
資料探勘基礎-1.文字相似度
一、文字相似度
相似度度量指的是計算個體間相似程度,一般使用距離來度量,相似度值越小,距離越大,相似度值越大,距離越小。在說明文字相似度概念和計算方式之前,先回顧下餘弦相似度。
1.餘弦相似度
衡量文字相似度最常用的方法是使用餘弦相似度。
– 空間中,兩個向量夾角的餘弦值作為衡量兩個個體之間差異的大小
– 餘弦值接近1,夾角趨於0,表明兩個向量越相似
– 餘弦值接近0,夾角趨於90,表明兩個向量越不相似


2.計算文字相似度
度量兩篇文文章的相似度流程如下:
思路:1、分詞;2、列出所有詞;3、分詞編碼;4、詞頻向量化;5、套用餘弦函式計量兩個句子的相似度。
下面我們介紹使用餘弦相似度計算兩段文字的相似度的具體例子。
http://www.cnblogs.com/airnew/p/9563703.html
句子A:這隻皮靴號碼大了。那隻號碼合適。
句子B:這隻皮靴號碼不小,那隻更合適。
1、分詞:
使用結巴分詞對上面兩個句子分詞後,分別得到兩個列表:
listA=[‘這‘, ‘只‘, ‘皮靴‘, ‘號碼‘, ‘大‘, ‘了‘, ‘那‘, ‘只‘, ‘號碼‘, ‘合適‘]
listB=[‘這‘, ‘只‘, ‘皮靴‘, ‘號碼‘, ‘不小‘, ‘那‘, ‘只‘, ‘更合‘, ‘合適‘]
2、列出所有詞,將listA和listB放在一個set中,得到:
set={'不小', '了', '合適', '那', '只', '皮靴', '更合', '號碼', '這', '大'}
將上述set轉換為dict,key為set中的詞,value為set中詞出現的位置,即‘這’:1這樣的形式。
dict1={'不小': 0, '了': 1, '合適': 2, '那': 3, '只': 4, '皮靴': 5, '更合': 6, '號碼': 7, '這': 8, '大': 9},可以看出“不小”這個詞在set中排第1,下標為0。
3、將listA和listB進行編碼,將每個字轉換為出現在set中的位置,轉換後為:
listAcode=[8, 4, 5, 7, 9, 1, 3, 4, 7, 2]
listBcode=[8, 4, 5, 7, 0, 3, 4, 6, 2]
我們來分析listAcode,結合dict1,可以看到8對應的字是“這”,4對應的字是“只”,9對應的字是“大”,就是句子A和句子B轉換為用數字來表示。
4、對listAcode和listBcode進行oneHot編碼,就是計算每個分詞出現的次數。oneHot編號後得到的結果如下:
listAcodeOneHot = [0, 1, 1, 1, 2, 1, 0, 2, 1, 1]
listBcodeOneHot = [1, 0, 1, 1, 2, 1, 1, 1, 1, 0]
下圖總結了句子從分詞,列出所有詞,對分詞進行編碼,計算詞頻的過程

