
關於C語言中的陣列指標、指標陣列以及二級指標
概念解釋
陣列指標:首先它是一個指標,它指向一個數組,即指向陣列的指標;在32 位系統下永遠是佔4 個位元組,至於它指向的陣列佔多少位元組,不知道。陣列指標指向的是陣列中的一個具體元素,而不是整個陣列,所以陣列指標的型別和陣列元素的型別有關。
指標陣列:首先它是一個數組,陣列的元素都是指標,陣列佔多少個位元組由陣列本身決定。它是“儲存指標的陣列”的簡稱,即每個元素都是指標。
二級指標 : 如果一個指標指向的是另外一個指標,我們就稱它為二級指標,或者指向指標的指標。
例項解釋
判斷哪個為指標陣列哪個為陣列指標?
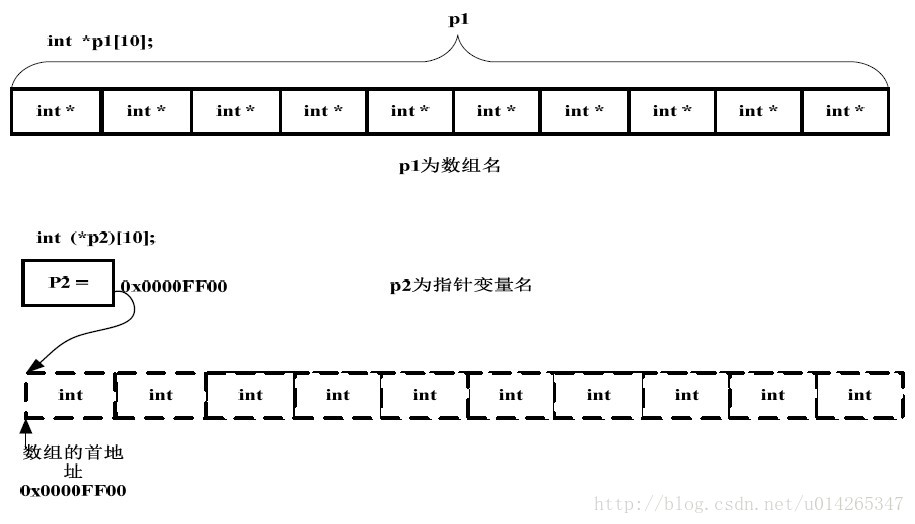
int *p1[10];
int (*p2)[10];解析
- “[]”的優先順序比“”要高。p1 先與“[]”結合,構成一個數組的定義,陣列名為p1,int 修飾的是陣列的內容,即陣列的每個元素.因此這是一個數組,其包含10 個指向int 型別資料的指標,即指標陣列
- “()”的優先順序比“[]”高,“*”號和p2 構成一個指標的定義,指標變數名為p2,int 修飾的是陣列的內容,即陣列的每個元素。陣列在這裡並沒有名字,是個匿名陣列。因此p2 是一個指標,它指向一個包含10 個int 型別資料的陣列,即陣列指標
關於p2的定義問題
平時我們定義指標不都是在資料型別後面加上指標變數名麼?這個指標p2 的定義怎麼不是按照這個語法來定義的呢?也許我們應該這樣來定義p2:
int (*)[10] p2;
int (*)[10]是指標型別,p2 是指標變數。這樣看起來的確不錯,不過就是樣子有些彆扭。其實陣列指標的原型確實就是這樣子的,只不過為了方便與好看把指標變數p2 前移了而已。
利用指標遍歷陣列元素
#include <stdio.h>
#include<iostream>
using namespace std;
int main()
{
int arr[] = { 1, 3, 5, 7, 9};
int len = sizeof(arr) / sizeof(int); //求陣列長度
int i;
for(i=0; i<len; i++)
{
printf("%d ", *(arr+i) ); //*(arr+i)等價於arr[i]
}
printf("\n" - (arr+i)這個表示式,arr 是陣列名,指向陣列的第 0 個元素,表示陣列首地址, arr+i 指向陣列的第 i 個元素,(arr+i) 表示取第 i 個元素的資料,它等價於 arr[i]。其中arr 是int*型別的指標,每次加 1 時它自身的值會增加 sizeof(int),加 i 時自身的值會增加 sizeof(int) * i
- 還可以如此表示
int arr[] = { 1, 3, 5, 7, 9};
int *p = arr;arr 是陣列第 0 個元素的地址,所以int *p = arr;也可以寫作int *p = &arr[0];。也就是說,arr、p、&arr[0] 這三種寫法都是等價的,它們都指向陣列第 0 個元素,或者說指向陣列的開頭。
利用陣列指標遍歷陣列
#include <stdio.h>
#include<iostream>
using namespace std;
int main()
{
int arr[] = { 1, 3, 5, 7, 9};
int len = sizeof(arr) / sizeof(int); //求陣列長度
