class TokenizerMapper
- extends Mapper<Object, Text, Text, IntWritable>{
- //TokenizerMapper 繼承自 Mapper<Object, Text, Text, IntWritable>
- //LongWritable, IntWritable, Text 用於封裝資料型別,以便序列化從而便於在分散式環境中進行資料交換,應可理解為long ,int, string 。
- //在MapReduce中,Mapper從一個輸入分片中讀取資料,然後經過Shuffle and Sort階段分發資料給Reducer.
- // Map函式接收一個<key,value>形式的輸入,然後同樣產生一個<key,value>形式的中間輸出,Hadoop函式接收一個如<key,(list of values)>形式的輸入,然後對這個value集合進行處理,每個reduce產生0或1個輸出,reduce的輸出也是<key,value>形式的。
- //Map類繼承自MapReduceBase,並且它實現了Mapper介面,Mapper介面是一個規範型別,它有4種形式的引數,分別用來指定map的輸入key值型別、輸入value值型別、輸出key值型別和輸出value值型別。在本例中,因為使用的是TextInputFormat,它的輸出key值是LongWritable型別,輸出value值是Text型別,所以map的輸入型別為<LongWritable,Text>。在本例中需要輸出<word,1>這樣的形式,因此輸出的key值型別是Text,輸出的value值型別是IntWritable。
- // 簡單說應該是,根據需求定義型別:
- // Object Input key Type:
- // Text Input value Type:
- // Text Output key Type:
- // IntWritable Output value Type:
- private final static IntWritable one = new IntWritable(1);
- private Text word = new Text();
- // New one & word.
- public void map(Object key, Text value, Context context
- ) throws IOException, InterruptedException{
- StringTokenizer itr = new StringTokenizer(value.toString());
- while (itr.hasMoreTokens()) {
- word.set(itr.nextToken());
- context.write(word, one);
- }
- }
- }
- // 資料對(K/V)是從傳入的Context獲取的。我們也可以從map方法看出,輸出結果K/V對也是通過Context來完成的。 在前期的例子中使用的是void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter)
- // public StringTokenizer(String str,String delim, boolean returnDelims)
- 第一個引數就是要分隔的String,第二個是分隔字元集合,第三個引數表示分隔符號是否作為標記返回,如果不指定分隔字元,預設的是:”\t\n\r\f”
- // boolean hasMoreTokens() :返回是否還有分隔符
- // String nextToken():返回從當前位置到下一個分隔符的字串。
- // context.write(key, value);
- public static class IntSumReducer
- extends Reducer<Text,IntWritable,Text,IntWritable> {
- private IntWritable result = new IntWritable();
- // New a intWritable 作為結果
- public void reduce(Text key, Iterable<IntWritable> values,
- Context context
- ) throws IOException,InterruptedException {
- int sum = 0;
- for (IntWritable val : values) {
- sum += val.get();
- }
- result.set(sum);
- context.write(key, result);
- }
- }
- // IntSumReducer 繼承自 Reducer<Text,IntWritable,Text,IntWritable>
- //引數的理解也是一樣的,inputtext/ IntWritable output text/IntWritable
- //重寫reduce輸出結果,迴圈所有的map值,把word ==> one 的key/value對進行彙總
- // Map過程輸出<key,values>中key為單個單詞,而values是對應單詞的計數值所組成的列表,Map的輸出就是Reduce的輸入,所以reduce方法只要遍歷values並求和,即可得到某個單詞的總次數。
- public static void main(String[] args) throws Exception {
- Configuration conf = new Configuration();
- String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
- if (otherArgs.length != 2) {
- System.err.println("Usage: wordcount <in> <out>");
- System.exit(2);
- }
- Job job = new Job(conf, "word count");
- job.setJarByClass(WordCount.class); //指定主類
- job.setMapperClass(TokenizerMapper.class);
- job.setCombinerClass(IntSumReducer.class);
- job.setReducerClass(IntSumReducer.class);
- job.setOutputKeyClass(Text.class); //設定輸出資料的關鍵字類
- job.setOutputValueClass(IntWritable.class);
- //以上也是為了設定各自的類
- FileInputFormat.addInputPath(job, new Path(otherArgs[0])); //檔案輸入
- FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); //檔案輸出
- System.exit(job.waitForCompletion(true) ? 0 : 1);
- }
- }
- //以上是執行。首先是Configurationconf = new Configuration();初始化配置類。
- // GenericOptionsParser是hadoop框架中解析命令列引數的基本類。它能夠辨別一些標準的命令列引數,能夠使應用程式輕易地指定namenode,jobtracker,以及其他額外的配置資源。
- //getRemainingArgs 限制命令列輸入引數,取其陣列長度不為2的話報錯退出。
- // public String[]getRemainingArgs()
- Returns an array of Strings containing onlyapplication-specific arguments.
