人工智慧學習筆記-Theano介紹及簡單應用
1 Theano介紹和安裝
1.1 什麼是Theano
Theano是一個較為老牌和穩定的機器學習python庫之一。Theano基於Python擅長處理多維陣列(緊密集成了Numpy),屬於比較底層的框架,theano起初也是為了深度學習中大規模人工神經網路演算法的運算所設計,我們可利用符號化式語言定義想要的結果,接著theano會對我們的程式進行編譯,使其高效運行於GPU或CPU
1.2 Theano的特點
從Theano官方文件上摘抄來的對Theano的特徵介紹:
- tight integration with Numpy (緊密整合Numpy) —— 在Theano編譯函式中使用numpy.ndarray
- transparent use of a GPU (GPU的透明使用) —— 使得其對浮點數的運輸非常高速
- efficient symbolic differentiation (高效的符號分解) —— 也是Theano的發明初衷之一,可幫我們推導我們所定義的一個或多個輸入的函式
- speed and stability optimizations (快速且穩定的優化) —— 在函式表示式
log(1+x) 中即使x 非常小,也可以給出精確的答案- dynamic C code generation (動態生成C程式碼) —— 使得表示式求值(evaluate expression)更加快速
- extensive unit-testing and self-verification (大量的單元測試及自我驗證) —— 可檢測及診斷許多型別的錯誤
1.3 安裝
系統ubuntu14.04
# 1. 先使用apt-get update命令進行更新,避免安裝Python庫時出現問題
$ sudo apt-get update
# 2. 接著安裝在安裝theano前需安裝的Python庫
$ sudo apt-get install python-numpy python-scipy python-matplotlib python-dev python-pip python-nose python-tk g++ libopenblas-dev git
# 3. 接著第三步便是使用pip命令安裝theano 2 簡單應用
2.1 張量
2.1.1 什麼是張量
Tensor(張量)是什麼,剛開始看的時候被繞的迷迷糊糊的頭都暈了,最後發現其實就是多維陣列起了個高大上的名字,讓人看起來很牛逼,張量向量啥的比一維陣列二維陣列聽起來高階多了。
通俗的講:
scalar(標量) 0維陣列
vector (向量) 1維陣列
row (行向量) 2維陣列,但是行數保證是1
col (列向量) 2維陣列,但是列數保證是1
matrix (矩陣) 2維陣列
tensor3 (三維矩陣) 3維陣列
tensor4 (四位矩陣) 4維陣列
2.1.2 怎麼定義張量
後續所有的示例都需要按照如下程式碼引入包
import theano
import theano.tensor as T
from theano.tensor import *
from theano import shared
import numpy as npTheano提供了一列預先定義好的張量型別可供使用者很方便地創造張量變數,所有的張量建構函式都接收一個 可選 的輸入引數name。如以下便構造了三個以myvar為名字的 0維整型標量(scalar)變數
x = T.scalar('myvar', dtype='int32')
x = iscalar('myvar')
x = TensorType(dtype='int32', broadcastable=())('myvar')還可以通過vector、row、col、matrix、tensor3及tensor4分別構造向量、行向量、列向量、矩陣、三維張量及四維張量。
我們還可以通過以下方式創造張量型別例項
# 創造一個雙精度浮點型別的無名矩陣
x = dmatrix()
# 創造了一個雙精度浮點型別的名為'x'的矩陣
x = dmatrix('x')
# 創造了一個雙精度浮點型別的名為'xyz'矩陣
xyz = dmatrix('xyz')
# 構造三個無名雙精度浮點型別矩陣
x, y, z = dmatrices(3)
# 構造三個分別名為'x','y','z'的double型別矩陣
x, y, z = dmatrices('x', 'y', 'z')2.1.3 關於張量的精度問題
| Constructor | dtype | ndim | shape | broadcastable |
|---|---|---|---|---|
| bscalar | int8 | 0 | () | () |
| bvector | int8 | 1 | (?,) | (False,) |
| brow | int8 | 2 | (1,?) | (True, False) |
| bcol | int8 | 2 | (?,1) | (False, True) |
| bmatrix | int8 | 2 | (?,?) | (False, False) |
| btensor3 | int8 | 3 | (?,?,?) | (False, False, False) |
| btensor4 | int8 | 4 | (?,?,?,?) | (False, False, False, False) |
