
深入理解java虛擬機器學習筆記(六)
第八章 虛擬機器位元組碼執行引擎
8.1概述
執行引擎是Java虛擬機器最核心的組成部分之一。“虛擬機器”是一個相對於“物理機”的概念,這兩種機器都有執行程式碼的能力,其區別是物理機的執行引擎是直接建立在處理器、硬體、指令集和作業系統層面上的,而虛擬機器的執行引擎則是由自己實現的,因此可以自行制定指令集與執行引擎的結構體系,並能夠執行那些不被硬體直接支援的指令集格式。
在Java虛擬機器規範中制定了虛擬機器位元組碼執行引擎的概念模型,這個概念模型成為各種虛擬機器執行引擎的統一外觀。在不同的虛擬機器實現裡面,執行引擎在執行Java程式碼的時候可能會有解釋執行(通過直譯器執行)和編譯執行(通過即時編譯器產生程式碼執行)兩種選擇,也可能兩者兼備,甚至還可能會包含幾個不同級別的編譯器執行引擎。但從外觀上看起來,所有的Java虛擬機器的執行引擎都是一致的:輸入的是位元組碼,處理過程是位元組碼解析的等效過程,輸出的是執行結果,本章將主要從概念模型的角度來講解虛擬機器的方法呼叫和位元組碼執行。
8.2執行時棧幀結構
棧幀(Stack Frame)是用於支援虛擬機器執行方法呼叫和方法執行的資料結構,它是虛擬機器執行時資料區中的虛擬機器棧(Virtual Machine Stack)的棧元素。棧幀儲存了方法的區域性變量表、運算元棧、動態連線和方法返回地址等資訊。每一個方法從呼叫開始至執行完成的過程,都對應著一個棧幀在虛擬機器棧裡面從入棧到出棧的過程。
每一個棧幀都包括了局部變量表、運算元棧、動態連線和方法返回地址和一些附加資訊。在編譯程式程式碼的時候,棧幀中需要多大的區域性變量表,多深的運算元棧都已經完全確定了,並且寫入到方法表的Code屬性中,因此一個棧幀需要分配多少記憶體,不會受到程式執行期變數資料的影響,而僅取決於具體的虛擬機器實現。
一個執行緒中的方法呼叫鏈可能會很長,很多方法都同時處於執行狀態。對於執行引擎來說,在活動執行緒中,只有處於棧頂的棧幀才是有效的,稱為當前棧幀(Current Stack Frame),與這個棧幀相關聯的方法稱為當前方法(Current Method)。執行引擎執行的所有位元組碼指令都只針對當前棧幀進行操作,在概念模型上,典型的棧幀結構如下:
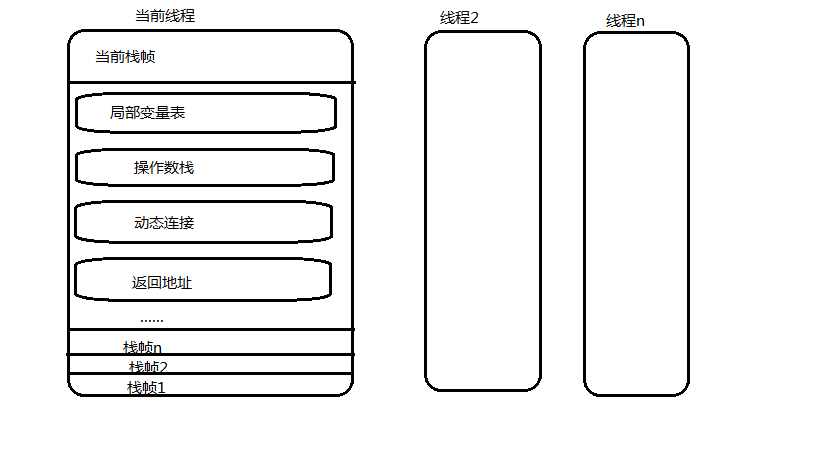
接下來詳細講解一下棧幀中的區域性變量表、運算元棧、動態連線、方法返回地址等各個部分的作用和資料結構。
8.2.1區域性變量表
區域性變量表(Local Variable Table)是一組變數值儲存空間,用於存放方法引數和方法內部定義的區域性變數。在Java程式編譯為Class檔案時,就在方法表的Code屬性的max_locals資料項中確定了該方法所需要分配的區域性變量表的最大容量。
區域性變量表以變數槽(Variable Slot,下面簡稱Slot)為最小單位,虛擬機器規範中並沒有明確指明一個Slot應占用的記憶體空間大小,只是很有導向性地說到每個Slot都應該能存放一個boolean、byte、char、short、int、float、reference或returnAddress型別的資料,這8中資料型別,都可以使用32位或更小的實體記憶體來存放,但這種描述與明確指出“每一個Slot佔用32位的記憶體空間”是有一些差別的,它允許Slot的長度隨著處理器、作業系統或虛擬機器的不同而發生變化。只要保證即使在64位虛擬機器中使用了64位的實體記憶體空間去實現一個Slot,虛擬機器仍要使用對齊和補白的手段讓Slot在外觀上看起來與32位虛擬機器中的一致。
一個Slot可以存放一個32位以內的資料型別,Java中佔用32位以內的資料型別有boolean、byte、char、short、int、float、reference和returnAddress8種類型。前面6種可以按照Java語言中對應的資料型別的概念去理解它們(僅是這樣理解而已,Java語言與Java虛擬機器中的基本資料型別是存在本質差別的),而第7種reference型別表示對一個物件例項的引用,虛擬機器規範既沒有說明它的長度,也沒有明確指出這種引用應該具有怎樣的結構。但一般來說,虛擬機器實現至少都應當能通過這個引用做到兩點,一是從此引用能直接或間接的查詢到物件在Java堆中的資料存放的起始地址索引,二是此引用中直接或間接地查詢到物件所屬資料型別在方法區中儲存的型別資訊,否則無法實現在Java語言規範中定義的語法約束。第8種即returnAddress型別目前已經很少見了,它是為位元組碼指令jsr、jsr_w和ret服務的,指向了一條位元組碼指令的地址,很古老的Java虛擬機器曾經使用這幾條指令來實現異常處理,現在已經由異常表代替。
對於64位的資料型別,虛擬機器會以高位對齊的方式為其分配兩個連續的Slot空間。Java語言中明確的(reference型別則可能是32位也可能是64位)64位的資料型別只有long和double兩種。值得一提的是,這裡把long和double資料型別分割儲存的做法與“long和double的非原子協定”中把一次long和double資料型別讀寫分割為兩次32位讀寫的做法有些類似。不過,由於區域性變量表是建立線上程堆疊上,是執行緒私有的資料,無論讀寫兩個連續的Slot是否為原子操作,都不會引起資料安全問題。
虛擬機器通過索引定位的方式使用區域性變量表,索引值的範圍是從0開始至區域性變量表最大的Slot數量。如果訪問的是32位資料型別的變數,索引n就代表了使用第n個Slot,如果是64位資料型別的變數,則說明會同時n和n+1兩個Slot。對於兩個相鄰的共同存放一個64位資料的兩個Slot,不允許單獨訪問其中的任何一個,Java虛擬機器規範明確要求瞭如果進行這種操作的位元組碼序列,虛擬機器應該在類載入的校驗階段丟擲異常。
在方法執行時,虛擬機器是使用區域性變量表完成引數值到引數變數列表的傳遞過程的,如果執行的是例項方法(非static方法),那區域性變量表中第0位索引的Slot預設就是用於傳遞方法所屬物件例項的引用,在方法中通過關鍵字“this”來訪問這個隱含引數。其餘引數按照引數列表順序排列,佔用從1開始的區域性變數Slot,引數表分配完畢後,再根據方法體內部定義的區域性變數順序和作用域分配其餘Slot。
為了儘可能節省棧幀空間,區域性變量表中的Slot是可以重用的,方法體中定義的變數,其作用域並不一定會覆蓋整個方法體,如果當前位元組碼PC計數器的值已經超過了某個變數的作用域,那麼這個變數對於的Slot就可以交給其他變數使用,不過這樣的設計處理節省棧幀空間外,還會伴隨一些額外的副作用,例如,某些情況下,棧幀的複用會直接影響到系統的垃圾回收行為,如下程式碼所示。package org.administrator.classexec;
/**
* -verbose:gc
* @author Administrator
*
*/
public class LocalVarTable {
public static void main(String []args){
byte []placeholder=new byte[64*1024*1024];
System.gc();
}
}
上面程式碼的邏輯很簡單,就是向記憶體填充了64MB的資料,然後通知虛擬機器進行垃圾回收。我們在虛擬機器執行引數中加上“-verbose:gc”來看看垃圾收集的過程,發現在System.gc()執行後並沒有回收這64MB記憶體,仍然佔用在老年代,下面是執行結果:
[GC(System.gc()) [PSYoungGen: 70481K->648K(92160K)] 70481K->66192K(158720K), 0.0673999 secs] [Times: user=0.11sys=0.05, real=0.07 secs]
[Full GC(System.gc()) [PSYoungGen: 648K->0K(92160K)] [ParOldGen:65544K->66064K(66560K)] 66192K->66064K(158720K), [Metaspace:2629K->2629K(1056768K)], 0.0070466 secs] [Times: user=0.00 sys=0.00,real=0.01 secs]
