
重新編譯spark 增加spark-sql適配CDH
參考資料
CDH內嵌spark版本不支援spark-sql,可能是因為cloudera在推自己的impala;如果上線spark卻不能使用sql這種結構化語言,對於大部分分析人員其實是有一定的門檻的
準備環境
編譯獲取assembly的jar包
修改maven的記憶體配置,防止記憶體溢位,在$mavn_home/bin下的mvn增加下面這一行
MAVEN_OPTS="$MAVEN_OPTS -Xms256m -Xmx1024m -XX:MaxPermSize=128m -XX:ReservedCodeCacheSize=128m"
對spark進行編譯,進入spark解壓目錄 /pwl/code/spark-1.5.0 執行以下命令,指定yarn、thrift、cdh,注意hadoop.version和scala版本
mvn -Pyarn -Dhadoop.version=2.6.0-cdh5.5.0 -Dscala-2.10.3 -Phive -Phive-thriftserver -DskipTests clean package這是我編譯過程中遇到錯誤調整過後根目錄下的pom.xml檔案,存放在百度網盤中供參考:spark原始碼中的pom.xml
編譯時間比較長,結果如下
目標是需要一個新的加入了hive相關的jar包spark-assembly.jar,編譯結果的路徑為
/pwl/code/spark-1.5.0/assembly/target/scala-2.10 ,如下圖,其中/pwl/code/spark-1.5.0為原始碼的解壓路徑

編譯後,有200M大小…如果下載到win下修改後綴名為rar或者zip開啟進入org/apache目錄有hive和thrift相關的目錄,下圖為編譯前後org/apache下目錄結果對比
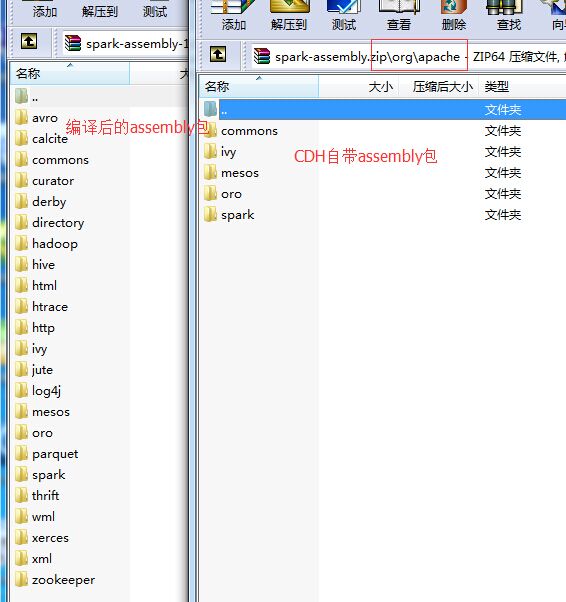
替換spark下原有的assembly jar包(如果想要執行example,對應的example包也需要替換)
需要替換的目錄為/opt/cloudera/parcels/CDH/lib/spark/lib,該目錄為使用CM安裝的自定義目錄
對應檔案為spark-assembly-1.5.0-cdh5.5.0-hadoop2.6.0-cdh5.5.0.jar,實際上這個檔案是一個軟連線到 /opt/cloudera/parcels/CDH/jars下的assembly包,所以直接將編譯好的包替換掉就可以了(建議備份原有的jar包)
這裡只替換master上的即可,如果想在其他客戶端使用spark-sql,也需要替換掉
修改路徑
上傳assembly包到hdfs上
hdfs路徑為:/user/spark/share/lib/spark-assembly-1.5.0-hadoop2.6.0-cdh5.5.0.jar
修改檔案許可權為755
之後配置修改spark服務範圍

spark-default.conf配置檔案中增加配置即 assembly 包的指向(gateway中設定)
spark.yarn.jar=hdfs://master:8020/user/spark/share/lib/spark-assembly-1.5.0-hadoop2.6.0-cdh5.5.0.jar引數spark.yarn.jar 主要是用於優化,避免在每次提交作業的時候都從本地上傳這個檔案到hdfs叢集帶來的資源消耗

增加hive和yarn的配置檔案
實際上在CM中的spark是有預設去讀取hive和yarn的配置目錄的,如果沒有的話可以自己進行配置,如下
在CM叢集管理中的spark中,修改spark-conf/spark-env.sh 增加下面命令
export HIVE_CONF_DIR=/opt/cloudera/parcels/CDH/lib/hive/conf
注:這個應該直接將hive-site.xml檔案拷進$spark_home/conf 下也可以解決
啟用spark-sql
啟用spark-sql有兩種方式,直接執行spark-sql、使用beeline通過thrift進行
方式一 利用spark-sql啟動
從編譯的原始碼中的bin目錄複製spark-sql指令碼存放到CDH下的spark啟動目錄下,
cp /pwl/code/spark-1.5.0/bin/spark-sql ../bin/

修改spark_home目錄下的spark-sql指令碼中的FWDIR路徑,修改為絕對路徑,如果有配置全域性的SPARK_HOME,可以設定FWDIR=$SPARK_HOME,最後將spark-sql檔案複製到 /usr/sbin 下,可直接執行spark-sql進行啟動