| btensor5 | int8 | 5 | (?,?,?,?,?) | (False, False, False, False, False) |
| wscalar | int16 | 0 | () | () |
| wvector | int16 | 1 | (?,) | (False,) |
| wrow | int16 | 2 | (1,?) | (True, False) |
| wcol | int16 | 2 | (?,1) | (False, True) |
| wmatrix | int16 | 2 | (?,?) | (False, False) |
| wtensor3 | int16 | 3 | (?,?,?) | (False, False, False) |
| wtensor4 | int16 | 4 | (?,?,?,?) | (False, False, False, False) |
| wtensor5 | int16 | 5 | (?,?,?,?,?) | (False, False, False, False, False) |
| iscalar | int32 | 0 | () | () |
| ivector | int32 | 1 | (?,) | (False,) |
| irow | int32 | 2 | (1,?) | (True, False) |
| icol | int32 | 2 | (?,1) | (False, True) |
| imatrix | int32 | 2 | (?,?) | (False, False) |
| itensor3 | int32 | 3 | (?,?,?) | (False, False, False) |
| itensor4 | int32 | 4 | (?,?,?,?) | (False, False, False, False) |
| itensor5 | int32 | 5 | (?,?,?,?,?) | (False, False, False, False, False) |
| lscalar | int64 | 0 | () | () |
| lvector | int64 | 1 | (?,) | (False,) |
| lrow | int64 | 2 | (1,?) | (True, False) |
| lcol | int64 | 2 | (?,1) | (False, True) |
| lmatrix | int64 | 2 | (?,?) | (False, False) |
| ltensor3 | int64 | 3 | (?,?,?) | (False, False, False) |
| ltensor4 | int64 | 4 | (?,?,?,?) | (False, False, False, False) |
| ltensor5 | int64 | 5 | (?,?,?,?,?) | (False, False, False, False, False) |
| dscalar | float64 | 0 | () | () |
| dvector | float64 | 1 | (?,) | (False,) |
| drow | float64 | 2 | (1,?) | (True, False) |
| dcol | float64 | 2 | (?,1) | (False, True) |
| dmatrix | float64 | 2 | (?,?) | (False, False) |
| dtensor3 | float64 | 3 | (?,?,?) | (False, False, False) |
| dtensor4 | float64 | 4 | (?,?,?,?) | (False, False, False, False) |
| dtensor5 | float64 | 5 | (?,?,?,?,?) | (False, False, False, False, False) |
| fscalar | float32 | 0 | () | () |
| fvector | float32 | 1 | (?,) | (False,) |
| frow | float32 | 2 | (1,?) | (True, False) |
| fcol | float32 | 2 | (?,1) | (False, True) |
| fmatrix | float32 | 2 | (?,?) | (False, False) |
| ftensor3 | float32 | 3 | (?,?,?) | (False, False, False) |
| ftensor4 | float32 | 4 | (?,?,?,?) | (False, False, False, False) |
| ftensor5 | float32 | 5 | (?,?,?,?,?) | (False, False, False, False, False) |
| cscalar | complex64 | 0 | () | () |
| cvector | complex64 | 1 | (?,) | (False,) |
| crow | complex64 | 2 | (1,?) | (True, False) |
