
泰坦尼克號資料探勘專案實戰——Task1 資料分析
參考資料:https://www.bilibili.com/video/av27536643
https://blog.csdn.net/aaronjny/article/details/79735998
https://github.com/AaronJny/simple_titanic
https://zhuanlan.zhihu.com/p/30538352
https://www.jianshu.com/p/9a5bce0de13f
1. 檢視資料集
import pandas as pd # 讀取資料集 train_data = pd.read_csv('Data/train.csv') test_data = pd.read_csv('Data/test.csv') # 列印資訊 train_data.info()

以上特徵含義為:
- PassengerId 乘客編號
- Survived 是否倖存
- Pclass 船票等級
- Name 乘客姓名
- Sex 乘客性別
- SibSp、Parch 親戚數量
- Ticket 船票號碼
- Fare 船票價格
- Cabin 船艙
- Embarked 登入港口
2. 特徵選擇
根據經驗,認為乘客編號、乘客姓名、船票號碼、船艙跟逃生機率無關,所以初步選擇 ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked'] 作為訓練特徵。從打印出來的資料可以發現,序號是891個,但是並不是所有的特徵都滿足891,所以某些特徵存在缺失值。
# 選擇用於訓練的特徵
features = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
x_train = train_data[features]
x_test = test_data[features]
y_train=train_data['Survived']
# 檢查缺失值
x_train.info()
print('-'*100)
x_test.info()

3. 特徵缺失值處理
所以我們發現,訓練資料中的Age,Embarked,測試資料 Age,Fare,Embarked。送入模型中的標籤和特徵要可以一一對應,所以要麼丟掉特徵不完整的樣本,要麼填充。秉著儘可能使用樣本的態度,我們選擇填充特徵。
如何補全資料集呢?最簡單的方法:對於數值型資料,可以使用其平均值/中位數填補空值,儘量減小填補值對結果的影響。對於類別資料,可以使用眾數來填補。稍微進階一些的,可以藉助其他輔助特徵:例如測試資料中Fare缺失的資料,每個乘客的Ticket是唯一的,無法通過查詢相同的票號加個來填補,但是,船票價格往往跟 Pclass (客艙等級)及 Cabin(客艙號)有關的,因此使用具有相同Pclass和Cabin的中位數或著眾數來填補。
這裡先採用最簡單的方法進行填補。
# 使用平均年齡來填充年齡中的nan值
x_train['Age'].fillna(x_train['Age'].mean(), inplace=True)
x_test['Age'].fillna(x_test['Age'].mean(),inplace=True)
# 使用票價的均值填充票價中的nan值
x_test['Fare'].fillna(x_test['Fare'].mean(),inplace=True)
# 使用登入最多的港口來填充登入港口的nan值
print x_train['Embarked'].value_counts()
x_train['Embarked'].fillna('S', inplace=True)
x_test['Embarked'].fillna('S',inplace=True)4. 特徵值轉換為特徵向量
機器學習中,送入模型的是矩陣,而上述特徵中並不是所有的特徵都是數值型的,需要把一些非數值型的特徵轉為數值。例如性別,我們可以簡單的想到“0”,“1”來代表,那麼“Embarked”的"C","Q","S" 要選擇用“0”,“1”,“2”來代替嗎?若兩個特徵之間的距離是,d(C, Q) = 1, d(Q, S) = 1, d(C, S) = 2。那麼C和S工作之間就越不相似嗎?顯然這樣的表示,計算出來的特徵的距離是不合理。那如果使用one-hot編碼,則得到C = (1, 0, 0), Q= (0, 1, 0), S = (0, 0, 1),那麼兩個工作之間的距離就都是sqrt(2).即每兩個特徵之間的距離是一樣的,顯得更合理。因此,我們使用 one-hot編碼。
# 將特徵值轉換成特徵向量
dvec=DictVectorizer(sparse=False)
x_train=dvec.fit_transform(x_train.to_dict(orient='record'))
x_test=dvec.transform(x_test.to_dict(orient='record'))
# 列印特徵向量格式
print (dvec.feature_names_)因此,將特徵值轉換為特徵向量後的格式:
![]()
例如列印一條資料,具體內容:
print (x_train[100])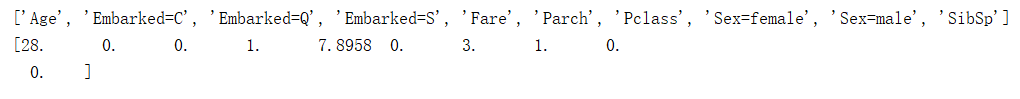
特徵向量的值與上面的名稱一一對應。