5、得出兩個句子的詞頻向量之後,就變成了計算兩個向量之間夾角的餘弦值,值越大相似度越高。
listAcodeOneHot = [0, 1, 1, 1, 2, 1, 0, 2, 1, 1]
listBcodeOneHot = [1, 0, 1, 1, 2, 1, 1, 1, 1, 0]
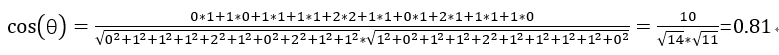
根據餘弦相似度,句子A和句子B相似度很高。
下面講解如何通過一個預料庫,提取出一篇文章的關鍵詞。
二、TF-IDF
關鍵詞可以讓人快速瞭解一篇文章,根據上面分析,如果兩篇文章的關鍵詞是相似的,那麼兩篇文章就很可能是相似的。【當然,讀者可能已經發現,本篇部落格講解的是通過字面來衡量兩篇文章的相似度,而非通過字義角度】通常,使用TF-IDF值來度量一個詞的重要性,該值越大,說明詞越能描述文章的意思,下面具體講解。
1.詞頻TF
如果一個詞很重要,在文章中就會多次出現,這可以用詞頻—TF(Term Frequency)來衡量。
計算公式:
詞頻(TF) = 某個詞在文章中出現的次數/文章的總詞數
或者
詞頻(TF) = 某個詞在文章中出現的次數/該文出現次數最多的詞的出現次數兩個公式的區別是:第二個公式可以將不同詞的TF值拉的更開。舉個例子,假設某篇文章共1000個詞,A出現了10次,B出現了11次,A和B通過公式1計算出的TF值差距很小,假設出現次數最多的詞C出現的次數是100,A和B通過公式2計算出的TF值差距相比更大一些,更有利於區分不同的詞。
在文章中,還存在“的”“是”“在”等常用詞,這些詞出現頻率較高,但是對描述文章並沒有作用,叫做停用詞(stop words),必須過濾掉。同時如果某個詞在語料庫中比較少見,但是它在某文章中卻多次出現,那麼它很可能也反映了這篇文章的特性,這也可能是關鍵詞,所以除了計算TF,還須考慮反文件頻率(idf,inverse document frequency)。
2.反文件頻率IDF
IDF的思想是:在詞頻的基礎上,賦予每個詞權重,進一步體現該詞的重要性。最常見的詞(“的”、“是”、“在”)給予最小的權重,較常見的詞(“國內”、“中國”、“報道”)給予較小的權重,較少見的詞(“養殖”、“維基”)給與較大的權重。
計算公式:
IDF = log(詞料庫的文件總數/包含該詞的文件數+1)TF-IDF與一個詞在文件中的出現次數成正比,與包含該詞的文件數成反比。值越大就代表這個詞越關鍵。
3.應用1-相似文章
使用TF-IDF演算法,可以找出兩篇文章的關鍵詞;可以設定一個閥值,超過該值的認定為關鍵詞,或者取值排名靠前的n個詞作為關鍵詞。
每篇文章各取出若干個關鍵詞(比如20個),合併成一個集合,計算每篇文章對於這個集合中的詞的詞頻(為了避免文章長度的差異,可以使用相對詞頻,即除以對應文章的總詞數,相當於對詞頻進行了標準化處理)。
生成兩篇文章各自的詞頻向量,計算兩個向量的餘弦相似度,值越大就表示越相似。
4.應用2-自動摘要
文章的資訊都包含在句子中,有些句子包含的資訊多,有些句子包含的資訊少。"自動摘要"就是要找出包含資訊最多的句子。句子的資訊量用"關鍵詞"來衡量。如果包含的關鍵詞越多,就說明這個句子越重要。
只要關鍵詞之間的距離小於“門檻值”,就認為處於同一個簇之中,如果兩個關鍵詞距離有5個詞以上(值可調整),就把這兩個關鍵詞分在兩個不同的簇中。
對於每個簇,計算它的重要性分值。

例如:其中的某簇一共有7個詞,其中4個是關鍵詞。因此,它的重要性分值等於 ( 4 x 4 ) / 7 =2.3
簡化做法:不再區分"簇",只考慮句子包含的關鍵詞。
三、TF-IDF的Python實現
下面使用Python計算TF-IDF,前提是有一個預料庫。這裡總共有508篇文章,每篇文章中,都已經提前做好了分詞。