- Returns:
- array of Strings containing theun-parsed arguments or empty array if commandLine was not defined.
- //任務的輸出和輸入路徑則由命令列引數指定
- // waitForCompletion開始
三.圖解
以下摘自蝦皮工作室
http://www.cnblogs.com/xia520pi/archive/2012/05/16/2504205.html
多謝作者的講解。
1)將檔案拆分成splits,由於測試用的檔案較小,所以每個檔案為一個split,並將檔案按行分割形成<key,value>對,如圖4-1所示。這一步由MapReduce框架自動完成,其中偏移量(即key值)包括了回車所佔的字元數(Windows和Linux環境會不同)。
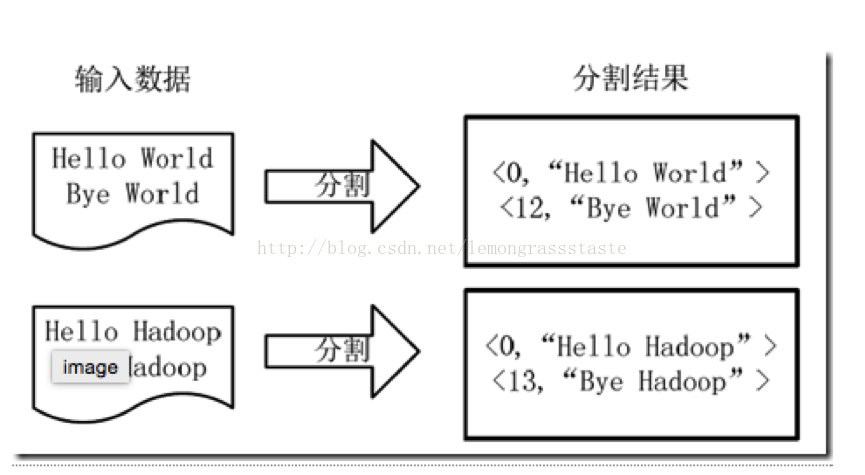
圖4-1 分割過程
2)將分割好的<key,value>對交給使用者定義的map方法進行處理,生成新的<key,value>對,如圖4-2所示。
