【Python】尋找電影品味相似的使用者並推薦相關電影
阿新 • • 發佈:2019-01-06
過程:
- 用爬蟲抓取豆瓣電影使用者資訊
- 用多重分類法,定義電影評價等級
- 計算自己與使用者的皮爾遜相關度
- 以人為主體分析相似度:找出志同道合的人,可以發現潛在喜歡的商品
- 以商品為主體分析相似度:找出相似的商品,可以發現潛在的客戶(如亞馬遜的‘買了該商品的使用者還買了’)
電影評價多重分類:

使用者資訊錄入:
#-*- coding: utf-8 -*- import json import sys reload(sys) sys.setdefaultencoding( "utf-8" ) user_info = {} #爬取到的資料 user_dict = { 'ns2250225':[4,3,4,5,4], 'justin':[3,4,3,4,2], 'totox':[2,3,5,1,4], 'fabrice':[4,1,3,4,5], 'doreen':[3,4,2,5,3] } #錄入使用者資料 def user_data(user_dict): for name in user_dict: user_info[name] = {u'消失的愛人' : user_dict[name][0]} user_info[name][u'霍位元人3'] = user_dict[name][1] user_info[name][u'神去村'] = user_dict[name][2] user_info[name][u'泰坦尼克號'] = user_dict[name][3] user_info[name][u'這個殺手不太冷'] = user_dict[name][4] user_data(user_dict) #存放使用者資料 try: with open('user_data.txt', 'w') as data: for key in user_info: data.write(key) for key2 in user_info[key]: data.write('\t') data.write(key2) data.write('\t') data.write('\t') data.write(str(user_info[key][key2])) data.write('\n') data.write('\n') except IOError as err: print('File error: ' + str(err))
計算皮爾遜相關係數,找出興趣相投的使用者:(插入自己的資料)
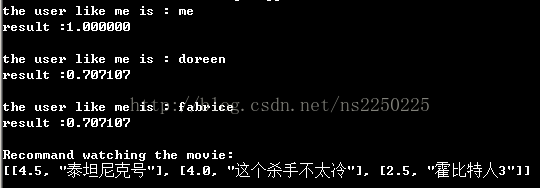
from math import sqrt #計算皮爾遜相關度(1為完全正相關,-1為完成負相關) def sim_pearson(prefs, p1, p2): # Get the list of mutually rated items si = {} for item in prefs[p1]: if item in prefs[p2]: si[item] = 1 # if they are no ratings in common, return 0 if len(si) == 0: return 0 # Sum calculations n = len(si) # Sums of all the preferences sum1 = sum([prefs[p1][it] for it in si]) sum2 = sum([prefs[p2][it] for it in si]) # Sums of the squares sum1Sq = sum([pow(prefs[p1][it], 2) for it in si]) sum2Sq = sum([pow(prefs[p2][it], 2) for it in si]) # Sum of the products pSum = sum([prefs[p1][it] * prefs[p2][it] for it in si]) # Calculate r (Pearson score) num = pSum - (sum1 * sum2 / n) den = sqrt((sum1Sq - pow(sum1, 2) / n) * (sum2Sq - pow(sum2, 2) / n)) if den == 0: return 0 r = num / den return r #插入自己的資料 user_info['me'] = {u'消失的愛人' : 5, u'神去村' : 3, u'炸裂鼓手' : 5} #找出皮爾遜相關係數>0的使用者,說明該使用者與自己的電影品味比較相近 for user in user_info: res = sim_pearson(user_info, 'me', user) if res > 0: print('the user like %s is : %s' % ('me', user)) print('result :%f\n' % res)
向某使用者推薦電影(加權平均所有人的評價)
#向某個使用者推薦電影(加權平均所有人的評價值) def getRecommendations(prefs,person,similarity=sim_pearson): totals={} simSums={} for other in prefs: # don't compare me to myself if other==person: continue sim=similarity(prefs,person,other) # ignore scores of zero or lower if sim<=0: continue for item in prefs[other]: # only score movies I haven't seen yet if item not in prefs[person] or prefs[person][item]==0: # Similarity * Score totals.setdefault(item,0) totals[item]+=prefs[other][item]*sim # Sum of similarities simSums.setdefault(item,0) simSums[item]+=sim # Create the normalized list rankings=[(total/simSums[item],item) for item,total in totals.items()] # Return the sorted list rankings.sort() rankings.reverse() return rankings #向我推薦電影 res = getRecommendations(user_info, "me") print('Recommand watching the movie:') print json.dumps(res, encoding='UTF-8', ensure_ascii=False)
結果與分析:
- 與我電影口味相近的使用者有:doreen, fabrice
- 推薦我看的電影有:泰坦尼克號,這個殺手不太冷
- 以人為主體分析, 找出有相似愛好的人, 並向這些人推薦商品,可以發現潛在喜歡的商品
- 而若以商品為主體分析, 找出相似的商品, 找出喜歡這個產品的人, 可以發現商品潛在的客戶