int i, *p = arr;
for(i=0; i<len; i++)
{
printf("%d ", *(p+i) );
}
printf("\n");
return 0;
}
- 陣列在記憶體中只是陣列元素的簡單排列,沒有開始和結束標誌,在求陣列的長度時不能使用sizeof(p) / sizeof(int),因為 p 只是一個指向 int 型別的指標,編譯器並不知道它指向的到底是一個整數還是一系列整數(陣列),所以 sizeof(p) 求得的是 p 這個指標變數本身所佔用的位元組數,而不是整個陣列佔用的位元組數。
- 根據陣列指標不能逆推出整個陣列元素的個數,以及陣列從哪裡開始、到哪裡結束等資訊。不像字串,陣列本身也沒有特定的結束標誌,如果不知道陣列的長度,那麼就無法遍歷整個陣列。
- 對指標變數進行加法和減法運算時,是根據資料型別的長度來計算的。如果一個指標變數 p 指向了陣列的開頭,那麼 p+i 就指向陣列的第 i 個元素;如果 p 指向了陣列的第 n 個元素,那麼 p+i 就是指向第 n+i 個元素;而不管 p 指向了陣列的第幾個元素,p+1 總是指向下一個元素,p-1 也總是指向上一個元素
更改上面的程式碼,讓 p 指向陣列中的第二個元素:
#include <stdio.h>
#include<iostream>
using namespace std;
int main()
{
int arr[] = { 1, 3, 5, 7, 9};
int *p = &arr[2]; //也可以寫作 int *p = arr + 2;
printf("%d, %d, %d, %d, %d\n", *(p-2), *(p-1), *p, *(p+1), *(p+2) );
return 0;
}會發現結果和上面的一致
總結
引入陣列指標後,我們就有兩種方案來訪問陣列元素了,一種是使用下標,另外一種是使用指標。
1. 使用下標
也就是採用 arr[i] 的形式訪問陣列元素。如果 p 是指向陣列 arr 的指標,那麼也可以使用 p[i] 來訪問陣列元素,它等價於 arr[i]。
2. 使用指標
也就是使用 (p+i) 的形式訪問陣列元素。另外陣列名本身也是指標,也可以使用 (arr+i) 來訪問陣列元素,它等價於 *(p+i)。
不管是陣列名還是陣列指標,都可以使用上面的兩種方式來訪問陣列元素。不同的是,陣列名是常量,它的值不能改變,而陣列指標是變數(除非特別指明它是常量),它的值可以任意改變。也就是說,陣列名只能指向陣列的開頭,而陣列指標可以先指向陣列開頭,再指向其他元素。
藉助自增運算子來遍歷陣列元素
#include <stdio.h>
#include<iostream>
using namespace std;
int main()
{
int arr[] = { 1, 3, 5, 7, 9};
int i, *p = arr, len = sizeof(arr) / sizeof(int);
for(i=0; i<len; i++)
{
printf("%d ", *p++ );
}
printf("\n");
return 0;
}解釋
p++ 應該理解為 (p++),每次迴圈都會改變 p 的值(p++ 使得 p 自身的值增加),以使 p 指向下一個陣列元素。該語句不能寫為 *arr++,因為 arr 是常量,而 arr++ 會改變它的值,這顯然是錯誤的
關於陣列指標的幾個問題
假設 p 是指向陣列 arr 中第 n 個元素的指標,那麼 p++、++p、(*p)++ 分別是什麼意思呢?