沒有回收palceholder所佔的記憶體能說得過去,因為執行System.gc()時,變數placeholder還處於作用域之內,虛擬機器自然不敢回收placeholder佔用的記憶體。現在把程式碼改成如下所示:package org.administrator.classexec;
/**
* -verbose:gc
* @author Administrator
*
*/
public class LocalVarTable {
public static void main(String []args){
{
byte []placeholder=new byte[64*1024*1024];
}
System.gc();
}
}
加入花括號之後,placeholder的作用域被限制在花括號之內,從程式碼邏輯上講,在執行System.gc()的時候,placeholder已經不可能再被訪問到了,但執行程式碼之後,會發現程式執行結果如下,記憶體還是沒有被回收,這是什麼原因。
[GC(System.gc()) [PSYoungGen: 70481K->664K(92160K)] 70481K->66208K(158720K), 0.0338916 secs] [Times: user=0.11sys=0.02, real=0.03 secs]
[Full GC(System.gc()) [PSYoungGen: 664K->0K(92160K)] [ParOldGen:65544K->66064K(66560K)] 66208K->66064K(158720K), [Metaspace:2629K->2629K(1056768K)], 0.0077392 secs] [Times: user=0.00 sys=0.00,real=0.01 secs]
現在我們把程式碼進行第二次修改,在呼叫System.gc()之前加入一行“int a=0;”。package org.administrator.classexec;
/**
* -verbose:gc
* @author Administrator
*
*/
public class LocalVarTable {
public static void main(String []args){
{
byte []placeholder=new byte[64*1024*1024];
}
int a=0;
System.gc();
}
}
這個修改看起來很莫名其妙,但執行一下程式,卻發現記憶體確實被回收了。
[GC(System.gc()) [PSYoungGen: 70481K->648K(92160K)] 70481K->656K(92672K), 0.0010629 secs] [Times: user=0.00sys=0.00, real=0.00 secs]
[Full GC(System.gc()) [PSYoungGen: 648K->46K(92160K)] [ParOldGen: 8K->482K(512K)]656K->528K(92672K), [Metaspace: 2628K->2628K(1056768K)], 0.0048283 secs][Times: user=0.00 sys=0.00, real=0.01 secs]
在上述程式碼中,placeholder能否被回收的根據原因是:區域性變量表的Slot中是否還存有關於placeholder陣列物件的引用。第一次修改中,程式碼雖然已經離開了placeholder的作用域,但在此之後,沒有任何對區域性變量表的讀寫操作,placeholder原本所佔用的Slot還沒有被其他變數所複用,所以作為GC Roots的一部分的區域性變量表仍然保持著對它的關聯。這種關聯沒有被及時的打斷,在絕大部分情況下影響都很輕微。但如果遇到一個方法,其後面的程式碼有一些耗時很長的操作,而前面又定義了佔用了大量記憶體、實際上已經不會再使用的變數。手動將其設定為null值(用來代替那句int a=0;把變數對應的區域性變量表Slot清空)便不見得是一個絕對無意義的操作,這種操作可以作為一種在極特殊情況(物件佔用記憶體大、此方法的棧幀長時間不能被回收、方法呼叫次數達不到JIT的編譯條件)下的“奇技”來使用。Java語言的一本非常著名的書籍《Practical Java》中把“不使用的物件應手動賦值null”作為一條推薦的編碼規則,但是並沒有解釋具體的原因,很長時間內有讀者對這條規則感到疑惑。
雖然,上述程式碼示例說明了賦null值的操作在某些情況下確實有用,但是不應當對賦null值有過多的依賴,更沒有必要把它當做一條普遍的規則來推廣。原因有兩點,從編碼角度講,以恰當的變數作用域來控制變量回收時間才是最優雅的解決方法,如上述程式碼的場景並不多見。更關鍵的是,從執行角度講,使用賦null值的操作來優化記憶體回收是建立在位元組碼執行引擎的概念模型的理解之上的。但是,概念模型與實際執行過程是外部看起來等效,內部看上去則可以完全不同。在虛擬機器使用直譯器執行時,通常與概念模型還比較接近,但經過JIT編譯器後,才是虛擬機器執行程式碼的主要方式,賦null值經過JIT編譯優化後就會被消除掉,這時候將變數設定為null就是沒有意義的。位元組碼被編譯為原生代碼後,對GC Roots的列舉也與解釋執行時期有巨大的差別。
關於區域性變量表,還有一點可能會對開發產生影響,就是區域性變數不像前面介紹的類變數那樣存在“準備階段”。我們知道類變數有兩次賦初始值的過程,一次在準備階段,賦系統初始值;另外一次在初始化階段,賦程式設計師定義的初始值。因此,即便在初始化階段程式設計師沒有為類變數賦初始值也沒有關係,類變數仍然具有一個確定的初始值。但區域性變數就不一樣,如果一個區域性變數定義了卻沒有賦初始值是不能使用的,不用認為Java在任何情況下都存在諸如整型變數預設為0,布林型變數預設為false等這樣的預設值。如下面程式碼,其實並不能執行,還好編譯器在編譯期間就能檢查到並提示這一點,即便編譯能通過或手動生成位元組碼的方式製造出下面程式碼的效果,位元組碼校驗的時候也會被虛擬機發現而導致類載入失敗。public class LocalVarTable {
public static void main(String []args){
int a;
System.out.println(a);
}
}
8.2.2運算元棧
運算元棧(Operand Stack)也常稱為操作棧,它是一個後入先出(Last In First Out,LIFO)棧。同區域性變量表一樣,運算元棧的最大深度也在編譯期寫入到Code屬性的max_stacks資料項中。運算元棧的每一個元素都可以是任意的Java型別,包括long和double。32位資料型別所佔用的棧容量是1,64位資料型別所佔用的棧容量是2。在方法執行的任何時候,運算元棧的深度都不會超過在max_stacks資料項中設定的最大值。
當一個方法剛剛開始執行的時候,這個方法的運算元棧是空的,在方法的執行過程中,會有各種位元組碼指令往運算元棧寫入和提取內容,也就是出棧/入棧的操作。例如,在算術運算的時候是通過運算元棧來進行的,又或者在呼叫其他方法的時候是通過運算元棧來進行引數傳遞的。
舉個例子,整數加法導的iadd在執行的時候運算元棧中最接近棧頂的兩個元素已經存入了兩個int型的數值,當執行這個指令時,會將這兩個int值出棧並相加,然後將相加的結果入棧。
運算元棧中元素的資料型別必須與位元組碼指令序列嚴格匹配,在編譯程式程式碼的時候,編譯器要嚴格保證這一點。在類校驗階段的資料流分析中還要再次驗證這一點。再以上面的iadd指令為例,這個指令用於整型數加法,它在執行時,最接近棧頂的兩個元素的資料型別必須是int,不能出現一個long和一個float使用iadd命令相加的情況。