執行效果如下:
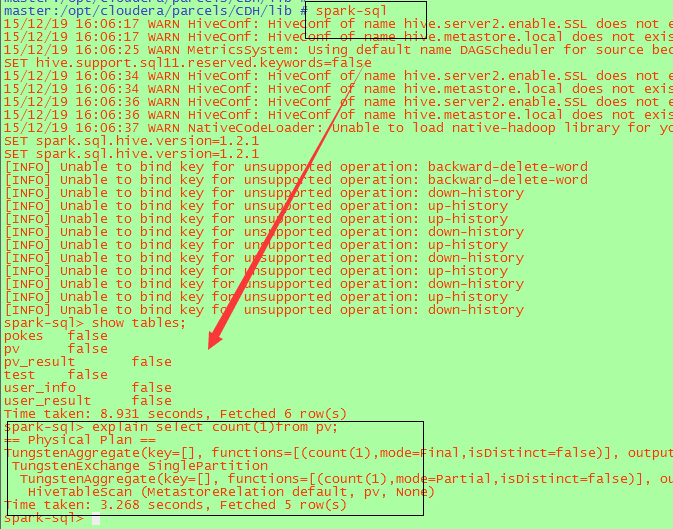
方式二 利用beeline啟動
複製編譯目錄下面的bin/start-thriftserver.sh 和stop-thriftserver.sh 到spark_home下的sbin目錄 (
./start-thriftserver.sh –master yarn –hiveconf hive.server2.thrift.port=10008
預設的埠為10000
beeline -u jdbc:hive2://master:10008
如下:注意埠一致,出現Connected to:Spark SQL為連線成功,否則連線的還是hive,或者使用explain檢視執行計劃是否走的RDD
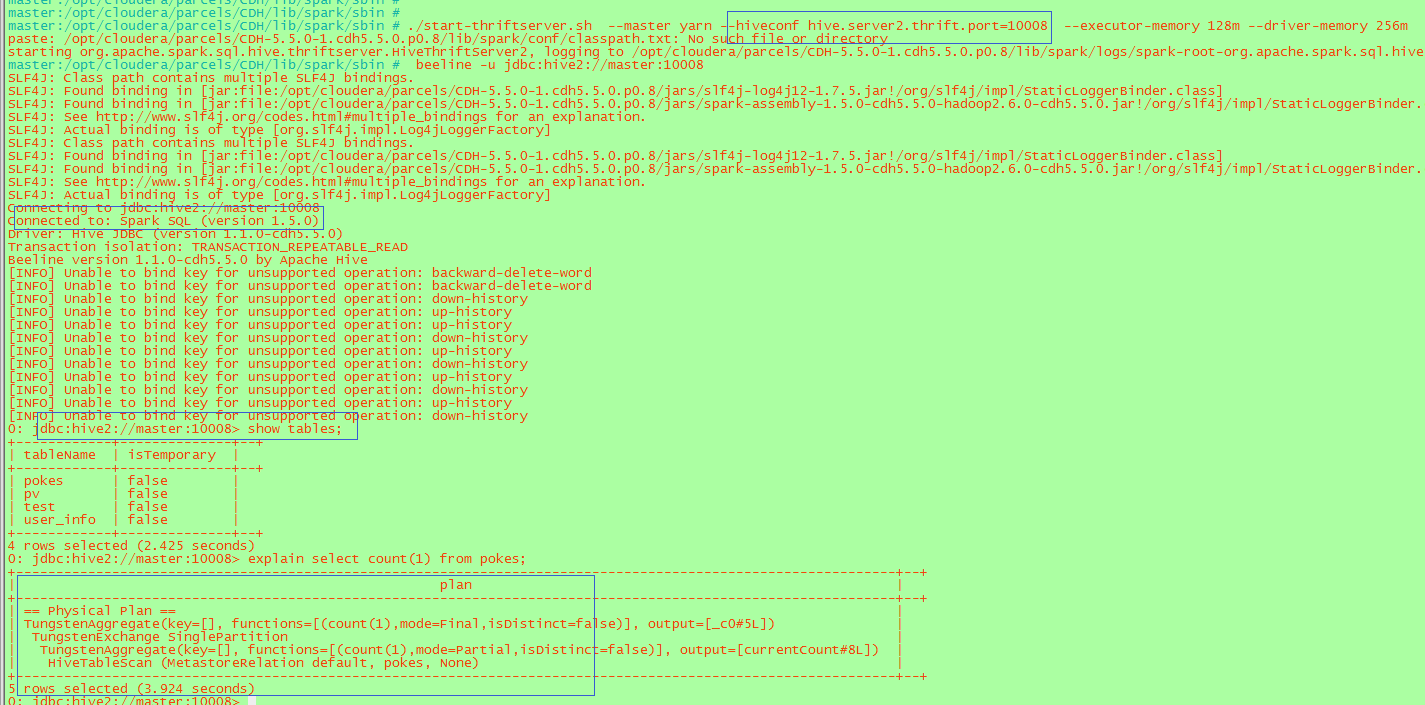
關於方式一和方式二的區別,方式一直接使用spark-sql,執行一次就會啟用一個yarn applicaiton,對於通過thrift,beeline不管連線多少個都是對應一個yarn application。執行的HQL是跟hive一致的。