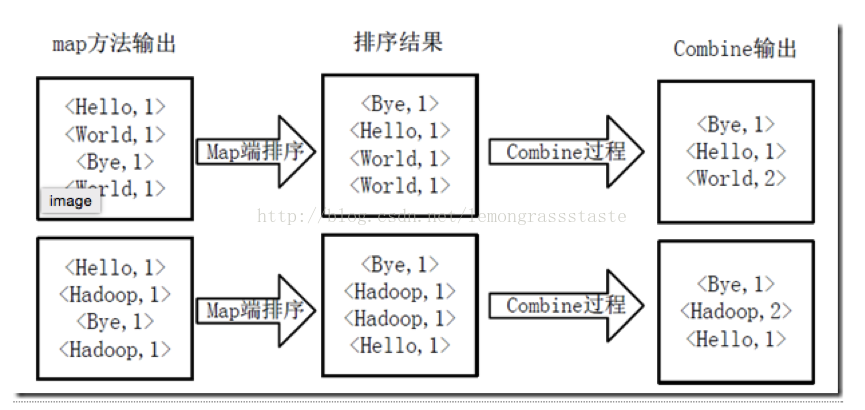
圖4-2 執行map方法
3)得到map方法輸出的<key,value>對後,Mapper會將它們按照key值進行排序,並執行Combine過程,將key至相同value值累加,得到Mapper的最終輸出結果。如圖4-3所示。
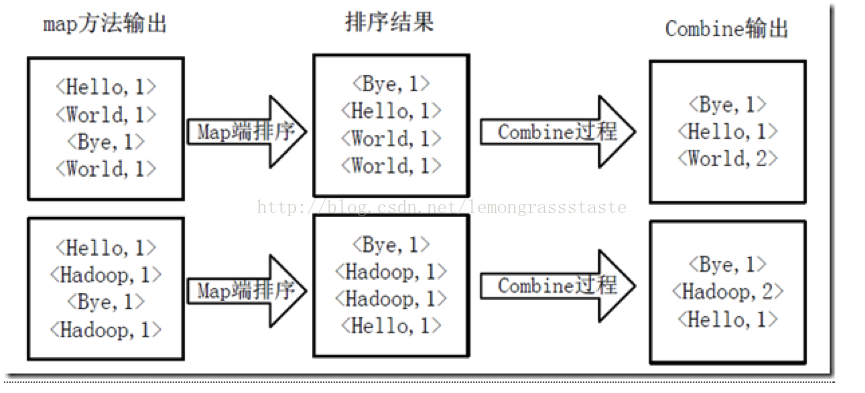
圖4-3 Map端排序及Combine過程
4)Reducer先對從Mapper接收的資料進行排序,再交由使用者自定義的reduce方法進行處理,得到新的<key,value>對,並作為WordCount的輸出結果,如圖4-4所示。
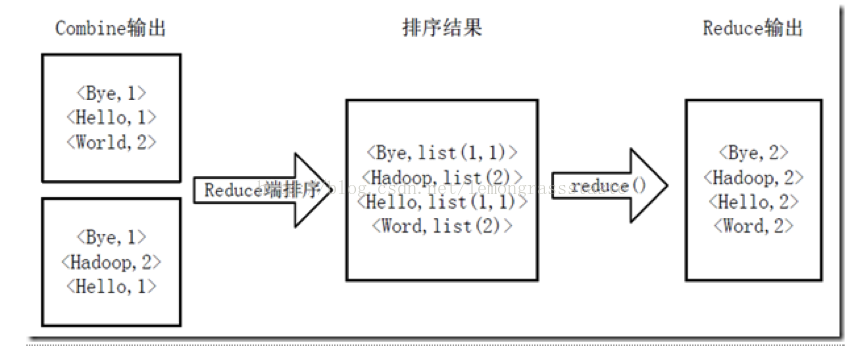
圖4-4 Reduce端排序及輸出結果
四.執行結果
要通過Run Configurations
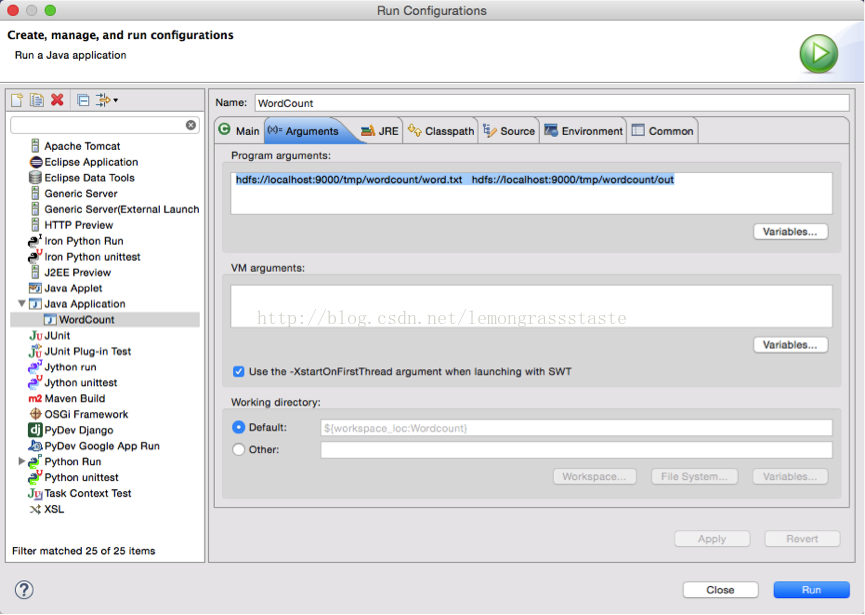
輸入Arguments.
Run at Hadoop
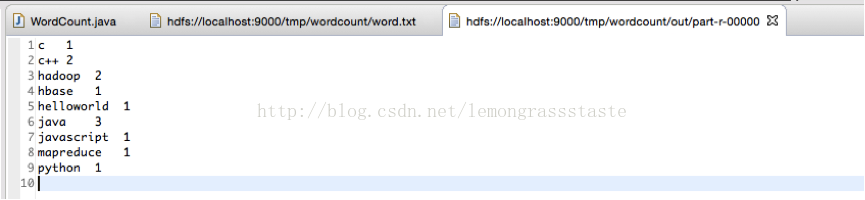
證明成功了。