1.計算IDF
思路:將語料庫中的每篇文章放入各自的set集合中,再設定一個大的set,將之前各篇文章的set集合依次放入這個大的set中,得到的即每個詞以及詞出現的次數,詞對應的次數即擁有該詞的文章數。
1)convert.py
import os
import sys
files_dir = sys.argv[1] //獲得輸入的引數,即語料庫路徑
for file_name in os.listdir(files_dir): //函式會返回目錄下面的所有檔名稱
file_path = files_dir + file_name
file_in = open(file_path, 'r') //將文章內容讀取到file_in中,即獲得輸入流
tmp_list = [] //將每個文章的每一段內容都放在陣列tmp_list中
for line in file_in: //一行一行地讀取
tmp_list.append(line.strip())
print '\t'.join([file_name, ' '.join(tmp_list)]) //檔名和檔案內容按照tab符號分割,每個文章內部的每一段按照空格連線起來,最後會只形成一段。[[email protected] 5_codes]# python convert.py /usr/local/src/code/5_codes/input_tfidf_dir/ > convert.data #將內容輸出到一個檔案中
[[email protected] 5_codes]# head -1 convert.data //可以內容,驗證結果
這個時候,即將所有文章整合到一個convert.data檔案中,每一段都代表一篇文章的詞,且詞不重複。
2)map.py
通過conver.py,獲取到了所有文章的詞彙,接下就需要將所有的詞取出來,並且儲存到一個大的set集合中,計算擁有該詞的文章數。為此,我們將通過map和reduce兩個步驟分別進行,目的是為了使程式能夠通過hadoop的MapReduce進行分散式運算(當語料庫非常大的時候,這是非常有必要的,如果僅僅是為了實踐如何計算TF-IDF,也可以將這兩步合併成一步,通過一臺電腦進行計算)。
import sys
for line in sys.stdin: //map是通過標準輸入讀到資料,將convert.data內容讀進去
ss = line.strip().split('\t') //ss為每篇文章的名稱和屬於這篇文章的所有詞
file_name = ss[0].strip()
file_context = ss[1].strip()
word_list = file_context.split(' ') //將文字內容按照空格分割
word_set = set()
for word in word_list: #這步是為了去重
word_set.add(word)
for word in word_set:
print '\t'.join([word, '1']) //這裡輸出的是每個文章的不同的字的,只統計是否有,為了給red中的計算做準備[[email protected] 5_codes]# cat convert.data | python map.py >map.data
3)red.py
經過map後,再通過reduce計算詞的文章數。這裡需要注意的是,將map.data的資料輸入到red.py前,需要先進行排序,在hadoop的MapReduce中,這個步驟將會自動完成,但是在使用MapReduce前,我們本地驗證時候將通過sort命令進行排序。
import sys
import math
current_word = None
doc_cnt = 508 //文章總篇數
sum = 0
for line in sys.stdin:
ss = line.strip().split('\t')
if len(ss)!=2: //判斷格式是否是正確的
continue
word,val = ss
if current_word == None:
current_word = word
if current_word != word: //如果讀進來的單詞和之前的不一致,說明之前的已經讀完,可以開始計算idf值
idf_score = math.log(float(doc_cnt)/(float(sum+1)))
print '\t'.join([current_word,str(idf_score)])
current_word = word
sum = 0
sum = sum+1
//這裡要計算最後一個詞的idf詞
idf_score = math.log(float(doc_cnt)/(float(sum+1)))
print '\t'.join([current_word,str(idf_score)])[[email protected] 5_codes]# cat map.data | sort -k1 | python red.py > myred.tmp
[[email protected] 5_codes]# cat myred.tmp | sort -k2 -nr > result.data 按照分值,從大到小排序
2.計算TF
1)mp_tf.py
import sys
word_dict = {}
idf_dict = {}
def read_idf_func(idf): #讀取idf值檔案的函式
with open(idf,'r') as fd:
for line in fd:
kv=line.strip().split('\t')
idf_dict[kv[0].strip()] =float(kv[1].strip())
return idf_dict
def mapper_func(idf):
idf_dict = read_idf_func(idf)
for line in sys.stdin:
ss = line.strip().split('\t')
fn = ss[0].strip()
fc = ss[1].strip()
word_list = fc.split(' ')
cur_word_num = len(word_list)
for word in word_list:
if word not in word_dict:
word_dict[word]=1
else:
word_dict[word]+=1
for k,v in word_dict.items():
if k!='':#判斷key是否為空格
print fn, k, float(v/float(cur_word_num)*idf_dict[k])
if __name__ == "__main__": #函式模組化,
module = sys.modules[__name__]
func = getattr(module, sys.argv[1])
args = None
if len(sys.argv) > 1:
args = sys.argv[2:]
func(*args)[[email protected] 5_codes]# cat convert.data | python mp_tf.py mapper_func result.data這裡需要注意,在上面的程式碼中,用 if k!='':對key進行了判斷,如果不進行判斷,則會出現如下的錯誤。

原因是在形成convert.data的時候出了問題,在某個文章中兩個單詞之間存在兩個空格。而計算出的result.data中並不包含空格的idf值,因為在計算這個idf前,通過如下程式碼將空格過濾掉了。
if len(ss)!=2: //判斷格式是否是正確的
continue解決的辦法就是忽略文章中的空格,因此加入了if k!='':,若是空格就忽略掉。
四、LCS
1.概念
最長公共子序列(Longest Common Subsequence),一個序列S任意刪除若干個字元得到的新序列T,則T叫做S的子序列。
兩個序列X和Y的公共子序列中,長度最長的那個,定義為X和Y的最長公共子序列。
- 字串12455與245576的最長公共子序列為2455
- 字串acdfg與adfc的最長公共子序列為adf
最長公共子串(Longest Common Substring)與最長公共子序列不同的是,最長公共子串要求字元相鄰。
2.作用
1)生物學家常利用最長的公共子序列演算法進行基因序列比對,以推測序列的結構、功能和演化過程。
2)描述兩段文字之間的“相似度”。
辨別抄襲,對一段文字進行修改之後,計算改動前後文字的最長公共子序列,將除此子序列外的部分提取出來,該方法判斷修改的部分。
3)可以推薦不同型別的事物,增強使用者體驗。
3.求解—暴力窮舉法
• 假定字串X,Y的長度分別為m,n;
• X的一個子序列即下標序列{1,2,……,m}嚴格遞增子序列,因此,X共有2的m次方個不同子序列;同理,Y有2的n次方個不同子序列;(每個字元都對應著刪除或者不刪除,所以可以有如上的不同子序列個數)
• 窮舉搜尋法時間複雜度O(2的m次方 ∗ 2的n次方);
• 對X的每一個子序列,檢查它是否也是Y的子序列,從而確定它是否為X和Y的公共子序列,並且在檢查過程中選出最長的公共子序列,也就是說要遍歷所有的子序列。
• 複雜度高,不可用!
4.求解—動態規劃
• 字串X,長度為m,從1開始數;
• 字串Y,長度為n,從1開始數;
• Xi=<x1,……,xi>即X序列的前i個字元(1<=i<=m)(Xi計作“字串X的i字首” )
• Yj=<y1,……,yj>即Y序列的前i個字元(1<=j<=n)(Yj計作“字串Y的j字首” )
• LCS(X,Y)為字串X和Y的最長公共子序列,即為Z=<z1,……,zk>
• 如果xm = yn(最後一個字元相同),則:Xm與Yn的最長公共子序列Zk的最後一個字元肯定是xm(=yn),所以zk=xm=yn,因此有LCS(Xm,Yn)= LCS(Xm-1,Yn-1)+xm。
• 如果xm ≠ yn,則LCS(Xm, Yn)=LCS(Xm−1, Yn),或者LCS(Xm, Yn)=LCS(Xm, Yn−1)
• 即LCS(Xm, Yn)=max{LCS(Xm−1, Yn), LCS(Xm, Yn−1)}

使用二維陣列C[m,n],C[i,j]記錄序列Xi和Yj的最長公共子序列的長度,因此得到C[m,n]的值時,即得到最長公共子序列的長度。當i=0或j=0時,空序列是Xi和Yj的最長公共子序列,故C[i,j]=0。

舉例:計算X=<A, B, C, B, D, A, B> 和Y=<B, D, C, A, B, A>的最長公共子串。按照公式逐漸遞推到X和Y的首個字母, 接著從兩個序列的首個字母開始回溯,最終計算出結果。具體過程如下:
X0=0或Y0=0時,LCS=0,因此第一行和第一列都是0。接下來從(1,1)位置開始,按照從坐到右,上到下的順序,一行一行地判斷。
判斷X1=A和Y1=B不一樣,所以LCS(X1,Y1)=max{LCS(X0,Y1),LCS(X1,Y0)}=0。
接下來判斷(1,2)位置的LCS值,根據公式,由於A和B元素不同,因此呼叫第3個公式,即取該點左邊和上面點的最大值,由於此時最大值都是0,所以(1,2)位置的LCS值為0;同理一直到(1,4),由於A和A相同,因此呼叫第2個公式,即左上角的LCS值+1,因此可以得到C(1,2)=1。
以此類推,最終就可以得到C(7,6)的值,該值為4,即兩個序列的最長公共子序列為4。

5.LCS的Python實現
首先準備一個輸入資料,該檔案中每行有兩句,中間用製表符分隔。

1)map.py
import sys
def cal_lcs_sim(first_str, second_str):
len_vv = [[0] * 50] * 50 // 50*50的矩陣,保證夠大就行
first_str = unicode(first_str, "utf-8", errors='ignore') //設定支援中文,否則會出現亂碼
second_str = unicode(second_str, "utf-8", errors='ignore')
len_1 = len(first_str.strip())
len_2 = len(second_str.strip())
//從左到右,從上到下計算最長公共子串
for i in range(1, len_1 + 1):
for j in range(1, len_2 + 1):
if first_str[i - 1] == second_str[j - 1]: //如果相等,則對角線的值+1,這裡i,j的範圍從1到len+1,是為了防止在計算[0][0]時,出現越界。
len_vv[i][j] = 1 + len_vv[i - 1][j - 1]
else:
len_vv[i][j] = max(len_vv[i - 1][j], len_vv[i][j - 1])
return float(float(len_vv[len_1][len_2] * 2) / float(len_1 + len_2)) //相似度公式可以自定義
//計算框架的入口,接收輸入的文字資料
for line in sys.stdin:
ss = line.strip().split('\t')
if len(ss) != 2:
continue
first_str = ss[0].strip()
second_str = ss[1].strip()
sim_score = cal_lcs_sim(first_str, second_str)
print '\t'.join([first_str, second_str, str(sim_score)])2)run.sh
HADOOP_CMD="/usr/local/src/hadoop-1.2.1/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar" #這是hadoop1.0採用的hadoop-streaming的jar包
#HADOOP_CMD="/usr/local/src/hadoop-2.6.1/bin/hadoop"
#STREAM_JAR_PATH="/usr/local/src/hadoop-2.6.1/share/hadoop/tools/lib/hadoop-streaming-2.6.1.jar" #這是hadoop2.0採用的hadoop-streaming的jar包
INPUT_FILE_PATH_1="/lcs_input.data"
OUTPUT_PATH="/lcs_output"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH
# Step 1.
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH_1 \
-output $OUTPUT_PATH \
-mapper "python map.py" \
-jobconf "mapred.reduce.tasks=0" \
-jobconf "mapred.job.name=mr_lcs" \
-file ./map.py最終在hdfs上可以看到生成了/lcs_output的資料夾,檢視內部檔案,檢查結果。