1. *p++上面已經敘述
2. ++p 等價於 (++p),會先進行 ++p 運算,使得 p 的值增加,指向下一個元素,整體上相當於 *(p+1),所以會獲得第 n+1 個數組元素的值
3. (*p)++ 會先取得第 n 個元素的值,再對該元素的值加 1。假設 p 指向第 0 個元素,並且第 0 個元素的值為 1,執行完該語句後,第 0 個元素的值就會變為 2
例項中的指標陣列和二級指標
#include <stdio.h>
#include<iostream>
using namespace std;
int main()
{
int a = 1, b = 2, c = 3;
//定義一個指標陣列
int *arr[3] = {&a, &b, &c};//也可以不指定長度,直接寫作 int *parr[]
//定義一個指向指標陣列的指標,即二級指標
int **parr = arr;
printf("%d, %d, %d\n", *arr[0], *arr[1], *arr[2]);
printf("%d, %d, %d\n", **(parr+0), **(parr+1), **(parr+2));
return 0;
}
- arr 是一個指標陣列,它包含了 3 個元素,每個元素都是一個指標,在定義 arr 的同時,我們使用變數 a、b、c 的地址對它進行了初始化,這和普通陣列很類似。
- parr 是指向陣列 arr 的指標,確切地說是指向 arr 第 0 個元素的指標,它的定義形式應該理解為int (*parr),括號中的表示 parr 是一個指標,括號外面的int 表示 parr 指向的資料的型別。arr 第 0 個元素的型別為 int ,所以在定義 parr 時要加兩個 *,即可稱parr為二級指標,或者指向指標的指標。
#include <stdio.h>
#include<iostream>
using namespace std;
int main()
{
char *lines[5] =
{
"COSC1283/1984",
"Programming",
"Techniques",
"is",
"great fun"
};
char *str1 = lines[1];
char *str2 = *(lines + 3);
char c1 = *(*(lines + 4) + 6);
char c2 = (*lines + 5)[5];
char c3 = *lines[0] + 2;
printf("str1 = %s\n", str1);
printf("str2 = %s\n", str2);
printf(" c1 = %c\n", c1);
printf(" c2 = %c\n", c2);
printf(" c3 = %c\n", c3);
return 0;
}
執行結果
str1 = Programming
str2 = is
c1 = f
c2 = 9
c3 = E為了更加直觀,將上述程式碼改成下面的形式
#include <stdio.h>
#include<iostream>
using namespace std;
int main()
{
char *string0 = "COSC1283/1984";
char *string1 = "Programming";
char *string2 = "Techniques";
char *string3 = "is";
char *string4 = "great fun";
char *lines[5];
lines[0] = string0;
lines[1] = string1;
lines[2] = string2;
lines[3] = string3;
lines[4] = string4;
char *str1 = lines[1];
char *str2 = *(lines + 3);
char c1 = *(*(lines + 4) + 6);
char c2 = (*lines + 5)[5];
char c3 = *lines[0] + 2;
printf("str1 = %s\n", str1);
printf("str2 = %s\n", str2);
printf(" c1 = %c\n", c1);
printf(" c2 = %c\n", c2);
printf(" c3 = %c\n", c3);
return 0;
}
1. char *lines[5]; 定義了一個指標陣列,陣列的每一個元素都是指向char型別的指標。最後5行,為陣列的每一個元素賦值,都是直接賦給指標。