| ccol | complex64 | 2 | (?,1) | (False, True) |
| cmatrix | complex64 | 2 | (?,?) | (False, False) |
| ctensor3 | complex64 | 3 | (?,?,?) | (False, False, False) |
| ctensor4 | complex64 | 4 | (?,?,?,?) | (False, False, False, False) |
| ctensor5 | complex64 | 5 | (?,?,?,?,?) | (False, False, False, False, False) |
| zscalar | complex128 | 0 | () | () |
| zvector | complex128 | 1 | (?,) | (False,) |
| zrow | complex128 | 2 | (1,?) | (True, False) |
| zcol | complex128 | 2 | (?,1) | (False, True) |
| zmatrix | complex128 | 2 | (?,?) | (False, False) |
| ztensor3 | complex128 | 3 | (?,?,?) | (False, False, False) |
| ztensor4 | complex128 | 4 | (?,?,?,?) | (False, False, False, False) |
| ztensor5 | complex128 | 5 | (?,?,?,?,?) | (False, False, False, False, False) |
2.2 簡單運算
程式碼如下:
import numpy
import theano.tensor as T
from theano import function
# 1 定義兩個變數,這裡可以是2.1.3表中的任意精度
x = T.dscalar('x')
y = T.dscalar('y')
# 2 表示式
z = x + y
# 3 轉換為python可以執行的函式
f = function([x, y], z)執行結果如下
>>> f(2, 3)
array(5.0)3 實現一個神經網路
3.1 實現網路
這是一個簡單的神經網路,包含:輸入層->隱藏層->輸出層->損失函式
網路模型程式碼如下
#coding=utf-8
import numpy as np
import theano as th
from theano import tensor as T
from numpy import random as rng
class NetEncoder(object):
#在初始化函式中定義自編碼器的引數
def __init__(self, data_x, data_y, hidden_size, actFun, outFun):
self.data_x = data_x
self.data_x = th.shared(name='data_x',
value=np.asarray(self.data_x, dtype=th.config.floatX),
borrow=True)
#print (self.data_x)
self.data_y = data_y
self.data_y = th.shared(name='data_y',
value=np.asarray(self.data_y, dtype=th.config.floatX),
borrow=True)
#print (self.data_y)
self.nIns = data_x.shape[0]
self.nFeatures = data_x.shape[1]
#隱藏層的神經元數量
self.hidden_size = hidden_size
#權值w,初始化取值範圍,在一個固定範圍中取均勻分佈隨機值
raw_w = np.asarray(np.random.normal(0,1,(1,self.hidden_size)),dtype=th.config.floatX)
self.w = th.shared(value=raw_w, name='W',borrow=True)
raw_w2 = np.asarray(np.random.normal(0,1,(self.hidden_size,1)),dtype=th.config.floatX)
self.w2 = th.shared(value=raw_w2, name='W2',borrow=True)
#print(self.w.get_value())
#print(self.w2.get_value())
#隱含層偏置向量
self.b1 = th.shared(name='b1',
value=np.zeros(shape=(1,self.hidden_size),dtype=th.config.floatX),
borrow=True)
#輸出層偏置向量
self.b2 = th.shared(name='b2',
value=np.zeros(shape=(1,1), dtype=th.config.floatX),
borrow=True)
#print(self.b1.get_value())
#print(self.b2.get_value())
#激勵函式
self.actFun = actFun