另外,在概念模型中,兩個棧幀作為虛擬機器棧的元素,是完全獨立的。但在大多數虛擬機器實現裡都會做一些優化處理,令兩個棧幀出現一部分重疊。讓下面棧幀的部分運算元棧與上面棧幀的部分區域性變量表重疊在一起,這樣在進行方法呼叫時就可以共用一部分資料,無須進行額外的引數賦值傳遞。
Java虛擬機器的解釋執行引擎稱為“基於棧的執行引擎”,其中所指的“棧”就是運算元棧。
8.2.3動態連線
每個棧幀都包含一個指向執行時常量池中該棧幀對應方法的引用,持有這個引用是為了支援方法呼叫過程中的動態連線(Dynamic Linking)。我們知道Class檔案的常量池中存有大量的符號引用,位元組碼中的符號呼叫指令就以常量池中指向方法的符號引用作為引數。這些引用一部分會在類載入階段或第一次使用的時候就轉化為直接引用,這種轉化稱為靜態解析。另外一部分在每次執行期間轉化為直接引用,這部分稱為動態連線。
8.2.4方法返回地址
當一個方法開始執行後,只有兩種方式可以退出方法。第一種方式是執行引擎遇到任意一個方法返回的位元組碼指令,這時候可能會有返回值傳遞給上層的方法呼叫者(呼叫當前方法的方法稱為呼叫者),是否有返回值以及返回值的型別將根據遇到何種方法返回指令來決定,這種退出方法的方式稱為正常完成出口(Normal Method Invocation Completion)。
另外一種退出方式是,在方法執行過程中出現了異常,並且這個異常沒有在方法體內得到處理,無論是Java虛擬機器內部產生的異常還是程式碼中使用athrow位元組碼指令產生的異常,只要在本方法的異常表中沒有搜到匹配的異常處理器,就會導致方法退出,這種退出方法的方式稱為異常完成出口(Abrupt Method Invocation Completion)。一個方法使用異常完成的出口方式退出,是不會給它的上層呼叫者產生任何返回值的。
無論採用何種退出方式,在方法退出後,都需要返回到方法被呼叫的位置,程式才能繼續執行,方法返回時可能需要在棧幀中儲存一些資訊,用來幫助恢復它的上層呼叫者的執行狀態。一般來說,方法正常退出時,呼叫者的PC計數器的值可以作為返回地址,棧幀中很可能會儲存這個PC計數器的值。而方法異常退出時,返回地址是要通過異常處理器表來確定的,棧幀中一般不會儲存這部分資訊。
方法退出的過程實際上就等同於把當前棧幀出棧,因此,退出時可能執行的操作有:恢復上層方法的區域性變量表和運算元棧,把返回值(如果有的話)壓入呼叫者棧幀的運算元棧中,調整PC計數器的值以指向方法呼叫指令後面一條指令等。
8.2.5附加資訊
虛擬機器規範允許具體的虛擬機器實現增加一些規範裡沒有描述的資訊到棧幀中,例如,與除錯相關的資訊,這部分資訊完全取決於虛擬機器的實現。在實際開發中,一般會把動態連線、方法返回地址與其他資訊全部歸為一類,稱為棧幀資訊。
8.3方法呼叫
方法呼叫並不等同於方法執行,方法呼叫階段唯一的任務就是確定被呼叫方法的版本(即呼叫哪一個方法),暫時還不涉及方法內部的具體執行過程。在程式執行時,進行方法呼叫是最普遍、最頻繁的操作,但前面已經講過,但前面已經講過,Class檔案的編譯過程中不包含傳統編譯的連線步驟,一切方法呼叫在Class檔案中儲存的都只是符號引用,而不是方法在實際執行時記憶體佈局中的入口地址(相當於之前說的直接引用)。這個特性給Java帶來了更強大的動態擴充套件能力,但也使Java方法呼叫變得相對複雜起來,需要在類載入期間,甚至到執行時才能確定目標方法的直接引用。
8.3.1解析
所有方法呼叫的目標方法在Class檔案裡面都是一個常量池中的符號引用,在類載入的解析階段,會將其中的一部分符號引用轉化為直接引用,這種解析能成立的前提是:方法在程式執行之前就有一個可確定的呼叫版本,並且這個呼叫版本在執行期是不可改變的。換句話說,呼叫目標在程式程式碼寫好、編譯器進行編譯時就必須確定下來。這類方法的呼叫稱為解析(Resolution)。
在Java語言中符號“編譯期可知,執行期不可變”這個要求的方法,主要包括靜態方法和私有方法兩大類,前者直接與型別關聯,後者在外部不可訪問,這兩種方法各自的特點決定了它們都不可能通過繼承或者別的方式重寫其他版本,因此它們都適合在類載入階段進行解析。
與之相對應的是,在Java虛擬機器裡面提供了5條方法呼叫位元組碼指令,分別如下。
invokestatic:呼叫靜態方法。
invokespecial:呼叫例項構造器<init>方法、私有方法和父類方法。
invokevirtual:呼叫所有的虛方法。
invokeinterface:呼叫介面方法,會在執行時再確定一個實現此介面的物件。
invokedynamic:先在執行時動態解析出呼叫點限定符所引用的方法,然後再執行該方法,在此之前的4條呼叫指令,分派邏輯是固化在Java虛擬機器內部的,而invokedynamic指令的分派邏輯是由使用者所設定的引導方法決定的。
只要能被invokestatic和invokespecial指令呼叫的方法,都可以在解析階段中確定唯一的呼叫版本,符合這個條件的有靜態方法、私有方法、例項構造器、父類方法4類,它們在類載入的時候就會把符號引用解析為直接引用。這些方法可以稱為非虛方法,與之相反其他方法稱為虛方法(除去final方法)。下面程式碼演示了一個常見的解析呼叫的例子,此樣例中,靜態方法sayHello()只可能屬於型別StaticResolution,沒有任何手段可以覆蓋或隱藏這個方法。
package org.administrator.classexec;
/**
* 方法靜態解析演示
* @author Administrator
*
*/
public class StaticResolution {
public static void sayHello(){
System.out.println("hello world!");
}
public static void main(String []args){
StaticResolution.sayHello();
}
}
使用javap命令檢視這段程式的位元組碼,會發現確實是通過invokestatic命令來呼叫sayHello()方法的。
public static void main(java.lang.String[]);
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=0, locals=1, args_size=1
0: invokestatic #31 // Method sayHello:()V
3: return
LineNumberTable:
line 12: 0
line 13: 3
LocalVariableTable:
Start Length Slot Name Signature
0 4 0 args [Ljava/lang/String;
Java中的非虛方法除了使用invokestatic、invokespecial呼叫的方法之外還有一種,就是被final修飾的方法。雖然final方法是使用invokevirtual指令來呼叫的,但是由於它無法被覆蓋,沒有其他版本,所以也無須對方法接收者進行多型選擇,又或者說多型選擇的結果肯定是唯一的。在Java語言規範中明確說明了final方法是非虛方法。
解析呼叫一定是個靜態的過程,在編譯期間就完全確定,在類裝載的解析階段就會把涉及的符號引用全部轉變為可確定的直接引用,不會延遲到執行期再去完成。而分派(Dispatch)呼叫則可能是靜態的也可能是動態的,根據分派依據的宗量數可分為單分派和多分派。這兩類分派方式的兩兩組合就構成了靜態單分派、靜態多分派、動態單分派和動態多分派4種分派情況,下面看看虛擬機器中的方法分派是如何進行的。
8.3.2分派
眾所周知,Java是一門面向物件的程式語言,因為Java具備面向物件的3個基本特徵:繼承、封裝和多型。本節講解的多型呼叫過程將會揭示多型性特徵的一些最基本的體現,如“過載”和“重寫”在Java虛擬機器之中是如何實現的,這裡的實現當然不是語法上該如何寫,我們關心的依然是虛擬機器如何確定正確的目標方法。
1.靜態分派
在開始講解靜態分派前,看一段經常出現的面試題,想一下下面程式的輸出結果是什麼。後面的話題將圍繞這個類的方法來過載程式碼,以分析虛擬機器和編譯器確定方法版本的過程。方法靜態分派程式碼如下。
package org.administrator.classexec;
/**
* 方法靜態分派演示
* @author Administrator
*
*/
public class StaticDispatch {
static abstract class Human{
}
static class Man extends Human{
}
static class Woman extends Human{
}
public void sayHello(Human guy){
System.out.println("hello,guy!");
}
public void sayHello(Man guy){
System.out.println("hello,gentleman!");
}
public void sayHello(Woman guy){
System.out.println("hello,lady!");
}
public static void main(String []args){
Human man=new Man();
Human woman=new Woman();
StaticDispatch sr=new StaticDispatch();
sr.sayHello(man);
sr.sayHello(woman);
}
}
執行結果:
hello,guy!
hello,guy!
上述程式碼實際上在考驗閱讀者對過載的理解程度,為什麼會選擇執行引數為Human的過載呢?在解決這個問題之前,我們先按如下程式碼定義兩個重要概念。
Humanman=new Man();
我們把上面程式碼中的“Human”稱為變數的靜態型別,或者叫做外觀型別,後面的“Man”稱為變數的實際型別,靜態型別和實際型別在程式中都有可能會發生一些變化,區別是靜態型別的變化僅僅在使用時發生,變數本身的靜態型別不會改變,並且最終的靜態型別在編譯期是可知的;而實際型別的變化在執行期才可確定,編譯器在編譯程式的時候並不知道一個物件的實際型別是什麼。例如下面的程式碼:
//實際型別變化
Human man=new Man();
man=new Woman();
//靜態型別變化
sr.sayHello((man)man);
sr.sayHello((woman)woman);
解釋了這兩個概念後,再回到上面的樣例程式碼中。main()裡面的兩次sayHello()方法呼叫,在方法呼叫者已經確定是物件“sr”的前提下,使用哪個過載版本,就完全取決於傳入引數的數量和資料型別。程式碼中刻意定義了兩個靜態型別相同但實際型別不同的變數,但虛擬機器(準確的說是編譯器)在過載時是通過引數的靜態型別而不是實際型別作為判斷依據的。並且靜態型別是編譯期可知的,因此,在編譯階段,Javac編譯期會根據引數的靜態型別決定使用哪個過載版本,所以選擇了sayHello(Human)作為呼叫目標,並把這個方法的符號引用寫到main()方法裡的兩條invokevirtual指令的引數中。
所有依賴靜態型別來定位方法執行版本的分派動作稱為靜態分派。靜態分派的典型應用是方法過載。靜態分派發生在編譯階段,因此確定靜態分派的動作實際上不是由虛擬機器來執行的。另外編譯器雖然能確定出方法的過載版本,但在很多情況下這個過載版本並不是“唯一的”,往往只能確定“一個更合適”的版本。這種模糊的結論在由0和1構成的計算機世界中算是比較“稀罕”的事情,產生這種模糊結論的主要原因是字面量不需要定義,所以字面量沒有顯式的靜態型別,它的靜態型別只能通過語言上的規則去理解和推斷。下面程式碼演示了何為“更加合適的”版本。
package org.administrator.classexec;
import java.io.Serializable;
public class OverLoad {
public static void sayHello(Object arg){
System.out.println("hello Object");
}
public static void sayHello(int arg){
System.out.println("hello int");
}
public static void sayHello(long arg){
System.out.println("hello long");
}
public static void sayHello(Character arg){
System.out.println("hello Character");
}
public static void sayHello(char arg){
System.out.println("hello char");
}
public static void sayHello(char ... arg){
System.out.println("hello char ...");
}
public static void sayHello(Serializable arg){
System.out.println("hello Serializable");
}
public static void main(String []args){
sayHello('a');
}
}
上面的程式碼執行後會輸出:
hellochar
這很好理解,’a’是一個char型別的資料,自然會尋找引數型別為char的過載方法,如果註釋掉sayHello(chararg)方法,那輸出會變為:
helloint
這時發生了一次自動型別轉換,’a’除了代表一個字串,還可以代表數字97(字元’a’的Unicode數值為十進位制數字97),因此引數型別為int的過載也是合適的。我們繼續註釋掉sayHello(int arg)方法,那輸出會變成:
hellolong
這時發生了兩次型別轉換,’a’轉型為數字97之後,進一步轉型為長整數97L,匹配了引數型別為long的過載。程式碼中沒有寫其他的型別如float、double等的過載,不過實際上自動轉型還能繼續多次,按照char->int->long->float->double的順序轉型進行匹配。但不會匹配到byte和short型別的過載,因為char到byte或short的轉型是不安全的,我們繼續註釋掉sayHello(longarg)方法,那輸出會變成:
helloCharacter
這時發生了一次自動裝箱,’a’被包裝為它的封裝型別java.lang.Character,所以匹配到引數型別為Character的過載,繼續註釋掉sayHello(Characterarg)方法,那輸出會變成:
helloSerializable
這個輸出可能會讓人摸不著頭腦,一個字或數字與序列化有什麼關係,出現hello Serializable,是因為java.lang.Serializable是java.lang.Character類實現的一個介面,當自動裝箱之後發現還是找不到裝箱類,但是找到了裝箱類實現的介面型別,所以緊接著又發生了一次自動轉型。char可以轉型為int,但是Character絕對不會轉型為Integer的,它只能安全的轉型為它實現的介面或父類。Character還實現了另外一個介面java.lang.Comparable<Character>,如果同時出現兩個引數分別為Serializable和Comparable<Character>的過載方法,那它們在此時的優先順序是一樣的。編譯器無法確定要自動轉型為哪種型別。會提示型別模糊,拒絕編譯。
程式必須在呼叫時顯式的指定字面量的靜態型別,如:sayHello(Comparable<Character>’a’),才能編譯通過。下面繼續註釋掉sayHello(Serializable arg)方法,輸出變為:
helloObject
這時是char裝箱後轉型為父類了,如果有多個父類,那將在繼承關係中從下往上開始搜尋,越接近上層的優先順序越低。即使方法呼叫轉入的引數值為null時,這個規則仍然適用。我們把sayHello(Objectarg)也註釋掉,輸出將變成:
hellochar ...
7個過載方法被註釋的只剩一個了,可見變長引數的過載優先順序最低,這時候字元’a’被當成一個數組元素。這裡使用的是char型別的變長引數,在驗證時也可以選擇int型別、Character型別、Object型別等的變長引數過載來把上面的過程重新演示一遍。但要注意的是,在一些單個引數能成立的自動轉型,如char型別轉型為int,在變長引數中是不成立的。
上面程式碼演示了編譯期間選擇靜態分派型別的過程,這個過程也是Java語言實現方法過載的本質。演示所用的例子是一個極端的情況,在實際工作中幾乎沒有實際用途。
解析與分派這兩者之間的關係並不是二選一的排他關係,它們是在不同層次上去篩選、確定目標方法的過程。例如,前面說過靜態方法是在類載入期就進行解析,而靜態方法顯然也是可以擁有過載版本的,選擇過載版本的過程也是通過靜態分派完成的。
2.動態分派
動態分派和多型性的另外一個重要體現—重寫有著很密切的關聯。還是用前面的Man和Woman一起sayHello的例子來講解動態分派。
package org.administrator.classexec;
/**
* 方法動態分派演示
* @author Administrator
*
*/
public class DynamicDispatch {
static abstract class Human{
protected abstract void sayHello();
}
static class Man extends Human{
@Override
protected void sayHello(){
System.out.println("man say hello");
}
}
static class Woman extends Human{
@Override
protected void sayHello(){
System.out.println("woman say hello");
}
}
public static void main(String []args){
Human man=new Man();
Human woman=new Woman();
man.sayHello();
woman.sayHello();
man=new Woman();
man.sayHello();
}
}
執行結果:
man say hello
woman say hello
womansay hello
這個執行結果相信不會出乎任何人的預料,對於習慣了面向物件思維的Java程式設計師會覺得這是理所當然的。虛擬機器是如何知道要呼叫哪一個方法的?
顯然這裡不可能再根據靜態型別來決定,因為靜態型別同樣都是Human的兩個變數man和woman在呼叫sayHello()方法時執行了不同的行為,並且變數man在兩次呼叫中執行了不同的方法。導致這個現象的原因很明顯,是這兩個變數的實際型別不同,Java虛擬機器是如何根據實際型別來分派方法執行版本的呢?我們使用javap命令輸出這段程式碼的位元組碼,如下。 public static void main(java.lang.String[]);
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=3, args_size=1
0: new #16 // class org/administrator/classex
ec/DynamicDispatch$Man
3: dup
4: invokespecial #18 // Method org/administrator/classe
xec/DynamicDispatch$Man."<init>":()V
7: astore_1
8: new #19 // class org/administrator/classex
ec/DynamicDispatch$Woman
11: dup
12: invokespecial #21 // Method org/administrator/classe
xec/DynamicDispatch$Woman."<init>":()V
15: astore_2
16: aload_1
17: invokevirtual #22 // Method org/administrator/classe
xec/DynamicDispatch$Human.sayHello:()V
20: aload_2
21: invokevirtual #22 // Method org/administrator/classe
xec/DynamicDispatch$Human.sayHello:()V
24: new #19 // class org/administrator/classex
ec/DynamicDispatch$Woman
27: dup
28: invokespecial #21 // Method org/administrator/classe
xec/DynamicDispatch$Woman."<init>":()V
31: astore_1
32: aload_1
33: invokevirtual #22 // Method org/administrator/classe
xec/DynamicDispatch$Human.sayHello:()V
36: return
0~15行程式碼是準備動作,作用是建立man和woman的記憶體空間、呼叫man和woman型別的例項構造器,將這兩個例項的引用存放在第1、2個區域性變量表Slot中,這個動作也就對於了程式碼中的這兩句:
Human man=new Man();
Humanwoman=new Woman();
接下來的16~21是關鍵部分,16、20兩句分別把剛剛建立的兩個物件的引用壓到棧頂,這兩個物件是將要執行的sayHello()方法的所有者,稱為接收者:17和21句是方法呼叫指令,這兩條呼叫指令單從位元組碼角度來看,無論是指令(都是invokevirtual指令)還是引數(都是常量池中第22項的常量,註釋顯示了這個常量是Human.sayHello()的符號引用),完全一樣的,但是這兩句指令最終執行的目標方法並不相同。原因就需要從invokevirtual指令的多型查詢過程開始說起,invokevirtual指令的執行時解析過程大致分為以下幾個步驟:
1)找到運算元棧頂的第一個元素所指向的物件的實際型別,記作C。
2)如果在型別C中找到與常量中的描述符和簡單名稱都相符的方法,則進行訪問許可權校驗,如果通過則返回這個方法的直接引用,查詢過程結束;如果不通過,則返回java.lang.illegalAccessError異常。
3)否則,按照繼承關係從下往上依次對C的各個父類進行第2步的搜尋和驗證過程。
4)如果始終沒有找到合適的方法,則丟擲java.lang.AbstractMethodError異常。
由於invokevirtual指令執行的第一步就是在執行期確定接收者的實際型別,所以兩次呼叫中的invokevirtual指令把常量池中的類方法符號引用解析到了不同的符號引用上,這個過程就是Java語言的方法重寫的本質。我們把這種在執行期根據實際型別確定方法執行版本的分派過程稱為動態分派。
3.單分派與多分派
方法的接收者與方法的引數統稱為方法的宗量,這個定義最早應該來源於《Java與模式》一書。根據分派基於多少種宗量,可以將分派劃分為單分派和多分派兩種。單分派是根據一個宗量對目標方法進行選擇,多分派則是根據多於一個宗量對目標方法進行選擇。
單分派和多分派的定義讀起來拗口,從字面上看也比較抽象,這裡通過例項也進行理解。package org.administrator.classexec;
/**
* 單分派,多分派演示
* @author Administrator
*
*/
public class Dispatch {
static class QQ{}
static class _360{}
public static class Father{
public void hardChoice(QQ arg){
System.out.println("father choice qq");
}
public void hardChoice(_360 arg){
System.out.println("father choice 360");
}
}
public static class Son extends Father{
public void hardChoice(QQ arg){
System.out.println("son choice qq");
}
public void hardChoice(_360 arg){
System.out.println("son choice 360");
}
}
public static void main(String []args){
Father father=new Father();
Father son=new Son();
father.hardChoice(new _360());
son.hardChoice(new QQ());
}
}
執行結果:
father choice 360
sonchoice qq
在main()方法中呼叫了兩次hardChoice()方法,這兩次hardChoice()方法的選擇結果在程式輸出中已經顯示的很清楚了。
我們來看看編譯階段編譯器的選擇過程,也就是靜態分派的過程。這時選擇目標方法的依據有兩點:一是靜態型別是Father還是Son,二是方法引數是QQ還是360,。這次選擇結果的最終產物是產生了兩條invokespecial指令,兩條指令的引數分別為常量池中指向Father.hardChoice(360)及Father.hardChoice(QQ)的符號引用。因為是根據兩個宗量進行選擇,所以Java語言的靜態分派屬於多分派型別。
再看看執行階段虛擬機器的選擇,也就是動態分派的過程。在執行“son.hardChoice(new QQ())”這句程式碼時,更準確地說,是在執行這句程式碼所對應的invokevirtual指令時,由於編譯期已經決定目標方法的簽名必須為hardChoice(QQ),虛擬機器此時不會關心此時傳遞過來的到底是“騰訊QQ”還是“奇瑞QQ”,因為這時引數的靜態型別、實際型別都對方法的選擇不會構成任何影響,唯一可以影響虛擬機器選擇的因素只有此方法的接收者的實際型別是Father還是Son。因為只有一個宗量作為選擇依據,所以Java語言的動態分派屬於單分派型別。
根據上述論證的結果,我們可以總結一句:到JDK1.7的Java語言是一門靜態多分派,動態單分派的語言。
4.虛擬機器動態分派的實現
前面介紹的分派過程,作為虛擬機器概念模型的解析基本上已經足夠了,它已經解決了虛擬機器在分派過程中“會做什麼”這個問題。但是虛擬機器“具體如何做到的”,可能各種虛擬機器的實現都會存在差別。
由於動態分派是非常頻繁的動作,而且動態分派的版本選擇過程需要執行時在類的方法元資料中搜索合適的目標方法,因此在虛擬機器的實際實現中基於效能的考慮,大部分實現都不會真正的進行如此頻繁的搜尋。面對這種情況,最常用的“穩定優化”手段就是為類在方法區中建立一個虛方法表(Virtual Method Table,也稱為vtable,與此對應,在invokeinterface執行時也會用到介面方法表—InterfaceMethod Table,簡稱itable),使用虛方法索引來代替元資料查詢以提高效能。
虛方法表中存放著各個方法的實際入口地址。如果某個方法在子類中沒有被重寫,那子類的虛方法表裡面的地址入口和父類相同方法的地址入口一致的,都指向父類的實現入口。如果子類中重寫了這個方法,子類方法表中的地址將會替換為指向子類實現版本的入口地址。
為了程式實現上的方便,具有相同簽名的方法,在父類、子類的虛方法表中都應當具有一樣的索引號,這樣當型別變換時,僅需要變更查詢的方法表,就可以從不同的方法表中按索引轉換出所需的入口地址。
方法表一般在類載入的連線階段進行初始化,準備了類變數的初始值之後,虛擬機器會把該類的方法表也初始化完畢。
上文說過方法表是分派呼叫的“穩定優化”手段,虛擬機器除了使用方法表之外,在條件執行的情況下,還會使用內聯快取和基於“型別繼承關係分析”技術的守護內聯兩種非穩定的“激進優化”手段來獲取更高的效能。
8.3.3動態型別語言支援
Java虛擬機器的位元組碼指令集的數量從Sun公司的第一款Java虛擬機器問世至JDK7來臨之前的十餘年時間裡,一直沒有發生任何變化。隨著JDK7的釋出,位元組碼指令集終於迎來了第一位新成員---invokedynamic指令,這條新增的指令是JDK7實現“動態型別語言”支援而進行的改進之一,也是為了JDK8可以順利實現Lambda表示式做技術準備。在本節中,我們來詳細瞭解下JDK7這項新特性出現的前因後果和它的深遠意義。
1.動態型別語言
在介紹Java虛擬機器的動態型別語言支援之前,我們要先弄明白動態型別語言是什麼?它與Java語言、Java虛擬機器有什麼關係?瞭解JDk1.7提供動態型別語言支援的技術背景,對理解這個語言特性是很重要的。
什麼是動態型別語言?動態型別語言的關鍵特徵是它的型別檢查的主體過程是執行期而不是編譯期,滿足這個特徵的語言有很多,常用的包括:APL、Clojure、Erlang、Groovy、JavaScript、Jython、Lisp、Lua、PHP、Prolog、Python、Ruby、Smalltalk和Tcl等。相對的,在編譯期就進行型別檢查的語言(如C++和Java等)就是最常用的靜態型別語言。
可以通過兩個例子以最淺顯的方式來說明什麼是“在編譯期/執行期進行”和什麼是“型別檢查”。首先看下面這段簡單的Java程式碼,它是否能正常編譯執行?
public static void main(String [] args){
int [][][] array=new int[1][0][-1];
}
這段程式碼能夠正常編譯,但執行的時候會報java.lang.NegativeArraySizeException異常。在Java虛擬機器規範中明確規定了java.lang.NegativeArraySizeException異常是一個執行時異常,通俗一點來說,執行時異常就是隻要這一行程式碼不執行就不會出問題。與執行時異常相對應的是連線時異常,例如很常見的NoClassDefFoundError便屬於連線時異常,即便會導致連線時異常的程式碼放到一條無法執行到的分支路徑上,類載入時(Java的連線過程不在編譯階段,而在類載入階段)也照樣會丟擲異常。
不過在C語言中,含義相同的程式碼會在編譯期報錯:
int main(void){
int i[1][0][-1]; //GCC拒絕編譯,會報“size of array is negative”
return 0;
}
由此看來,一門語言的哪一種檢查是在執行時期進行,哪一種檢查要在編譯期進行並沒有必然的因果邏輯關係,關鍵是語言規範是人為規定的。再舉一個例子來解釋“型別檢查”,例如下面這一句非常簡單的程式碼:
obj.println(“helloworld”);
雖然每個人都能看懂這行程式碼要做什麼,但對於計算機來說,這一行程式碼“沒頭沒尾“是無法執行的,它需要一個具體的上下文才有討論的意義。
現在假設這行程式碼是在Java語言中,並且變數的靜態型別為java.io.PrintStream,那變數obj的實際型別就必須是PrintStream的子類(實現了PrintStream介面的類)才是合法的。否則,哪怕obj屬於一個確實有println(String)方法,但與PrintStream介面沒有繼承關係,程式碼依然不可能執行—因為型別檢查不合法。
但是相同的程式碼在ECMAScript(JavaScript)中情況則不一樣,無論obj具體是何種型別,只要這種型別的定義中確實包含有println(String)方法,那方法呼叫便可成功。
這種差別產生的原因是Java語言在編譯期間已將println(String)方法完整的符號引用(本例中是一個CONSTANT_InterfaceMethodref_info常量)生成出來,作為方法呼叫指令的引數儲存到Class檔案中,例如下面這段程式碼:
invokevirtual#4;//Method java/io/PrintStream.println:(Ljava/lang/String;)V
這個符號引用包含了此方法定義在哪個具體型別之中、方法的名字以及引數順序、引數型別和方法返回值等資訊,通過這個符號引用,虛擬機器可以翻譯出這個方法的直接引用。而在ECMAScript等動態型別語言中,變數obj本身是沒有型別的,變數obj的值才具有型別,編譯時中最多隻能確定方法名稱、引數、返回值這些資訊,而不會去確定方法所在的具體型別(即方法接收者不是固定的)。“變數無型別而變數值才有型別“這個特點也是動態型別語言的一個重要特徵。
動態和靜態型別語言各有優缺點,選擇哪種語言是需要權衡的,靜態型別語言在編譯期確定型別,最顯著的好處是編譯器可以提供嚴謹的型別檢查,這樣與型別相關的問題能在編碼的時候就及時發現,利於穩定性及程式碼達到更大規模。而動態型別語言在執行期確定型別,這可以為開發人員提供更大的靈活性,某些在靜態型別語言中需用大量“臃腫“程式碼來實現的功能,由動態型別語言來實現可能會更加清晰和簡潔,清晰和簡潔通常也就意味著開發效率的提升。
2.JDK1.7與動態型別
Java虛擬機器毫無疑問是Java語言執行的平臺,但它的使命並不僅限於此,早在1997年出版的《Java虛擬機器規範》就規劃了這一願景:“在未來,我們將對Java虛擬機器進行適當的擴充套件,以便更好的支援其他語言執行與Java虛擬機器之上“。而且目前確實已經有很多動態型別語言執行與Java虛擬機器之上了,如Clojure、Groovy、Jython和JRuby等,能夠在同一虛擬機器上達到靜態語言的嚴謹和動態語言的靈活,這是一件很美妙的事情。
但遺憾的是,Java虛擬機器層面對動態型別語言的支援一直都有所欠缺,主要表現在方法呼叫方面:JDK1.7以前的位元組碼指令集中,4條方法呼叫指令(invokevirtual、invokespecial、invokestatic、invokeinterface)的第一個引數都是被呼叫方法的符號引用(CONSTANT_Methodref_info或者CONSTATN_InterfaceMethodref_info常量),前面已經提到過,方法的符號引用是在編譯期產生,而動態型別語言只有在執行時才能確定接收者型別。這樣,在Java虛擬機器上實現的動態型別語言就不得不使用其他方式(如編譯時留個佔位符型別,執行時動態生成位元組碼實現具體型別到佔位符型別的適配)來實現,這樣勢必讓動態型別語言實現的複雜度增加,也可能帶來額外的效能或者記憶體開銷。儘管可以利用一些辦法(如Call Site Caching)讓這些開銷儘量變小,但這種底層問題終歸是應當在虛擬機器層次上去解決才最合適,因此在Java虛擬機器層面上提供動態型別的直接支援就成為了Java平臺的發展趨勢之一,這就是JDK1.7中invokedynamic指令以及java.lang.invoke包出現的技術背景。
3.java.lang.invoke包
JDK1.7實現了JSR-292,新加入的java.lang.invoke包就是JSR-292的一個重要組成部分,這個包的主要目的是在之前單純依靠符號引用來確定呼叫的目標方法這種方式以外,提供一種新的動態確定目標方法的機制,稱為MethodHandle舉個例子,如果我們要實現一個帶謂詞的排序函式,在C/C++中常用的做法是把謂詞定義為函式,用函式指標把謂詞傳遞到排序方法,如下:void sort(int List[],const int size,int(*compare)(int,int))但Java語言做不到這一點,即沒有辦法單獨地把一個函式作為引數進行傳遞。普遍的做法是設計一個帶有compare()方法的Comparator介面,以實現了這個介面的物件作為引數,例如Collections.sort()就是這樣定義的:
void sort(List list,Comparator c)不過,在擁有MethodHandle之後,Java語言也可以擁有類似於函式指標或者委託的方法別名的工具了。下面程式碼演示了MethodHandle的基本用途,無論obj是何種型別。都可以正確的呼叫到println()方法。
package org.administrator.classexec;
import java.lang.invoke.MethodHandle;
import java.lang.invoke.MethodHandles;
import java.lang.invoke.MethodType;
/**
* JSP-292 Method Handle基礎用法示例
* @author Administrator
*
*/
public class MethodHandleTest {
static class ClassA{
public void println(String s){
System.out.println(s);
}
}
public static void main(String []args) throws Throwable{
Object obj=System.currentTimeMillis()%2==0?System.out:new ClassA();
/*無論obj最終是哪個實現類,下面這句都能正確呼叫到println方法*/
getPrintlnMH(obj).invokeExact("xxx");
}
private static MethodHandle getPrintlnMH(Object reveiver) throws Throwable{
/**MethodType:代表方法型別,包含了方法的返回值(methodType()的第一個引數)和具體引數(methodType()第二個及以後的引數)
*/
MethodType mt=MethodType.methodType(void.class,String.class);
/*lookup()方法來自於MethodHandles.lookup,這句的作用是在指定類中查詢符合給定的方法名稱、方法型別,並且符合呼叫許可權的方法控制代碼*/
/*因為這裡呼叫的是一個虛方法,按照Java語言的規則,方法第一個引數是隱式的,代表該方法的接收者,
* 也就是this指向的物件,這個引數以前是放到引數列表裡進行傳遞的,現在提供了bingTo()方法來完成這件事情*/
return MethodHandles.lookup().findVirtual(reveiver.getClass(),"println",mt).bindTo(reveiver);
}
}
實際上,方法getPrintlnMH()中模擬了invokevirtual指令的執行過程,只不過它的分派邏輯並非固化在Class檔案的位元組碼上,而是通過一個具體方法來實現。而這個方法本身的返回值(MethodHandle物件),可以視為對最終呼叫方法的一個“引用“。以此為基礎,有了MethodHandle就可以寫出類似於下面這樣的函式宣告:
voidsort(List list,MethodHandle compare)
從上面的例子可以看出,使用MethodHandle並沒有什麼困難,不過看完它的用法之後,我們也許會產生這樣的疑問,相同的事情,反射不是早就實現了嗎?
確實,僅站在Java語言的角度來看,MethodHandle的使用方法和效果與Reflection有眾多相似之處,不過,它們還是有以下這些區別:
從本質上講,Reflection和MethodHandle都是在模擬方法呼叫,但Reflection是在模擬Java程式碼層次的方法呼叫,而MethodHandle是在模擬位元組碼層次的方法呼叫。在MethodHandles.lookup中的3個方法—findStatic()、findVirtual()、findSpecial()正是為了對應於invokestatic、invokevirtual和invokespecial這幾條位元組碼指令的執行許可權校驗行為,而這些底層細節在使用ReflectionAPI時是不需要關心的。
Reflection中的java.lang.reflect.Method物件遠比MethodHandle機制中的java.lang.invoke.MethodHandle物件所包含的資訊多。前者是方法在Java一端的全面映像,包含了方法的簽名、描述符以及方法屬性表中各種屬性的java端表示方式,還包含執行許可權等的執行期資訊。而後者僅僅包含與執行該方法相關的資訊。用通俗的話來講,Reflection是重量級,而MethodHandle是輕量級。
由於MethodHandle是對位元組碼的方法指令呼叫的模擬,所以理論上虛擬機器在這方面做的各種優化(如方法內聯),在MethodHandle上也應當可以採用類似思路去支援(但目前實現還不完善)。而通過反射去呼叫方法則不行。
MethodHandle與Reflection除了上面列舉的區別外,最關鍵的一點還在於去掉前面討論施加的前提“僅站在Java語言的角度來看“:ReflectionAPI的設計目標是隻為Java語言服務的,而MethodHandle則設計成可服務於所有Java虛擬機器之上的語言,其中也包括Java語言。
4.invokedynamic指令
在某種程度上,invokedynamic指令與MethodHandle機制的作用是一樣的,都是為了解決原有4條“invoke*“指令方法分派規則固化在虛擬機器之中的問題,把如何查詢目標方法的決定權從虛擬機器轉嫁到具體使用者程式碼中,讓使用者有更高的自由度。而且,它們兩者的思路也是可類比的,可以把它們想象成為了達成同一個目的,一個採用上層Java程式碼和API來實現,另一個用位元組碼和Class中其他屬性、常量來完成。因此,如果理解了前面的MethodHandle例子,那麼理解invokedynamic指令也並不困難。
每一處含有invokedynamic指令的位置都稱作“動態呼叫點“,這條指令的第一個引數不再是代表方法符號引用的CONSTANT_Methodref_info常量,而是變為JDK1.7新加入的CONSTANT_invokeDynamic_info常量,從這個新常量中可以得到3項資訊:引導方法(BootstrapMethod,此方法存放在新增的BootstrapMethods屬性中)、方法型別(MethodType)和名稱。引導方法是有固定的引數,並且返回值是java.lang.invokeCallSite物件,這個代表真正要執行的目標方法呼叫。根據CONSTANT_invokeDynamic_info常量中提供的資訊,虛擬機器可以找到並且執行引導方法,從而獲得一個CallSite物件,最終呼叫要執行的目標方法。如下程式碼。
package org.administrator.classexec;
import java.lang.invoke.CallSite;
import java.lang.invoke.ConstantCallSite;
import java.lang.invoke.MethodHandle;
import java.lang.invoke.MethodHandles;
import java.lang.invoke.MethodType;
public class InvokeDynamicTest {
public static void main(String []args) throws Throwable{
INDY_BootstrapMethod().invokeExact("test");
}
public static void testMethod(String s){
System.out.println("hello String:"+s);
}
public static CallSite BootstrapMethod(MethodHandles.Lookup lookup,String name,MethodType mt) throws Throwable{
return new ConstantCallSite(lookup.findStatic(InvokeDynamicTest.class, name, mt));
}
private static MethodType MT_BootstrapMethod(){
return MethodType.fromMethodDescriptorString("(Ljava/lang/invoke/MethodHandles$Lookup;Ljava/lang/String;Ljava/lang/invoke/MethodType;)Ljava/lang/invoke/CallSite;", null);
}
private static MethodHandle MH_BootstrapMethod() throws Throwable{
return MethodHandles.lookup().findStatic(InvokeDynamicTest.class,"BootstrapMethod",MT_BootstrapMethod());
}
private static MethodHandle INDY_BootstrapMethod() throws Throwable{
CallSite cs=(CallSite)MH_BootstrapMethod().invokeWithArguments(MethodHandles.lookup(),"testMethod",MethodType.fromMethodDescriptorString("(Ljava/lang/String;)V", null));
return cs.dynamicInvoker();
}
}
這段程式碼與前面的MethodHandleTest的作用基本一致,由於invokedynamic所面向的使用者並非Java語言,而是其他Java虛擬機器之上的動態語言,因此依靠Java語言的編譯器Javac沒有辦法生成帶有invokedynamic指令的位元組碼,所以要使用Java語言來演示invokedynamic指令只能用一些變通的辦法。JhonRose編寫了一個把程式的位元組碼轉換為使用invokedynamic的簡單工具INDY來完成這件事情,我們要使用這個工具來產生最終要的位元組碼,因此這個示例程式碼中的方法名稱不能隨意改動,更不能把幾個方法合併到一起寫,因為它們是要被INDY工具讀取的。
把上面程式碼編譯再使用INDY轉換後重新生成的位元組碼,從main()方法的位元組碼,原本的方法呼叫指令已經替換為invokedynamic。
5.掌控方法分派原則
invokedynamic指令與前面4條“invoke*“指令的最大差別就是它的分派邏輯不是由虛擬機器決定的,而是由程式設計師決定的。
package org.administrator.classexec;
class GrandFather{
void thinking(){
System.out.println("i am grandfather");
}
}
class Father extends GrandFather{
void thinking(){
System.out.println("i am father");
}
}
class Son extends Father{
void thinking(){
//在這裡填入適當的程式碼(不能修改其他地方的程式碼)
//實現呼叫祖父類的thinking()方法,列印“i am grandfather”
}
}
在Java程式中,可以通過“super“關鍵字很方便的呼叫父類中的方法,但如果要訪問祖父類的方法呢?
在JDK1.7之前,使用純粹的Java語言很難處理這個問題(直接生成位元組碼就很簡單,如使用ASM等位元組碼工具),原因是在Son類的thinking(0方法中無法獲取一個實際型別是GrandFather的物件引用,而invokevirtual指令的分派邏輯就是按照方法接收者的實際型別進行分派,這個邏輯固化在虛擬機器中,程式設計師無法改變。在JDK1.7中,可以使用下面的程式碼解決這個問題。
package org.administrator.classexec;
import java.lang.invoke.MethodHandle;
import java.lang.invoke.MethodHandles;
import java.lang.invoke.MethodType;
public class IDDispatch {
class GrandFather{
void thinking(){
System.out.println("i am grandfather");
}
}
class Father extends GrandFather{
void thinking(){
System.out.println("i am father");
}
}
class Son extends Father{
void thinking(){
try{
MethodType mt=MethodType.methodType(void.class);
MethodHandle mh=MethodHandles.lookup().findSpecial(GrandFather.class, "thinking", mt, getClass());
mh.invoke(this);
}catch(Throwable e){
}
}
}
public static void main(String []args){
(new IDDispatch().new Son()).thinking();
}
}
8.4基於棧的位元組碼解釋執行引擎
許多Java虛擬機器的執行引擎在執行Java程式碼的時候都有解釋執行(通過直譯器執行)和編譯執行(通過即時編譯器產生原生代碼執行)兩種選擇。
8.4.1解釋執行
Java語言經常被人們定位為“解釋執行“的語言,在Java初生的JDK1.0時代,這種定義還算比較準確,但當主流的虛擬機器中都包含了即時編譯器後,Class檔案中的程式碼到底會被解釋執行還是編譯執行,就成了只有虛擬機器自己才能決斷的事了。
Java語言中,Javac編譯器完成了程式程式碼經過詞法分析、語法分析到抽象樹分析,再遍歷語法樹生成線性的位元組碼指令流的過程。因為這一部分動作是在Java虛擬機器之外進行的,而解釋執器在虛擬機器的內部,所以Java程式的編譯就是半獨立的實現。
8.4.2
Java編譯器輸出的指令流,基本上是基於棧的指令集架構,指令流中的指令大部分都是 零地址指令,它們依賴運算元棧進行工作。與之相對的另外一套常用的指令集架構是基於暫存器的指令集,最典型的就是x86的二進位制指令集,說得通俗點,就是現在我們主流PC機中直接支援的指令集架構,這些指令依賴暫存器進行工作。那麼,基於棧的指令