2. 而lines,是一個指向指標的指標,它的型別為 char **,所以 *lines 是一個指向字元的指標,**lines是一個具體的字元。這一點很重要,一定要明白。
3. 指標是可以進行運算的,lines 為lines[5]陣列的首地址,即第0個元素的地址;lines+0, lines+1, lines+2 ... 分別是第0, 1, 2 ...個元素的首地址,*(lines+0)或lines[0], *(lines+1)或lines[1], *(lines+2)或lines[2] ... 分別是字串 str0, str1, str2 ... 的首地址。所以:
*lines == *(lines+0) == lines[0] == str0
*(lines+1) == lines[1] == str1
*(lines+2) == lines[2] == str2注意
lines為指向指標的指標,所以* (lines+n)為指標,**(lines+n)才為具體的字元。
解析
1. lines[1]:它是一個指標,指向字串string1,即string1的首地址。
2. *(lines + 3):lines + 3 為lines[5]陣列第3個元素的地址, *(lines + 3)為第3個元素,它是一個指標,指向字串string3。
3. *(*(lines + 4) + 6):*(lines + 4) + 6 == lines[4] + 6 == string4 + 6,為字串string4第6個字元的地址,即 f 的地址,*(*(lines + 4) + 6) 就表示字元 f。
4. (*lines + 5)[5]:*lines + 5 為字串 string0 第5個字元的地址,即 2 的地址,(*lines + 5)[5]等價於*(*lines + 5 + 5),表示第10個字元,即9。
5. *lines[0] + 2:*lines[0] 為字串string0 第0個字元的地址,即C的地址。字元與整數運算,首先轉換為該字元對應的ASCII碼值,然後再運算,所以 *lines[0] + 2 = 67 + 2 = 69。不過要求輸出字元,所以還要轉換成69所對應的字元,即E。輸入5個國名並按字母順序排列後輸出
#include<stdio.h>
#include<iostream>
using namespace std;
void sort(char *name[],int n)
{
char *pt;
int i,j,k;
for(i=0;i<n-1;i++)
{
k=i;
for(j=i+1;j<n;j++)
if(strcmp(name[k],name[j])>0)
k=j;
if(k!=i)
{
pt=name[i];
name[i]=name[k];
name[k]=pt;
}
}
}
void print(char *name[],int n)
{
int i;
for (i=0;i<n;i++)
printf("%s\n",name[i]);
}
int main()
{
static char *name[]={ "CHINA","AMERICA","AUSTRALIA","FRANCE","GERMAN"};
int n=5;
sort(name,n);
print(name,n);
return 0;
}
說明:
1. 在以前的例子中採用了普通的排序方法,逐個比較之後交換字串的位置。交換字串的物理位置是通過字串複製函式完成的。反覆的交換將使程式執行的速度很慢,同時由於各字串(國名)的長度不同,又增加了儲存管理的負擔。用指標陣列能很好地解決這些問題。把所有的字串存放在一個數組中,把這些字元陣列的首地址放在一個指標陣列中,當需要交換兩個字串時,只須交換指標陣列相應兩元素的內容(地址)即可,而不必交換字串本身。
2. 本程式定義了兩個函式,一個名為sort完成排序,其形參為指標陣列name,即為待排序的各字串陣列的指標。形參n為字串的個數。另一個函式名為print,用於排序後字串的輸出,其形參與sort的形參相同。主函式main中,定義了指標陣列name 並作了初始化賦值。然後分別呼叫sort函式和print函式完成排序和輸出。值得說明的是在sort函式中,對兩個字串比較,採用了strcmp函式,strcmp函式允許參與比較的字串以指標方式出現。name[k]和name[j]均為指標,因此是合法的。字串比較後需要交換時,只交換指標陣列元素的值,而不交換具體的字串,這樣將大大減少時間的開銷,提高了執行效率。
3. 這題用algorithm中的sort()也可以很好的解決。
後記
該文件整理於C語言中文網的部分資料,通過這樣的梳理對C語言指標的理解更加深了一步