self.outFun = outFun
# 定義自編碼器的訓練函式
#
def train(self, n_epochs=100, learning_rate=0.1):
#向訓練函式傳遞引數的變數
index = T.lscalar()
#公式內替代值的變數
x = T.dmatrix('x')
y = T.dmatrix('y')
params = [self.w, self.w2, self.b1, self.b2]
#隱藏層
if self.actFun is None :
hidden = T.dot(x,self.w)+self.b1
else:
hidden = self.actFun(T.dot(x,self.w)+self.b1)
#輸出層,這裡於之前演示程式碼不一致的是,這裡沒有用兩個權值矩陣
#這裡使用了同一個矩陣的轉置矩陣
if self.outFun is None:
output = T.dot(hidden,self.w2)+self.b2
else:
output = self.outFun(T.dot(hidden,self.w2)+self.b2)
#損失函式
L = np.square(output - y)
#L = -T.sum(x*T.log(output)+(1-x)*T.log(1-output),axis=1)
loss = L.mean()
updates = []
#梯度下降
gparams = T.grad(loss, params)
for param,gparam in zip(params, gparams):
updates.append((param, param - learning_rate * gparam))
train = th.function(inputs=[index], outputs=[loss],
updates=updates,
givens={x:self.data_x[index:index+1,:],y:self.data_y[index:index+1,:]})
import time
#start_time = time.clock()
for epoch in xrange(n_epochs):
print 'Epoch:', epoch
for row in xrange(0, self.nIns):
train(row)
#end_time = time.clock()
#print "Average time per epoch=", (end_time - start_time)/n_epochs
w = self.w.get_value()
print(w)
w2 = self.w2.get_value()
print(w2)
b1 = self.b1.get_value()
print(b1)
b2 = self.b2.get_value()
print(b2)
def get_output(self, data):
#print(data)
w = self.w.get_value()
w2 = self.w2.get_value()
b1 = self.b1.get_value()
b2 = self.b2.get_value()
x = T.dvector('x')
if self.actFun is None:
hidden = T.dot(x, w)+b1
else:
hidden = self.actFun(T.dot(x, w)+b1)
output = T.dot(hidden,w2)+b2
ae_output = th.function(inputs=[x], outputs=[output])
n = data.shape[0]
testy=[]
for i in xrange(n):
testy.append(ae_output(data[i]))
return np.asarray(testy)3.2 訓練並測試網路
程式碼如下:
#coding=utf-8
import matplotlib.pyplot as plt
import numpy as np
from my_AE_code import NetEncoder
from theano import tensor as T
#隨機生成一份資料
x_data = np.linspace(-1,1,30)[:,np.newaxis]
noise = np.random.normal(0,0.05,x_data.shape)
y_data = np.square(x_data) - 0.5 + noise
#建立網路,並訓練
A = NetEncoder(x_data,y_data,10,T.nnet.softmax,None)
A.train(100)
plt.scatter(x_data, y_data)
testx = np.linspace(-1,1,100)[:,np.newaxis]
testy=A.get_output(testx)
testy = testy.reshape((100,))
testx = testx.reshape((100,))
#print(testx)
#print(testy)
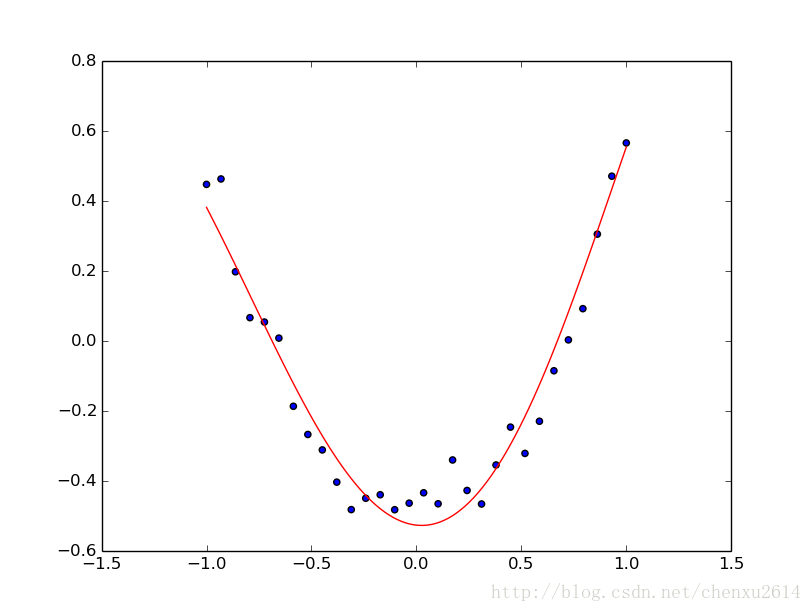
plt.plot(testx,testy, c='r')
plt.show()最終結果如圖所示,藍色的點為訓練資料,紅色線為訓練後對模型的驗證: